Esta guía explicará la validación cruzada y su funcionamiento con el servicio de AWS.
¿Qué es la validación cruzada?
La validación cruzada permite a los desarrolladores comparar diferentes modelos de aprendizaje automático y tener una idea de su funcionamiento en la vida real. Ayuda al usuario a determinar qué modelo de Machine Learning (ML) o Deep Learning (DL) funcionará mejor para un dato o escenario en particular. Hay situaciones en las que se pueden usar varios modelos para un conjunto de datos, aquí los desarrolladores usan la validación cruzada para obtener un modelo adecuado y obtener resultados optimizados:
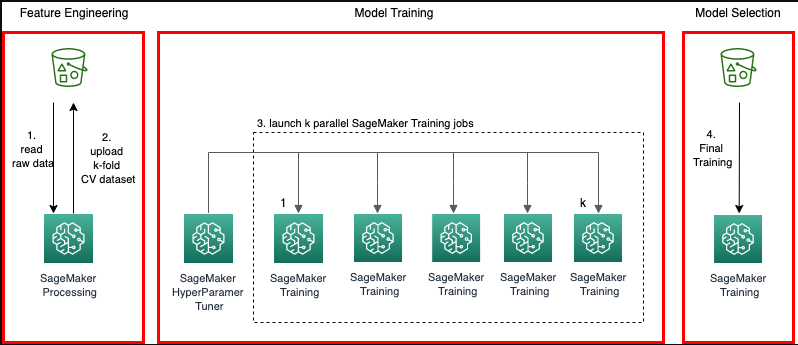
¿Cómo funciona la validación cruzada?
Para verificar los modelos ML en un conjunto de datos, el usuario debe estimar las características del modelo, lo que se denomina entrenamiento del algoritmo. Otra cosa a comprobar es la evaluación del modelo para saber qué tan bien se desempeñó y se llama prueba del modelo. No es una buena idea probar el modelo en todos los datos; sin embargo, usamos el 75 % de los datos para entrenamiento y el 25 % para pruebas para obtener mejores resultados. La validación cruzada realiza pruebas en cada 25 % de los datos para verificar qué bloque funciona mejor:
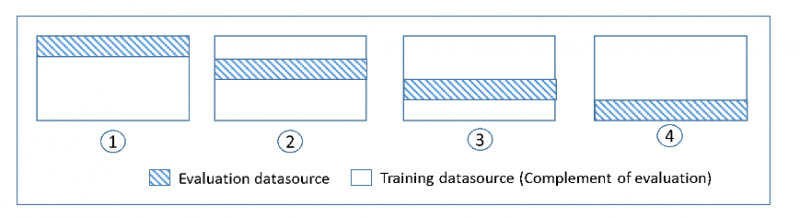
¿Qué es Amazon SageMaker?
La validación cruzada en AWS se puede realizar mediante el servicio Amazon SageMaker, ya que está diseñado para crear, entrenar e implementar modelos de aprendizaje automático. Ayuda a los científicos y desarrolladores de datos a preparar datos para crear modelos ML o DL eficientes al reunir capacidades especialmente diseñadas. Estas capacidades son útiles para construir modelos optimizados y precisos que tendrán la capacidad de mejorar con el tiempo:

Características de Amazon SageMaker
Amazon SageMaker es un servicio administrado y no requiere la administración de entornos de ML. Necesita una gran cantidad de datos para entrenar y crear modelos de ML, por lo que se conecta bien con los servicios de Amazon S3 o Amazon Redshift para recopilar datos. Puede ser difícil obtener información de los datos sin procesar, por lo que también requieren características para construir modelos. Luego use los datos para entrenar modelos y luego realice pruebas usando cada 25% de los datos para obtener mejores resultados/predicciones:
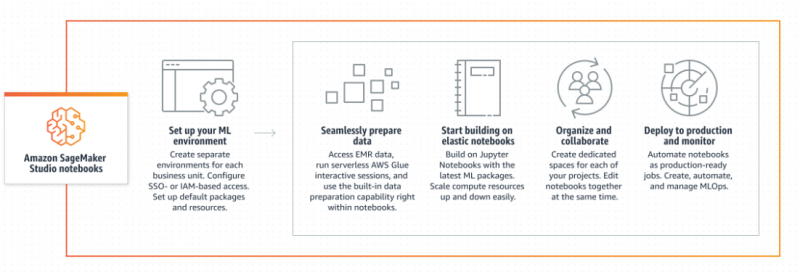
De eso se trata la validación cruzada en AWS.
Conclusión
La validación cruzada es el proceso de obtener el modelo óptimo de aprendizaje automático o aprendizaje profundo para que los datos obtengan mejores resultados. Realizará pruebas para cada sección del 25% de los datos para comprender qué bloque proporciona el máximo rendimiento, lo que lo convierte en un modelo de ajuste apropiado. AWS proporciona el servicio SageMaker para realizar una validación cruzada y crear modelos de aprendizaje automático en la nube. Esta guía ha explicado el proceso de validación cruzada y su funcionamiento en AWS.