Quilla (Extracción de conocimiento basada en aprendizaje evolutivo) es una herramienta de software basada en Java que se especializa en la implementación de algoritmos evolutivos. Dado que es un código abierto, proporciona una amplia variedad de algoritmos de descubrimiento de conocimiento que se pueden utilizar en experimentos que potencian la comunidad de análisis y minería de datos. Proporciona una interfaz gráfica de usuario simple y fácil de usar que reduce significativamente la complejidad general de esta herramienta. La mayoría de las herramientas similares en el mercado requieren que los usuarios interactúen con ellas escribiendo el código, mientras que Keel elimina este requisito al proporcionar una GUI intuitiva que pueden usar tanto principiantes como expertos.
Keel proporciona una amplia variedad de diferentes algoritmos basados en inteligencia computacional que incluyen clasificación, regresión, extracción de características, análisis de patrones, agrupamiento y más. Con los modelos convencionales integrados directamente en la propia aplicación, Keel es una herramienta muy útil cuando se trata de realizar análisis de datos exploratorios en conjuntos de datos sin procesar. Su sencilla interfaz de arrastrar y soltar junto con la facilidad de uso de la funcionalidad permite una experimentación de minería de datos rápida y eficiente con fines educativos y de investigación. Herramientas como Keel están ganando popularidad debido a su enfoque simplista de prácticas algorítmicas complejas.
Instalación
Hay dos formas principales en las que podemos instalar Quilla en cualquier máquina Linux. La primera consiste en ir al página web de la quilla y descargar el software desde allí. El segundo, que seguiremos en esta guía de instalación, requiere que descarguemos Keel usando el wget herramienta de descarga disponible para usuarios de Linux.
1. Empezamos por obtener wget en nuestra máquina Linux.
Ejecute el siguiente comando para descargar el wget usando el apto gerente de empaquetación:
$ sudo apt-get install wget
Verá una salida de terminal similar:
2. Ahora que tenemos el wget herramienta instalada en nuestra máquina Linux, la usamos para descargar el Quilla herramienta.
Este es el Enlace que pasamos a wget.
Ejecute el siguiente comando en su terminal:
$ wget http: // sci2s.ugr.es / quilla / software / prototipos / versión abierta / Software- 2018 -04-09.zip
Debería ver un resultado similar en su terminal:
Una vez que Keel termine de descargarse, podemos continuar con el resto de la instalación.
3. Ahora extraemos el archivo comprimido que descargamos en el paso anterior usando la herramienta Linux Unzip.
Ejecute el siguiente comando:
$ abrir la cremallera Software- 2018 -04-09.zip
Debería ver una salida similar en la terminal:
4. Navegue a la carpeta Keel ejecutando el siguiente comando:
$ discos compactos Software- 2018 -04-09 / Documentos / Experimentos / QUILLA / dist /
5. Ejecute el siguiente comando para comenzar con la instalación:
$ Java -frasco . / GraphInterKeel.jar
Con esto, Keel debería estar disponible para que lo use en su máquina Linux.
Guía del usuario
Interactuando con el Quilla La aplicación es realmente fácil y simple. Comencemos por importar el Conjunto de datos de iris a nuestro espacio de trabajo.
A medida que importamos los datos, la herramienta nos muestra la agrupación general del punto de datos en el conjunto de datos. También nos muestra las diferentes clases que están presentes en el conjunto de datos junto con la información básica como los rangos numéricos que abarcan estos puntos de datos y la varianza general y los valores medios que presenta. Esta información permite a los usuarios comprender mejor cómo proceder con la preparación de datos para cualquier tipo de tarea de análisis de datos.
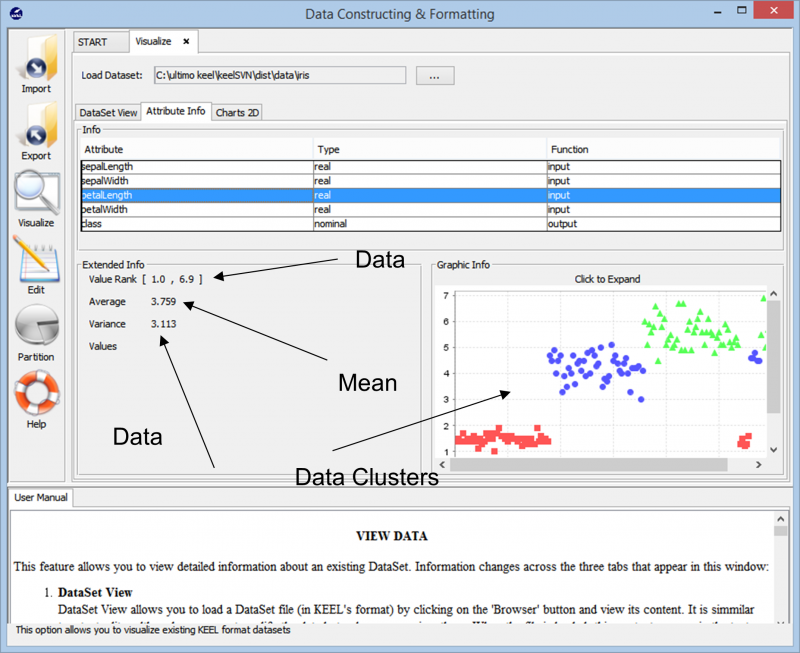
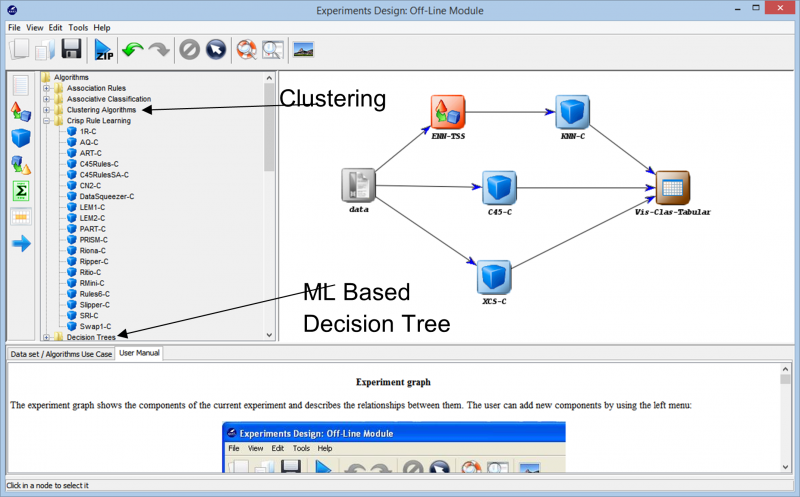
Avanzando más en la experimentación, nos encontramos con las diferentes técnicas que se pueden usar para crear nuestro experimento en cualquier conjunto de datos. Los diferentes algoritmos de aprendizaje que se pueden utilizar sobre nuestros datos se pueden ver en la siguiente imagen. Según la naturaleza del conjunto de datos y los requisitos del experimento, se pueden experimentar con diferentes algoritmos.
Por ejemplo, si está trabajando con datos sin etiquetar y tiene que encontrar similitudes entre los diferentes puntos de datos en su conjunto de datos, usar un algoritmo de agrupamiento de las diferentes opciones disponibles puede ayudarlo a comprender mejor los puntos de datos. Esto finalmente lo ayuda a etiquetar y clasificar los puntos de datos para que el experimento se pueda desarrollar utilizando algoritmos de aprendizaje supervisado más completos.
Conclusión
los Quilla La plataforma para el análisis de datos es un buen recurso tanto para fines educativos como de investigación. Su interfaz gráfica de usuario fácil de usar ayuda a los usuarios a comprender mejor los requisitos de los datos y proporciona referencias lógicas a técnicas y algoritmos útiles que ayudan aún más a los usuarios en sus flujos de trabajo. Tener una amplia gama de algoritmos diferentes que se incluyen en las diferentes categorías y técnicas algorítmicas permite a los usuarios experimentar con numerosas direcciones lógicas y comparar estos resultados para que se pueda alcanzar la solución más óptima para cualquier problema.
El enfoque de arrastrar y soltar sin código de Keel para la minería de datos ayuda incluso a los principiantes a trabajar sin esfuerzo con modelos integrales de inteligencia computacional. Esto proporciona información sobre conjuntos de datos complejos y, en consecuencia, deriva inferencias útiles que ayudan a resolver los problemas del mundo real.