“Valores separados por comas (CSV) es uno de los formatos de datos más versátiles y fáciles de usar. Es un formato de datos liviano que permite a los desarrolladores y aplicaciones transferir y analizar datos de una fuente a otra.
Los datos CSV almacenan datos en un formato tabular donde cada columna está separada por una coma y se asigna un nuevo registro a una nueva línea. Esto lo convierte en una muy buena opción para exportar bases de datos como bases de datos SQL, datos de Cassandra y más.
Por lo tanto, no sorprende que se encuentre con un escenario en el que necesite importar un archivo CSV a su base de datos.
El objetivo de este tutorial es mostrarle un método rápido y sencillo para importar un archivo CSV a su clúster de Elasticsearch mediante el panel de control de Kibana”.
Saltemos.
Requisitos
Antes de sumergirse, asegúrese de tener los siguientes requisitos:
- Un clúster de Elasticsearch con estado de salud verde.
- Servidor Kibana conectado a su clúster de Elasticsearch.
- Permisos suficientes para administrar índices en su clúster.
Archivo CSV de muestra
Como de costumbre, el primer requisito es su archivo CSV de origen. Es bueno asegurarse de que los datos en su archivo CSV estén bien formateados y que no contengan errores.
Con fines ilustrativos, utilizaremos un conjunto de datos gratuito que contiene películas y programas de televisión de Amazon Prime.
Abra su navegador y navegue hasta el siguiente recurso:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Siga el procedimiento para descargar el conjunto de datos a su máquina local. Puede extraer el archivo descargado con el comando:
$ abrir la cremallera un ~ / Descargas / rchive.zip
Importar archivo CSV
Una vez que tenga listo su archivo fuente, podemos continuar y discutir cómo importarlo.
Comience dirigiéndose a su panel de inicio de Kibana y seleccionando la opción 'cargar un archivo'.
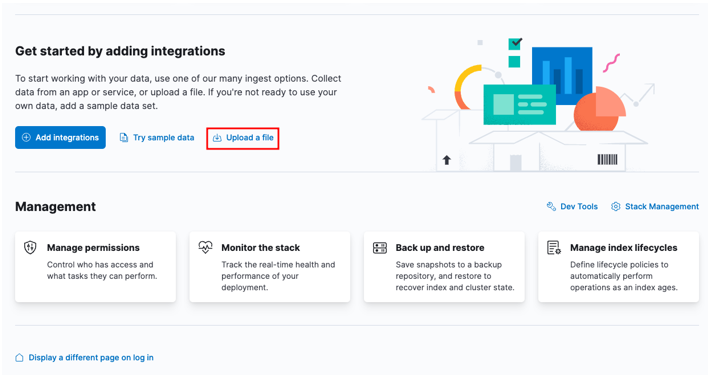
Localice el archivo CSV de destino que desea importar en la ventana del iniciador.
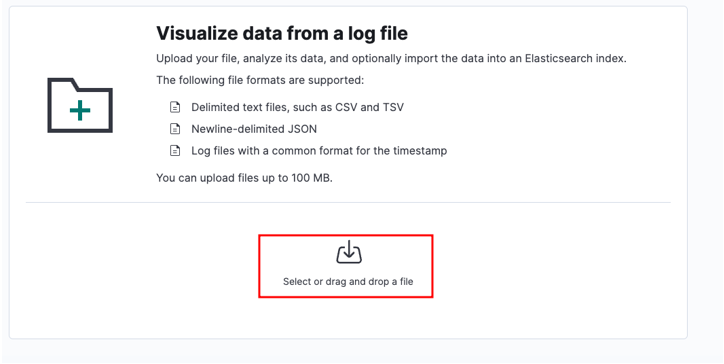
Seleccione su archivo fuente y haga clic en cargar.
Permita que Elasticsearch y Kibana analicen el archivo cargado. Esto analizará el archivo CSV y determinará el formato de datos, campos, tipos de datos, etc.
NOTA: Según la configuración de su clúster y el tamaño de los datos, este proceso puede demorar un tiempo. Asegúrese de que el nodo principal responda para evitar tiempos de espera.
Una vez que se completa el proceso, debe obtener una muestra del contenido de su archivo y las estadísticas del archivo analizadas por Elastic.
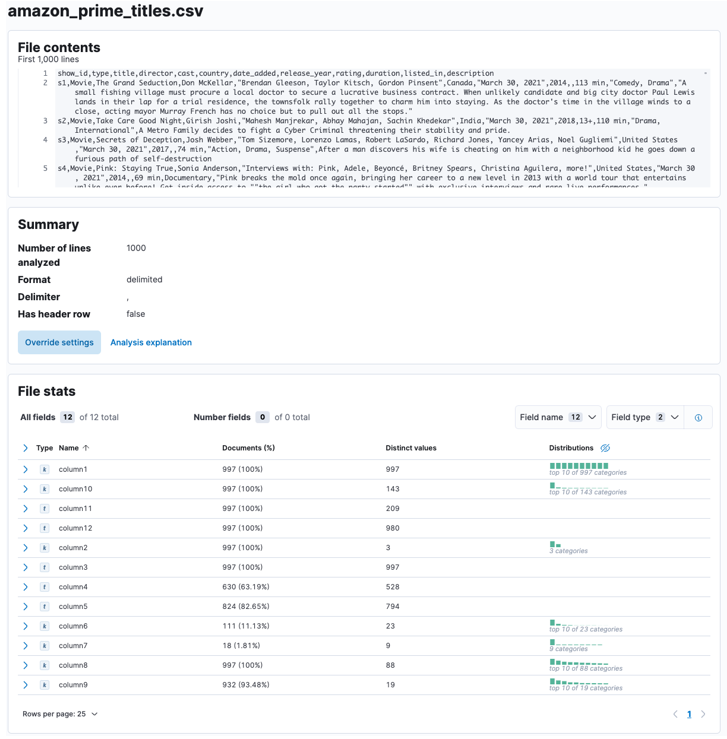
Puede personalizar numerosos parámetros, por ejemplo, el delimitador, las filas de encabezado, etc. Por ejemplo, podemos personalizar el resultado anterior para decirle a Elastic que nuestro archivo CSV contiene archivos de encabezado.
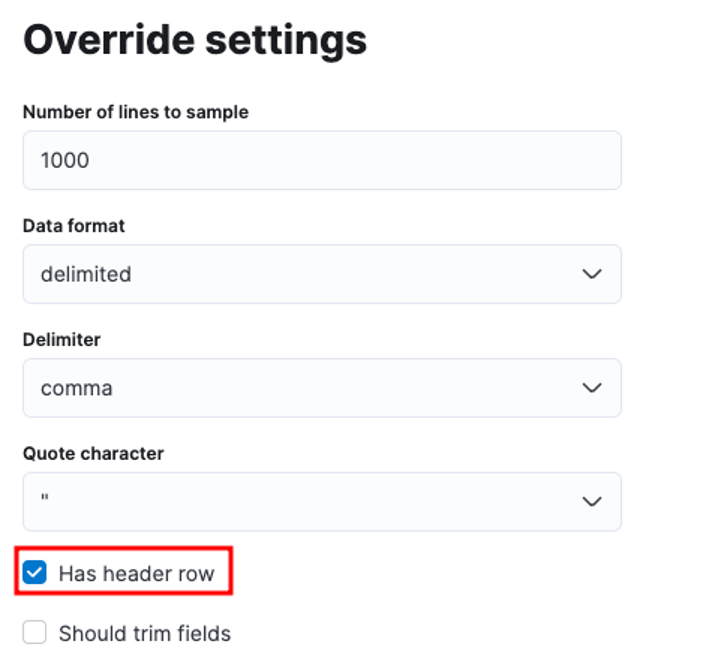
Luego podemos hacer clic en aplicar y volver a analizar los datos. Esto debería formatear los datos en el formato correcto, incluidos los campos.
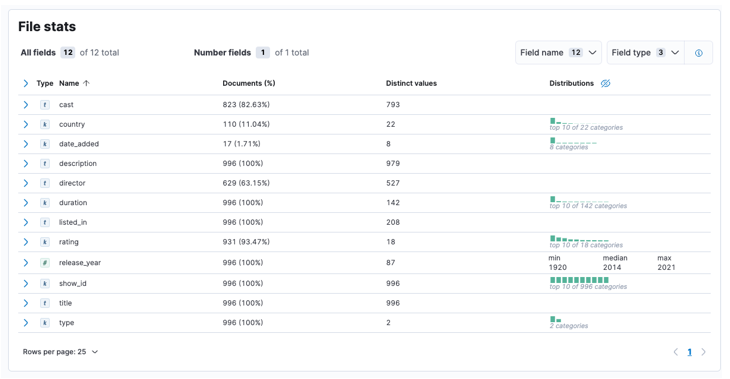
A continuación, podemos hacer clic en importar para pasar al panel importado.
Aquí, necesitamos crear un índice en el que se almacenen los datos CSV. Puede asignar cualquier nombre admitido a su índice.
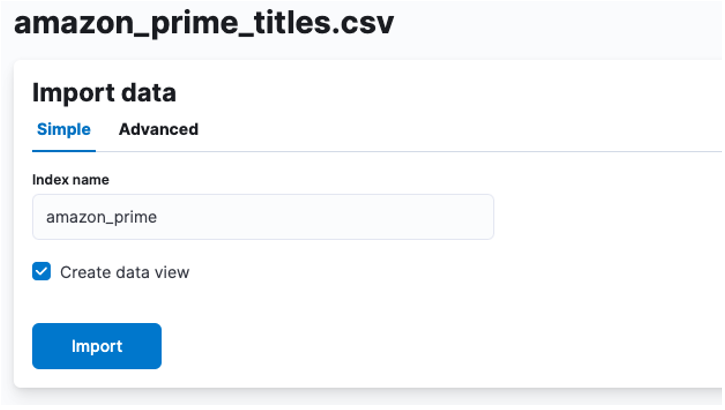
Si desea personalizar las propiedades de su índice, como la cantidad de fragmentos, réplicas, asignaciones, etc. Seleccione la opción avanzada y modifique su configuración como desee.
Finalmente, haga clic en importar y observe cómo Kibana hace su 'magia'. Una vez completado, puede acceder a su índice a través de la API de Elasticsearch o usar el panel de control de Kibana.
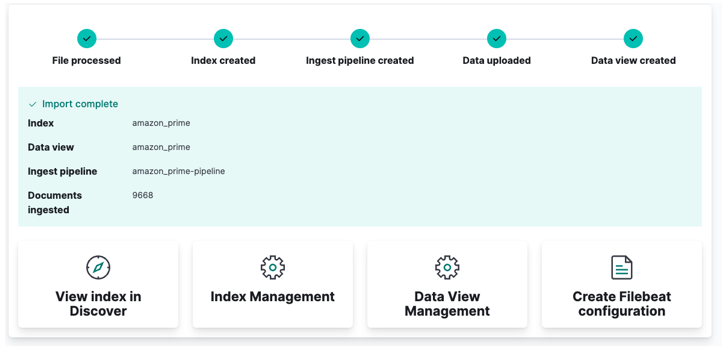
¡¡Y listo!!
Conclusión
En esta publicación, cubrimos el proceso de obtención e importación de su conjunto de datos CSV en su clúster de Elasticsearch mediante el panel de control de Kibana.
¡Gracias por leer y feliz codificación!