Este artículo proporciona una demostración paso a paso para descargar e instalar el controlador JDBC de Amazon Redshift, versión 2.1.
¿Cómo descargar el controlador JDBC de Amazon Redshift, versión 2.1?
AWS proporciona servicios en la nube a empresas que les permiten almacenar su enorme cantidad de datos sin la molestia de administrarlos y brindarles seguridad. AWS Redshift JDBC es otra característica y servicio ofrecido por AWS que permite a las grandes empresas almacenar sus enormes volúmenes de datos, de hasta petabytes.
Amazon Redshift ha facilitado el análisis de datos y la generación de información sobre ellos, pero no proporciona ninguna plataforma donde se puedan realizar estas operaciones.
Aquí, en este artículo, proporcionaremos un procedimiento paso a paso para utilizar el controlador JDBC:
Requisito previo: instalar JAVA y Workbench
AWS proporciona un controlador que puede conectar a otras herramientas de terceros, como My SQL Workbench, Eclipse, JAVA, etc., para extraer información significativa sobre los datos.
- Visita el sitio web oficial de JAVA-RE . Desplácese hacia abajo y haga clic en ' ventanas ' pestaña. Desde allí, haga clic en el enlace de descarga para comenzar a descargar su JAVA RE.
- A continuación, visite el sitio web oficial de Banco de trabajo SQL . Desplácese hacia abajo hasta la sección Enlaces de descarga y haga clic en el enlace. Cuando se descarga el instalador. Dentro del instalador, abra la interfaz de SQL Workbench.
Aquí, se descargan todos los requisitos previos, ahora cree Redshift y descargue un controlador para la conectividad:
Paso 1: Desplazamiento al rojo de Amazon
En la barra de búsqueda de Amazon, escriba y busque ' Desplazamiento al rojo del Amazonas ” y haga clic en el resultado similar al siguiente resultado resaltado:
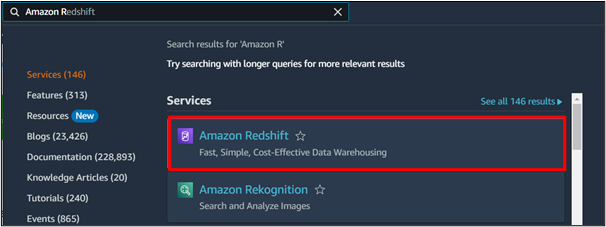
Paso 2: crear un clúster
Desde el panel de AWS Redshift, haga clic en ' Crear cluster ' botón:
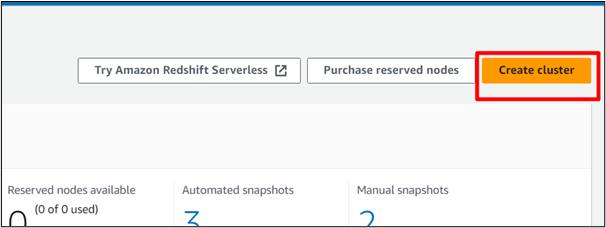
Paso 3: especificar el nombre del clúster
En el ' Identificador de clúster ”, proporcione un nombre para el clúster de su preferencia. El resto de configuraciones seguirán siendo las mismas:
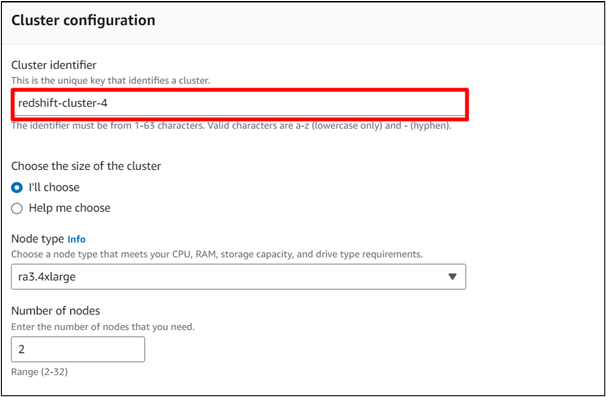
Paso 4: cargar datos
Si desea que su clúster tenga datos ficticios predefinidos, puede marcar la casilla ' Cargar datos de muestra ” opción :

Paso 5: escriba la contraseña
Proporcione una contraseña para su clúster. Esto se utilizará al conectarse al banco de trabajo SQL:
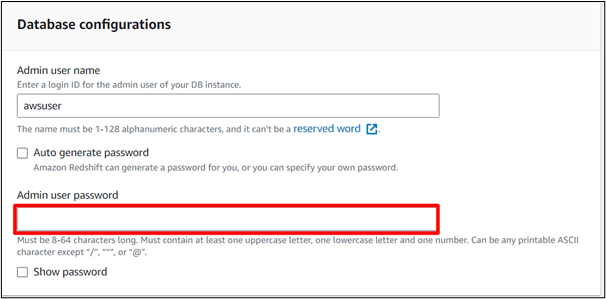
Paso 6: Configuración completa
Una vez completada toda la configuración del clúster, haga clic en ' Crear cluster ' botón:
Aquí, llevará algún tiempo cargar datos de muestra y crear un clúster de Redshift:
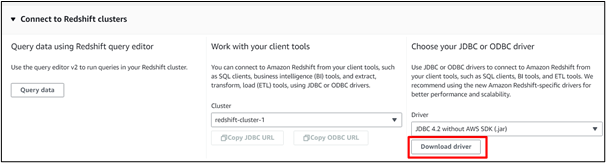
Paso 7: descargue el controlador
En el panel del clúster Redshift, seleccione un clúster y navegue hasta ' Conéctese al clúster de desplazamiento al rojo ' sección. Aquí haga clic en el “ Descargar controlador ”Para descargar el controlador JDBC más reciente:
Nota : También puede descargar la última versión del controlador Redshift desde Documentación de AWS :
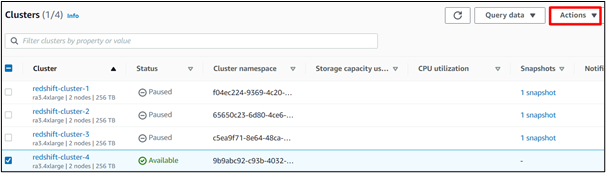
Paso 8: modificar las acciones
Sobre el ' Clústeres 'Panel de control, haga clic en el botón ' Comportamiento ' botón:
Paso 9: modificar el acceso
En la lista desplegable Acciones, haga clic en ' Modificar la configuración de acceso público ' opción:
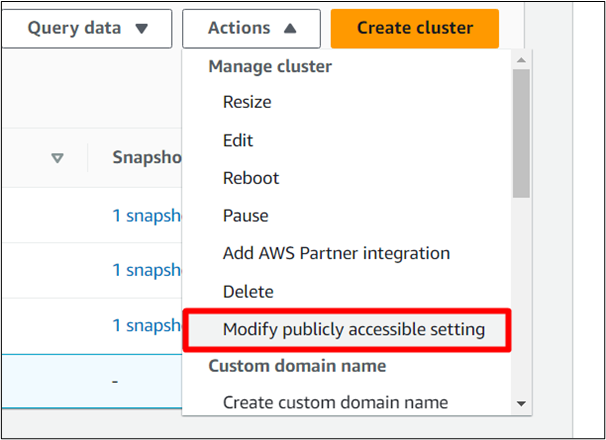
Paso 10: active el acceso
Comprobar el ' Activar Acceso público ”Opción y guardar cambios:
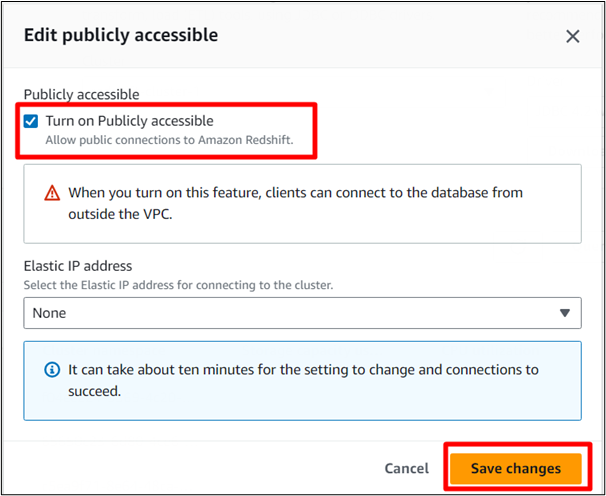
Aquí, AWS guardará los cambios en su clúster.

Consejo adicional: ¿Cómo crear una conexión con SQL Workbench?
Para conectarse con SQL Workbench, siga los pasos que se mencionan a continuación:
Paso 1: Abra el archivo ejecutable de SQL Workbench
Desde el instalador descargado, haga clic en ' Banco de trabajo SQL ”archivo ejecutable y haga clic en “ Administrar controladores ”en la interfaz:
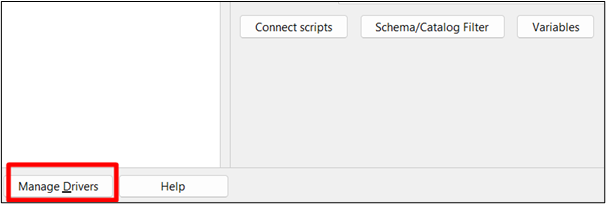
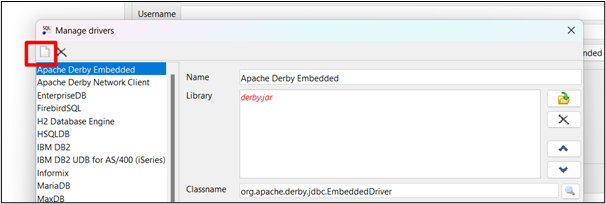
Paso 2: nuevo controlador
Clickea en el ' Archivo nuevo 'Opción como se resalta en la siguiente imagen:
Paso 3: proporcione información para el conductor
Proporcione un nombre para el controlador y haga clic en el botón resaltado para buscar la ruta del controlador JDBC descargado. El controlador que descargamos anteriormente, busca su ruta y proporciónala aquí:
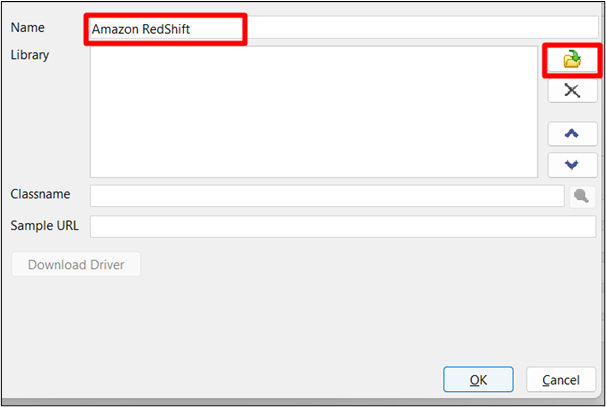
Paso 4: guardar cambios
Luego haga clic en “ DE ACUERDO ”para guardar los cambios:
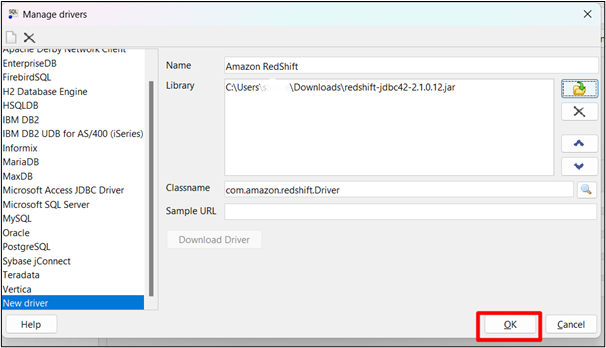
Paso 5: copia la URL
Vaya al panel de Amazon Redshift Cluster y seleccione el clúster. Copie la URL del clúster:
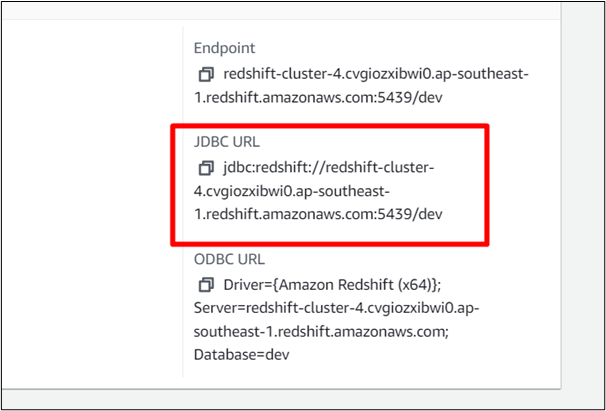
Paso 6: proporcione el nombre del controlador y la URL
Proporcione el nombre de su controlador y pegue su URL en la interfaz de conexión del banco de trabajo SQL. Comprobar el ' Confirmación automática ' caja:
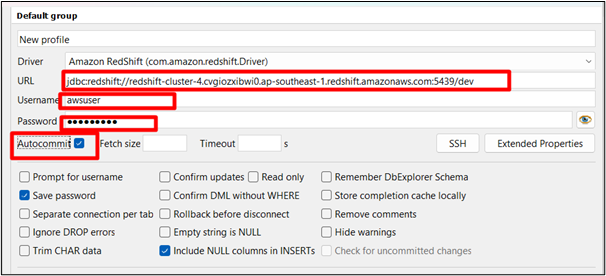
Paso 7: prueba
Clickea en el ' Prueba Botón ”para probar la conectividad:
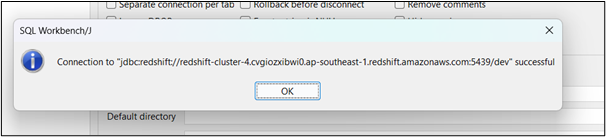
Aquí, la conexión ha sido exitosa en la prueba de conectividad:
Paso 8: presione el botón 'Aceptar'
Después de que la prueba sea exitosa, haga clic en ' DE ACUERDO ' botón:
Eso es todo de la guía.
Conclusión
AWS JDBC proporciona seguridad de datos y espacio para administrar grandes volúmenes de datos y se puede conectar a varias herramientas de terceros instalándolas y pegando la URL de JDBC. AWS ofrece muchos otros servicios a sus usuarios brindando la facilidad de administrar datos de manera eficiente y efectiva. Este artículo proporciona una demostración práctica de cómo descargar e instalar el controlador JDBC.