6.1 Introducción
Las computadoras modernas de uso general son de dos tipos: CISC y RISC. CISC significa Computadora con conjunto de instrucciones complejas. RISK significa Computadora con conjunto de instrucciones reducido. Los microprocesadores 6502 o 6510, aplicables a la computadora Commodore-64, se parecen más a la arquitectura RISC que a una arquitectura CISC.
Las computadoras RISC generalmente tienen instrucciones en lenguaje ensamblador más cortas (por número de bytes) en comparación con las computadoras CISC.
Nota : Ya sea que se trate de CISC, RISC o una computadora antigua, un periférico comienza desde un puerto interno y sale a través de un puerto externo en la superficie vertical de la unidad del sistema de la computadora (unidad base) y hasta el dispositivo externo.
Una instrucción típica de una computadora CISC puede verse como unir varias instrucciones cortas en lenguaje ensamblador en una instrucción más larga en lenguaje ensamblador, lo que hace que la instrucción resultante sea compleja. En particular, una computadora CISC carga los operandos de la memoria en los registros del microprocesador, realiza una operación y luego almacena el resultado nuevamente en la memoria, todo en una sola instrucción. Por otro lado, se trata de al menos tres instrucciones (cortas) para la computadora RISC.
Hay dos series populares de computadoras CISC: las computadoras con microprocesador Intel y las computadoras con microprocesador AMD. AMD significa microdispositivos avanzados; es una empresa de fabricación de semiconductores. Las series de microprocesadores Intel, en orden de desarrollo, son 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i Series, Celeron y Xeon. Las instrucciones en lenguaje ensamblador para los primeros microprocesadores Intel, como 8086 y 8088, no son muy complejas. Sin embargo, resultan complejos para los nuevos microprocesadores. Los microprocesadores AMD recientes para la serie CISC son Ryzen, Opteron, Athlon, Turion, Phenom y Sempron. Los microprocesadores Intel y AMD se conocen como microprocesadores x86.
ARM significa Máquina RISC Avanzada. Las arquitecturas ARM definen una familia de procesadores RISC que son adecuados para su uso en una amplia variedad de aplicaciones. Si bien muchos microprocesadores Intel y AMD se utilizan en las computadoras personales de escritorio, muchos procesadores ARM sirven como procesadores integrados en sistemas críticos para la seguridad, como frenos antibloqueo de automóviles y como procesadores de uso general en relojes inteligentes, teléfonos portátiles, tabletas y computadoras portátiles. . Aunque ambos tipos de microprocesadores se pueden ver en dispositivos pequeños y grandes, los microprocesadores RISC se encuentran más en dispositivos pequeños que en dispositivos grandes.
Palabra de computadora
Si se dice que una computadora es una computadora de 32 bits, significa que la información se almacena, transfiere y manipula en forma de códigos binarios de treinta y dos bits dentro de la parte interna de la placa base. También significa que los registros de propósito general en el microprocesador de la computadora tienen 32 bits de ancho. Los registros A, X e Y del microprocesador 6502 son registros de propósito general. Tienen ocho bits de ancho, por lo que la computadora Commodore-64 es una computadora de palabras de ocho bits.
Algo de vocabulario
Computadoras X86
Los significados de byte, palabra, palabra doble, palabra cuádruple y palabra cuádruple doble son los siguientes para las computadoras x86:
- Byte : 8 bits
- Palabra : 16 bits
- palabra doble : 32 bits
- palabra cuádruple : 64 bits
- Doble palabra cuádruple : 128 bits
Computadoras ARM
Los significados de byte, media palabra, palabra y palabra doble son los siguientes para las computadoras ARM:
- Byte : 8 bits
- convertirse en la mitad : 16 bits
- Palabra : 32 bits
- palabra doble : 64 bits
Deben tenerse en cuenta las diferencias y similitudes entre los nombres (y valores) de x86 y ARM.
Nota : Los números enteros con signo en ambos tipos de computadoras son complemento a dos.
Ubicación de la memoria
Con la computadora Commodore-64, una ubicación de memoria suele ser de un byte, pero ocasionalmente pueden ser dos bytes consecutivos cuando se consideran los punteros (direccionamiento indirecto). Con una computadora x86 moderna, una ubicación de memoria es de 16 bytes consecutivos cuando se trata de una palabra cuádruple doble de 16 bytes (128 bits), 8 bytes consecutivos cuando se trata de una palabra cuádruple de 8 bytes (64 bits), 4 bytes consecutivos cuando se trata de una palabra doble de 4 bytes (32 bits), 2 bytes consecutivos cuando se trata de una palabra de 2 bytes (16 bits) y 1 byte cuando se trata de un byte (8 bits). Con una computadora ARM moderna, una ubicación de memoria es de 8 bytes consecutivos cuando se trata de una palabra doble de 8 bytes (64 bits), 4 bytes consecutivos cuando se trata de una palabra de 4 bytes (32 bits), 2 bytes consecutivos cuando se trata de media palabra. de 2 bytes (16 bits), y 1 byte cuando se trata de un byte (8 bits).
Este capítulo explica qué es común en las arquitecturas CISC y RISC y cuáles son sus diferencias. Esto se hace en comparación con el 6502 µP y el ordenador commodore-64 cuando sea aplicable.
6.2 Diagrama de bloques de la placa base de una PC moderna
PC significa Computadora Personal. El siguiente es un diagrama de bloques básico genérico para una placa base moderna con un solo microprocesador para una computadora personal. Representa una placa base CISC o RISC.
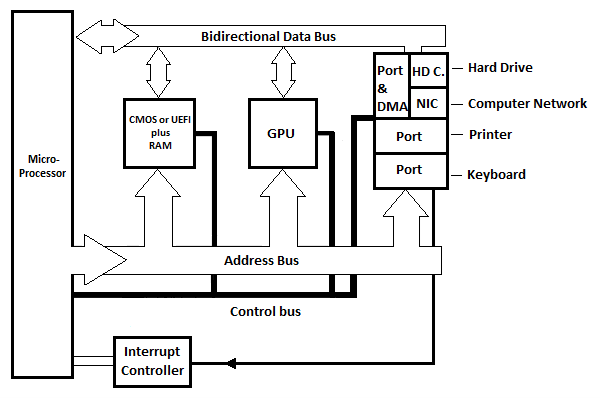
Fig. 6.21 Diagrama de bloques de la placa base básica de una PC moderna
En el diagrama se muestran tres puertos internos, pero en la práctica hay más. Cada puerto tiene un registro que puede verse como el propio puerto. Cada circuito de puerto tiene al menos otro registro que puede denominarse 'registro de estado'. El registro de estado indica el puerto al programa que envía la señal de interrupción al microprocesador. Hay un circuito controlador de interrupciones (no mostrado) que diferencia entre las diferentes líneas de interrupción de los diferentes puertos y tiene solo unas pocas líneas al µP.
HD.C en el diagrama significa Tarjeta de disco duro. NIC significa Tarjeta de interfaz de red. La tarjeta (circuito) del disco duro está conectada al disco duro que se encuentra dentro de la unidad base (unidad del sistema) de la computadora moderna. La tarjeta (circuito) de interfaz de red está conectada a través de un cable externo a otra computadora. En el diagrama, hay un puerto y un DMA (consulte la siguiente ilustración) que están conectados a la tarjeta del disco duro y/o a la tarjeta de interfaz de red. DMA significa Acceso Directo a Memoria.
Recuerde del capítulo de la computadora Commodore-64 que para enviar los bytes de la memoria a la unidad de disco u otra computadora, cada byte debe copiarse a un registro en el microprocesador antes de copiarse al puerto interno correspondiente, y luego automáticamente. al dispositivo. Para recibir los bytes de la unidad de disco u otra computadora en la memoria, cada byte debe copiarse desde el registro del puerto interno correspondiente a un registro del microprocesador antes de copiarse en la memoria. Normalmente, esto lleva mucho tiempo si la cantidad de bytes en la secuencia es grande. La solución para una transferencia rápida es el uso de Acceso Directo a Memoria (circuito) sin pasar por el microprocesador.
El circuito DMA está entre el puerto y el HD. C o tarjeta de red. Con el acceso directo a la memoria del circuito DMA, la transferencia de grandes flujos de bytes se realiza directamente entre el circuito DMA y la memoria (RAM) sin la participación continua del microprocesador. El DMA utiliza el bus de direcciones y el bus de datos en lugar de µP. La duración total de la transferencia es más corta que si se va a utilizar µP hard. Tanto HD C. como NIC utilizan DMA cuando tienen un gran flujo de datos (bytes) para transferir con RAM (la memoria).
GPU significa Unidad de procesamiento de gráficos. Este bloque de la placa base se encarga de enviar el texto y las imágenes en movimiento o fijas a la pantalla.
En las computadoras (PC) modernas, no existe la memoria de solo lectura (ROM). Existe, sin embargo, la BIOS o UEFI que es una especie de RAM no volátil. La información en BIOS en realidad se mantiene mediante una batería. La batería es lo que realmente también mantiene el cronómetro del reloj, en la hora y fecha correctas para la computadora. UEFI se inventó después del BIOS y reemplazó al BIOS, aunque el BIOS sigue siendo bastante relevante en las PC modernas. ¡Discutiremos más sobre esto más adelante!
En las PC modernas, los buses de direcciones y datos entre el µP y los circuitos del puerto interno (y la memoria) no son buses paralelos. Son buses serie que necesitan dos conductores para transmisión en un sentido y otros dos conductores para transmisión en sentido contrario. Esto significa, por ejemplo, que se pueden enviar 32 bits en serie (un bit tras otro) en cualquier dirección.
Si la transmisión en serie es sólo en una dirección con dos conductores (dos líneas), se dice que es semidúplex. Si la transmisión en serie es en ambas direcciones con cuatro conductores, un par en cada dirección, se dice que es full-duplex.
Toda la memoria de la computadora moderna todavía consta de una serie de ubicaciones de bytes: ocho bits por byte. Una computadora moderna tiene un espacio de memoria de al menos 4 gigabytes = 4 x 210 x 2 10 x2 10 = 4 x 1.073.741.824 10 bytes = 4 x 1024 10/sub> x 1024 10 x1024 10 = 4 x 1.073.741.824 10 .
Nota : Aunque no se muestra ningún circuito temporizador en la placa base anterior, todas las placas base modernas tienen circuitos temporizadores.
6.3 Conceptos básicos de la arquitectura informática x64
6.31 El conjunto de registros x64
El microprocesador de 64 bits de la serie de microprocesadores x86 es un microprocesador de 64 bits. Es bastante moderno para sustituir el procesador de 32 bits de la misma serie. Los registros de propósito general del microprocesador de 64 bits y sus nombres son los siguientes:
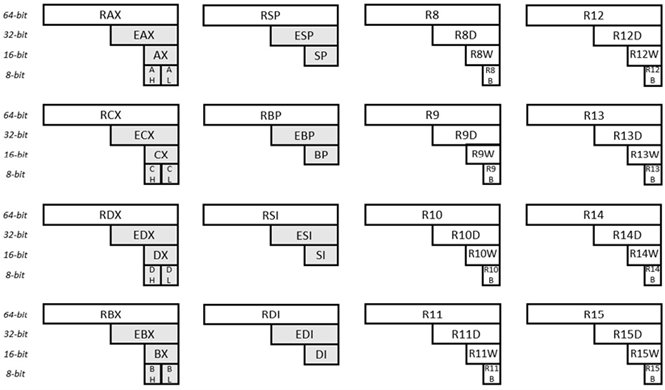
Fig. 6.31 Registros de uso general para x64
En la ilustración proporcionada se muestran dieciséis (16) registros de uso general. Cada uno de estos registros tiene un ancho de 64 bits. Al observar el registro en la esquina superior izquierda, los 64 bits se identifican como RAX. Los primeros 32 bits de este mismo registro (desde la derecha) se identifican como EAX. Los primeros 16 bits de este mismo registro (desde la derecha) se identifican como AX. El segundo byte (desde la derecha) de este mismo registro se identifica como AH (H aquí significa alto). Y el primer byte (de este mismo registro) se identifica como AL (L aquí significa bajo). Al observar el registro en la esquina inferior derecha, los 64 bits se identifican como R15. Los primeros 32 bits de este mismo registro se identifican como R15D. Los primeros 16 bits de este mismo registro se identifican como R15W. Y el primer byte se identifica como R15B. Los nombres de los demás registros (y subregistros) se explican de manera similar.
Existen algunas diferencias entre los µP de Intel y AMD. La información de esta sección es para Intel.
Con el 6502 µP, el registro del contador de programa (no accesible directamente) que contiene la siguiente instrucción a ejecutar tiene 16 bits de ancho. Aquí (x64), el contador del programa se llama puntero de instrucción y tiene 64 bits de ancho. Está etiquetado como RIP. Esto significa que el µP x64 puede direccionar hasta 264 = 1,844674407 x 1019 (en realidad 18,446,744,073,709,551,616) ubicaciones de bytes de memoria. RIP no es un registro de propósito general.
El Stack Pointer Register o RSP se encuentra entre los 16 registros de propósito general. Apunta a la última entrada de la pila en la memoria. Al igual que con 6502 µP, la pila para x64 crece hacia abajo. Con el x64, la pila en la RAM se usa para almacenar las direcciones de retorno de las subrutinas. También se utiliza para almacenar el 'espacio de sombra' (consulte la siguiente discusión).
El 6502 µP tiene un registro de estado del procesador de 8 bits. El equivalente en x64 se llama registro RFLAGS. Este registro almacena los indicadores que se utilizan para los resultados de las operaciones y para controlar el procesador (μP). Tiene 64 bits de ancho. Los 32 bits superiores están reservados y no se utilizan actualmente. La siguiente tabla proporciona los nombres, índices y significados de los bits comúnmente utilizados en el registro RFLAGS:
| Tabla 6.31.1 Banderas RFLAGS (Bits) más utilizadas |
|||
|---|---|---|---|
| Símbolo | Poco | Nombre | Objetivo |
| FQ | 0 | Llevar | Se establece si una operación aritmética genera un acarreo o un préstamo del bit más significativo del resultado; de lo contrario. Este indicador indica una condición de desbordamiento para la aritmética de enteros sin signo. También se utiliza en aritmética de precisión múltiple. |
| FP | 2 | Paridad | Se establece si el byte menos significativo del resultado contiene un número par de 1 bits; de lo contrario. |
| DE | 4 | Ajustar | Se establece si una operación aritmética genera un acarreo o un préstamo del bit 3 del resultado; de lo contrario. Esta bandera se utiliza en aritmética decimal codificada en binario (BCD). |
| ZF | 6 | Cero | Se establece si el resultado es cero; de lo contrario. |
| SF | 7 | Firmar | Se establece si es igual al bit más significativo del resultado, que es el bit de signo de un entero con signo (0 indica un valor positivo y 1 indica un valor negativo). |
| DE | 11 | Desbordamiento | Se establece si el resultado entero es un número positivo demasiado grande o un número negativo demasiado pequeño (excluyendo el bit de signo) para caber en el operando de destino; de lo contrario. Este indicador indica una condición de desbordamiento para la aritmética de enteros con signo (complemento a dos). |
| DF | 10 | Dirección | Se establece si las instrucciones de la cadena de dirección operan (incremento o decremento). |
| IDENTIFICACIÓN | 21 | Identificación | Se establece si su capacidad de cambio denota la presencia de la instrucción CPUID. |
Además de los dieciocho registros de 64 bits que se indicaron anteriormente, la arquitectura x64 µP tiene ocho registros de 80 bits de ancho para aritmética de punto flotante. Estos ocho registros también se pueden utilizar como registros MMX (consulte la siguiente discusión). También hay dieciséis registros de 128 bits para XMM (consulte la siguiente discusión).
No se trata solo de registros. Hay más registros x64 que son registros de segmento (en su mayoría no utilizados en x64), registros de control, registros de administración de memoria, registros de depuración, registros de virtualización, registros de rendimiento que rastrean todo tipo de parámetros internos (aciertos/errores de caché, microoperaciones ejecutadas, temporización). , y mucho más).
SIMD
SIMD significa Instrucción única de datos múltiples. Esto significa que una instrucción en lenguaje ensamblador puede actuar sobre múltiples datos al mismo tiempo en un microprocesador. Considere la siguiente tabla:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| = | 10 | 12 | 14 | 16 | 18 | 20 | 22 | 24 |
En esta tabla, se suman ocho pares de números en paralelo (con la misma duración) para dar ocho respuestas. Una instrucción en lenguaje ensamblador puede realizar ocho sumas de enteros paralelos en los registros MMX. Se puede hacer algo similar con los registros XMM. Entonces, existen instrucciones MMX para números enteros e instrucciones XMM para flotantes.
6.32 Mapa de memoria y x64
Dado que el puntero de instrucción (contador de programa) tiene 64 bits, esto significa que se pueden direccionar 264 = 1,844674407 x 1019 ubicaciones de bytes de memoria. En hexadecimal, la ubicación del byte más alto es FFFF,FFFF,FFFF,FFFF16. Actualmente, ninguna computadora común y corriente puede proporcionar un espacio de memoria tan grande (completo). Entonces, un mapa de memoria adecuado para la computadora x64 es el siguiente:

Observe que la brecha de 0000,8000,0000,000016 a FFFF,7FFF,FFFF,FFFF16 no tiene ubicaciones de memoria (no hay bancos de memoria RAM). Esta es una diferencia de FFFF,0000,0000,000116 que es bastante grande. La mitad superior canónica tiene el sistema operativo, mientras que la mitad inferior canónica tiene los programas (aplicaciones) y los datos del usuario. El sistema operativo consta de dos partes: una pequeña UEFI (BIOS) y una parte grande que se carga desde el disco duro. El siguiente capítulo habla más sobre los sistemas operativos modernos. Tenga en cuenta la similitud con este mapa de memoria y el del Commodore-64, cuando 64 KB podría haber parecido mucha memoria.
En este contexto, el sistema operativo se denomina aproximadamente 'núcleo'. El kernel es similar al Kernal de la computadora Commodore-64, pero tiene muchas más subrutinas.
El endianness para x64 es little endian, lo que significa que para una ubicación, la dirección inferior apunta al byte de contenido inferior en la memoria.
6.33 Modos de direccionamiento en lenguaje ensamblador para x64
Los modos de direccionamiento son las formas en que una instrucción puede acceder a los registros µP y a la memoria (incluidos los registros del puerto interno). El x64 tiene muchos modos de direccionamiento, pero aquí solo se abordan los modos de direccionamiento más utilizados. La sintaxis general de una instrucción aquí es:
destino del código de operación, fuente
Los números decimales se escriben sin prefijo ni sufijo. Con el 6502, la fuente está implícita. El x64 tiene más códigos de operación que el 6502, pero algunos de los códigos de operación tienen los mismos mnemotécnicos. Las instrucciones x64 individuales tienen una longitud variable y su tamaño puede oscilar entre 1 y 15 bytes. Los modos de direccionamiento comúnmente utilizados son los siguientes:
Modo de direccionamiento inmediato
Aquí, el operando fuente es un valor real y no una dirección o etiqueta. Ejemplo (leer el comentario):
AÑADIR EAX, 14 ; agregue decimal 14 a EAX de 32 bits de RAX de 64 bits, la respuesta permanece en EAX (destino)
Registrarse para registrar el modo de direccionamiento
Ejemplo:
AÑADIR R8B, AL; agregue AL de 8 bits de RAX a R8B de R8 de 64 bits; las respuestas permanecen en R8B (destino)
Modo de direccionamiento indirecto e indexado
El direccionamiento indirecto con el 6502 µP significa que la ubicación de la dirección dada en la instrucción tiene la dirección efectiva (puntero) de la ubicación final. Algo similar ocurre con x64. El direccionamiento de índice con el 6502 µP significa que el contenido de un registro µP se agrega a la dirección dada en la instrucción para tener la dirección efectiva. Con el x64 pasa algo parecido. Además, con x64, el contenido del registro también se puede multiplicar por 1, 2, 4 u 8 antes de agregarlo a la dirección dada. La instrucción mov (copiar) del x64 puede combinar direccionamiento indirecto e indexado. Ejemplo:
MOV R8W, 1234[8*RAX+RCX] ; mover palabra en la dirección (8 x RAX + RCX) + 1234
Aquí, R8W tiene los primeros 16 bits de R8. La dirección proporcionada es 1234. El registro RAX tiene un número de 64 bits que se multiplica por 8. El resultado se suma al contenido del registro RCX de 64 bits. Este segundo resultado se suma a la dirección dada que es 1234 para obtener la dirección efectiva. El número en la ubicación de la dirección efectiva se mueve (copia) al primer lugar de 16 bits (R8W) del registro R8, reemplazando lo que estaba allí. Observe el uso de corchetes. Recuerde que una palabra en x64 tiene 16 bits de ancho.
Direccionamiento relativo a RIP
Para el 6502 µP, el direccionamiento relativo se utiliza sólo con instrucciones de derivación. Allí, el único operando del código de operación es un desplazamiento que se suma o resta al contenido del contador de programa para la dirección de instrucción efectiva (no la dirección de datos). Algo similar sucede con el x64 donde el Contador de Programa se llama como Puntero de Instrucción. La instrucción con x64 no sólo tiene que ser una instrucción de rama. Un ejemplo de direccionamiento relativo a RIP es:
MOV AL, [RIP]
AL de RAX tiene un número con signo de 8 bits que se suma o resta del contenido en RIP (puntero de instrucción de 64 bits) para apuntar a la siguiente instrucción. Tenga en cuenta que el origen y el destino se intercambian excepcionalmente en esta instrucción. Tenga en cuenta también el uso de corchetes que se refieren al contenido de RIP.
6.34 Instrucciones de uso común de x64
En la siguiente tabla * significa diferentes sufijos posibles de un subconjunto de códigos de operación:
| Tabla 6.34.1 Instrucciones de uso común en x64 |
|
|---|---|
| Código de operación | Significado |
| MOVIMIENTO | Mover (copiar) hacia/desde/entre memoria y registros |
| CMOV* | Varios movimientos condicionales |
| XCHG | Intercambio |
| BSWAP | intercambio de bytes |
| EMPUJAR/POP | Uso de la pila |
| AGREGAR/ADC | Añadir/con llevar |
| SUB/SBC | Restar/con acarreo |
| MUL/IMUL | Multiplicar/sin firmar |
| DIV/IDIV | Dividir/sin firmar |
| INC/DIC | Incremento/Decremento |
| NEG | Negar |
| CMP | Comparar |
| Y/O/XOR/NO | Operaciones bit a bit |
| SHR/SAR | Desplazamiento a la derecha lógico/aritmético |
| SHL/SAL | Desplazamiento a la izquierda lógico/aritmético |
| ROR/ROL | Girar derecha/izquierda |
| RCR/RCL | Girar hacia la derecha/izquierda a través de la broca de transporte |
| BT/BTS/BTR | Prueba de bits/y configuración/y reinicio |
| JMP | salto incondicional |
| JE/JNE/JC/JNC/J* | Saltar si es igual/no es igual/llevar/no llevar/muchos otros |
| CAMINAR/CAMINAR/CAMINAR | Bucle con ECX |
| LLAMADA/RETIRO | Llamar a subrutina/retorno |
| NOP | No operacion |
| ID de CPU | información de la CPU |
El x64 tiene instrucciones de multiplicar y dividir. Dispone de circuitos hardware de multiplicación y división en su µP. El 6502 µP no tiene circuitos de hardware de multiplicación y división. Es más rápido hacer la multiplicación y división por hardware que por software (incluido el desplazamiento de bits).
Instrucciones de cadena
Hay varias instrucciones de cadena, pero la única que se analizará aquí es la instrucción MOVS (para mover cadena) para copiar una cadena que comienza en la dirección C000. h . Para empezar en la dirección C100 h , utilice la siguiente instrucción:
MOVIMIENTOS [C100H], [C000H]
Tenga en cuenta el sufijo H para hexadecimal.
6.35 Bucle en x64
El 6502 µP tiene instrucciones de derivación para realizar bucles. Una instrucción de bifurcación salta a una ubicación de dirección que tiene la nueva instrucción. La ubicación de la dirección puede denominarse 'bucle'. El x64 tiene instrucciones LOOP/LOOPE/LOOPNE para realizar bucles. Estas palabras reservadas en lenguaje ensamblador no deben confundirse con la etiqueta 'bucle' (sin las comillas). El comportamiento es el siguiente:
LOOP disminuye ECX y comprueba si ECX no es cero. Si se cumple esa condición (cero), salta a una etiqueta especificada. De lo contrario, fracasa (continúe con el resto de las instrucciones en la siguiente discusión).
LOOPE disminuye ECX y verifica que ECX no sea cero (puede ser 1, por ejemplo) y que ZF esté configurado (en 1). Si se cumplen estas condiciones, salta a la etiqueta. De lo contrario, fracasa.
LOOPNE disminuye ECX y verifica que ECX no sea cero y que ZF NO ESTÉ configurado (es decir, que sea cero). Si se cumplen estas condiciones, salta a la etiqueta. De lo contrario, fracasa.
Con x64, el registro RCX o sus subpartes como ECX o CX contienen el contador entero. Con las instrucciones LOOP, el contador normalmente cuenta atrás, disminuyendo en 1 por cada salto (bucle). En el siguiente segmento de código de bucle, el número en el registro EAX aumenta de 0 a 10 en diez iteraciones, mientras que el número en ECX cuenta (disminuye) 10 veces (lea los comentarios):
MOV EAX, 0 ;
MOV ECX, 10; cuenta regresiva 10 veces de forma predeterminada, una vez por cada iteración
etiqueta:
INC EAX ; incrementar EAX como cuerpo del bucle
Etiqueta de BUCLE; disminuya EAX, y si EAX no es cero, vuelva a ejecutar el cuerpo del bucle desde 'etiqueta:'
La codificación del bucle comienza desde 'etiqueta:'. Tenga en cuenta el uso de los dos puntos. La codificación del bucle termina con la “etiqueta LOOP” que dice decremento EAX. Si su contenido no es cero, regrese a la instrucción después de 'etiqueta:' y vuelva a ejecutar cualquier instrucción (todas las instrucciones del cuerpo) que baje hasta la 'etiqueta LOOP'. Tenga en cuenta que 'etiqueta' aún puede tener otro nombre.
6.36 Entrada/Salida de x64
Esta sección del capítulo trata sobre el envío de datos a un puerto de salida (interno) o la recepción de datos desde un puerto de entrada (interno). El chipset tiene puertos de ocho bits. Dos puertos consecutivos de 8 bits pueden tratarse como un puerto de 16 bits y cuatro puertos consecutivos pueden ser un puerto de 32 bits. De esta manera, el procesador puede transferir 8, 16 o 32 bits hacia o desde un dispositivo externo.
La información se puede transferir entre el procesador y un puerto interno de dos maneras: usando lo que se conoce como entrada/salida mapeada en memoria o usando un espacio de direcciones de entrada/salida separado. La E/S asignada en memoria es como lo que sucede con el procesador 6502, donde las direcciones de los puertos son en realidad parte de todo el espacio de memoria. En este caso, al enviar los datos a una ubicación de dirección particular, van a un puerto y no a un banco de memoria. Los puertos pueden tener un espacio de direcciones de E/S independiente. En este último caso, todos los bancos de memoria tienen sus direcciones desde cero. Hay un rango de direcciones separado desde 0000H hasta FFFF16. Estos son utilizados por los puertos del chipset. La placa base está programada para no confundir entre E/S asignadas en memoria y espacio de direcciones de E/S separadas.
E/S asignadas en memoria
Con esto, los puertos se consideran ubicaciones de memoria, y los códigos de operación normales a usar entre la memoria y µP se utilizan para la transferencia de datos entre µP y los puertos. Entonces, para mover un byte desde un puerto en la dirección F000H al registro µP RAX:EAX:AX:AL, haga lo siguiente:
MOV AL, [F000H]
Se puede mover una cadena desde la memoria a un puerto y viceversa. Ejemplo:
MOVIMIENTOS [F000H], [C000H] ; el origen es C000H y el destino es el puerto en F000H.
Espacio de direcciones de E/S separado
En este caso, se deben utilizar instrucciones especiales para entrada y salida.
Transferir artículos individuales
El registro del procesador para la transferencia es RAX. En realidad, es RAX:EAX para palabra doble, RAX:EAX:AX para palabra y RAX:EAX:AX:AL para byte. Entonces, para transferir un byte desde un puerto en FFF0h a RAX:EAX:AX:AL, escriba lo siguiente:
IN AL, [FFF0H]
Para la transferencia inversa, escriba lo siguiente:
FUERA [FFF0H], AL
Entonces, para artículos individuales, las instrucciones son DENTRO y FUERA. La dirección del puerto también se puede proporcionar en el registro RDX:EDX:DX.
Transferir cadenas
Se puede transferir una cadena desde la memoria a un puerto del chipset y viceversa. Para transferir una cadena desde un puerto en la dirección FFF0H a la memoria, comience en C100H, escriba:
INS [ESI], [DX]
que tiene el mismo efecto que:
INS [EDI], [DX]
El programador debe colocar la dirección del puerto de dos bytes de FFF0H en el registro RDX:EDX:Dx y debe colocar la dirección de dos bytes de C100H en el registro RSI:ESI o RDI:EDI. Para la transferencia inversa, haga lo siguiente:
INS [DX], [ESI]
que tiene el mismo efecto que:
INS [DX], [EDI]
6.37 La pila en x64
Al igual que el procesador 6502, el procesador x64 también tiene una pila de RAM. La pila para el x64 puede ser 2 16 = 65,536 bytes de largo o pueden ser 2 32 = 4.294.967.296 bytes de longitud. También crece hacia abajo. Cuando el contenido de un registro se inserta en la pila, el número en el puntero de la pila RSP disminuye en 8. Recuerde que una dirección de memoria para x64 tiene 64 bits de ancho. El valor en el puntero de la pila en µP apunta a la siguiente ubicación en la pila en la RAM. Cuando el contenido de un registro (o un valor en un operando) se extrae de la pila a un registro, el número en el puntero de la pila RSP aumenta en 8. El sistema operativo decide el tamaño de la pila y dónde comienza en la RAM. y crece hacia abajo. Recuerde que una pila es una estructura de último en entrar, primero en salir (LIFO) que crece hacia abajo y se contrae hacia arriba en este caso.
Para enviar el contenido del registro µP RBX a la pila, haga lo siguiente:
EMPUJAR RBX
Para devolver la última entrada de la pila a RBX, haga lo siguiente:
RBX POP
6.38 Procedimiento en x64
La subrutina en x64 se llama 'procedimiento'. La pila se utiliza aquí más que para el 6502 µP. La sintaxis para un procedimiento x64 es:
nombre_procesamiento:
cuerpo del procedimiento
…
bien
Antes de continuar, observe que los códigos de operación y las etiquetas para una subrutina x64 (instrucciones en lenguaje ensamblador en general) no distinguen entre mayúsculas y minúsculas. Es decir, proc_name es el mismo que PROC_NAME. Al igual que el 6502, el nombre del procedimiento (etiqueta) comienza al principio de una nueva línea en el editor de texto para lenguaje ensamblador. Esto va seguido de dos puntos y no de un espacio y un código de operación como en el 6502. Sigue el cuerpo de la subrutina, que termina en RET y no en RTS como en el 6502 µP. Al igual que con el 6502, cada instrucción del cuerpo, incluido RET, no comienza al principio de su línea. Tenga en cuenta que una etiqueta aquí puede tener más de 8 caracteres. Para llamar a este procedimiento, desde arriba o debajo del procedimiento escrito, haga lo siguiente:
LLAMAR nombre_proc
Con el 6502, el nombre de la etiqueta se escribe simplemente para llamar. Sin embargo, aquí se escribe la palabra reservada “CALL” o “llamar”, seguida del nombre del procedimiento (subrutina) después de un espacio.
Cuando se trata de procedimientos, suele haber dos procedimientos. Un procedimiento llama al otro. El procedimiento que llama (tiene la instrucción de llamada) se llama 'persona que llama' y el procedimiento que se llama se llama 'llamado'. Hay una convención (reglas) a seguir.
Las reglas del que llama
La persona que llama debe cumplir con las siguientes reglas al invocar una subrutina:
1. Antes de llamar a una subrutina, la persona que llama debe guardar el contenido de ciertos registros que están designados como guardados por la persona que llama en la pila. Los registros guardados por la persona que llama son R10, R11 y cualquier registro en el que se coloquen los parámetros (RDI, RSI, RDX, RCX, R8, R9). Si el contenido de estos registros se va a conservar durante la llamada a la subrutina, insértelos en la pila en lugar de guardarlos en la RAM. Esto debe hacerse porque el destinatario debe utilizar los registros para borrar el contenido anterior.
2. Si el procedimiento es sumar dos números, por ejemplo, los dos números son los parámetros que se pasarán a la pila. Para pasar los parámetros a la subrutina, coloque seis de ellos en los siguientes registros en orden: RDI, RSI, RDX, RCX, R8, R9. Si hay más de seis parámetros en la subrutina, inserte el resto en la pila en orden inverso (es decir, el último parámetro primero). A medida que la pila crece, el primero de los parámetros adicionales (en realidad, el séptimo parámetro) se almacena en la dirección más baja (esta inversión de parámetros se usó históricamente para permitir que las funciones (subrutinas) se pasaran con un número variable de parámetros).
3. Para llamar a la subrutina (procedimiento), utilice la instrucción de llamada. Esta instrucción coloca la dirección de retorno encima de los parámetros en la pila (posición más baja) y las ramas al código de subrutina.
4. Después de que regresa la subrutina (es decir, inmediatamente después de la instrucción de llamada), la persona que llama debe eliminar cualquier parámetro adicional (más allá de los seis que están almacenados en los registros) de la pila. Esto restaura la pila a su estado antes de que se realizara la llamada.
5. La persona que llama puede esperar encontrar el valor de retorno (dirección) de la subrutina en el registro RAX.
6. La persona que llama restaura el contenido de los registros guardados por la persona que llama (R10, R11 y cualquiera en los registros de paso de parámetros) sacándolos de la pila. La persona que llama puede suponer que la subrutina no modificó ningún otro registro.
Debido a la forma en que está estructurada la convención de llamada, normalmente ocurre que algunos (o la mayoría) de estos pasos no realizarán ningún cambio en la pila. Por ejemplo, si hay seis parámetros o menos, no se inserta nada en la pila en ese paso. Del mismo modo, los programadores (y compiladores) normalmente mantienen los resultados que les interesan fuera de los registros guardados por la persona que llama en los pasos 1 y 6 para evitar el exceso de pulsaciones y estallidos.
Hay otras dos formas de pasar parámetros a una subrutina, pero no se abordarán en este curso profesional en línea. Uno de ellos utiliza la propia pila en lugar de los registros de uso general.
Las reglas del destinatario
La definición de la subrutina llamada debe seguir las siguientes reglas:
1. Asigne las variables locales (variables que se desarrollan dentro del procedimiento) utilizando los registros o haciendo espacio en la pila. Recuerde que la pila crece hacia abajo. Entonces, para hacer espacio en la parte superior de la pila, se debe disminuir el puntero de la pila. La cantidad en la que se reduce el puntero de la pila depende del número necesario de variables locales. Por ejemplo, si se requieren un flotante local y un largo local (12 bytes en total), el puntero de la pila debe disminuirse en 12 para dejar espacio para estas variables locales. En un lenguaje de alto nivel como C, esto significa declarar las variables sin asignar (inicializar) los valores.
2. A continuación, se deben guardar los valores de cualquier registro guardado por el destinatario designado (registros de propósito general no guardados por el llamante) que utiliza la función. Para guardar los registros, empújelos hacia la pila. Los registros guardados por el destinatario de la llamada son RBX, RBP y R12 a R15 (la convención de llamada también conserva RSP, pero no es necesario insertarlo en la pila durante este paso).
Después de realizar estas tres acciones, puede continuar la operación real de la subrutina. Cuando la subrutina está lista para regresar, las reglas de la convención de llamada continúan.
3. Cuando finaliza la subrutina, el valor de retorno de la subrutina debe colocarse en RAX si aún no está allí.
4. La subrutina debe restaurar los valores antiguos de cualquier registro guardado por el destinatario (RBX, RBP y R12 a R15) que fueron modificados. El contenido del registro se restaura sacándolos de la pila. Tenga en cuenta que los registros deben abrirse en el orden inverso al que fueron empujados.
5. A continuación, desasignamos las variables locales. La forma más sencilla de hacer esto es agregar al RSP la misma cantidad que se le restó en el paso 1.
6. Finalmente, volvemos a la persona que llama ejecutando una instrucción ret. Esta instrucción buscará y eliminará la dirección de devolución adecuada de la pila.
Un ejemplo del cuerpo de una subrutina llamador para llamar a otra subrutina que es “myFunc” es el siguiente (lea los comentarios):
; Quiere llamar a una función 'myFunc' que requiere tres
; parámetro entero. El primer parámetro está en RAX.
; El segundo parámetro es la constante 456. El tercero
; El parámetro está en la ubicación de memoria 'variable'.
empujar rdi; rdi será un parámetro, así que guárdelo
; long retVal = miFunc (x, 456, z);
mov rdi, rax; poner el primer parámetro en RDI
mov rsi, 456; poner el segundo parámetro en RSI
mov rdx, [variable]; poner tercer parámetro en RDX
llamar a miFunc; llamar a la función
pop rdi; restaurar el valor RDI guardado
; El valor de retorno de myFunc ahora está disponible en RAX.
Un ejemplo de una función de destinatario (myFunc) es (lea los comentarios):
miFunción:
; ∗∗∗ Prólogo de subrutina estándar ∗∗∗
sub rsp, 8 ; espacio para una variable local de 64 bits (resultado) usando el código de operación “sub”
empujar rbx; guardar destinatario-guardar registros
empujar rbp ; ambos serán utilizados por myFunc
; ∗∗∗ Subrutina Cuerpo ∗∗∗
mov rax , rdi ; parámetro 1 a RAX
mov rbp , rsi ; parámetro 2 a RBP
mov rbx, rdx; parámetro 3 a rb x
mov[rsp+1 6], rbx; poner rbx en la variable local
añadir [rsp + 1 6 ] , rbp ; agregar rbp a la variable local
mov rax , [ rsp +16 ] ; mover el contenido de la variable local a RAX
; (valor de retorno/resultado final)
; ∗∗∗ Epílogo de subrutina estándar ∗∗∗
pop rbp; recuperar registros de guardado del destinatario de la llamada
pop rbx; al revés de cuando se empuja
añadir rsp, 8; desasignar variables locales. 8 significa 8 bytes
retirarse; sacar el valor superior de la pila, saltar allí
6.39 Interrupciones y excepciones para x64
El procesador proporciona dos mecanismos para interrumpir la ejecución del programa, interrupciones y excepciones:
- Una interrupción es un evento asincrónico (puede ocurrir en cualquier momento) que normalmente es desencadenado por un dispositivo de E/S.
- Una excepción es un evento sincrónico (ocurre cuando el código se ejecuta, está preprogramado, en función de algún suceso) que se genera cuando el procesador detecta una o más condiciones predefinidas mientras ejecuta una instrucción. Se especifican tres clases de excepciones: fallas, trampas y abortos.
El procesador responde a interrupciones y excepciones esencialmente de la misma manera. Cuando se señala una interrupción o excepción, el procesador detiene la ejecución del programa o tarea actual y cambia a un procedimiento de manejo que está escrito específicamente para manejar la condición de interrupción o excepción. El procesador accede al procedimiento del controlador a través de una entrada en la tabla de descriptores de interrupción (IDT). Cuando el controlador ha terminado de manejar la interrupción o excepción, el control del programa regresa al programa o tarea interrumpida.
El sistema operativo, el ejecutivo y/o los controladores de dispositivo normalmente manejan las interrupciones y excepciones independientemente de los programas o tareas de la aplicación. Los programas de aplicación pueden, sin embargo, acceder a los manejadores de interrupciones y excepciones que están incorporados en un sistema operativo o ejecutarlo a través de llamadas en lenguaje ensamblador.
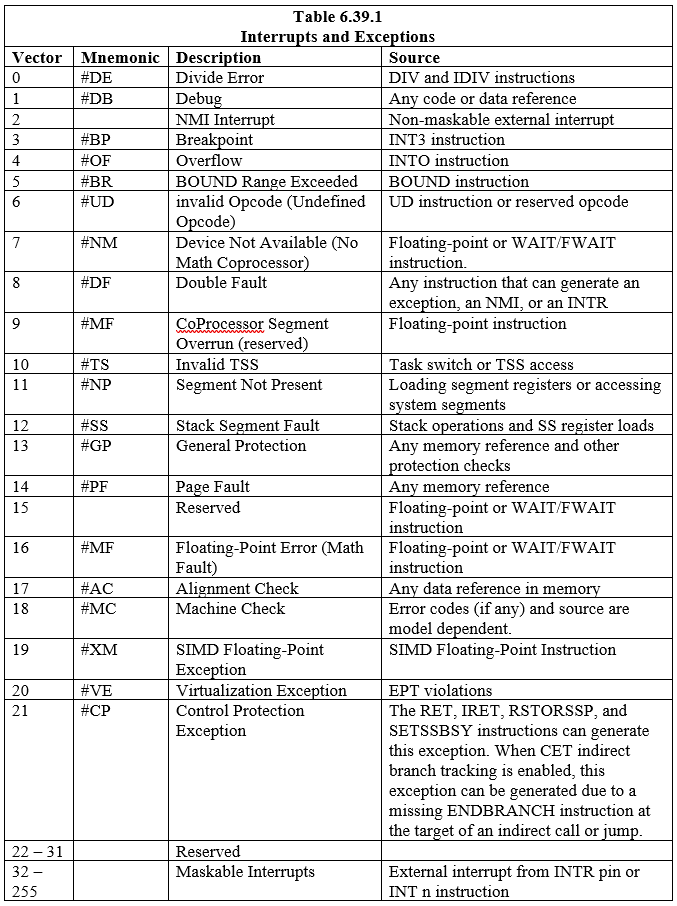
Se definen dieciocho (18) interrupciones y excepciones predefinidas, que están asociadas con entradas en el IDT. También se pueden realizar y asociar con la tabla doscientas veinticuatro (224) interrupciones definidas por el usuario. Cada interrupción y excepción en el IDT se identifica con un número que se denomina 'vector'. La Tabla 6.39.1 enumera las interrupciones y excepciones con entradas en el IDT y sus respectivos vectores. Los vectores 0 a 8, 10 a 14 y 16 a 19 son las interrupciones y excepciones predefinidas. Los vectores 32 a 255 son para las interrupciones definidas por software (usuario), que son para interrupciones de software o interrupciones de hardware enmascarables.
Cuando el procesador detecta una interrupción o excepción, hace una de las siguientes cosas:
- Ejecutar una llamada implícita a un procedimiento controlador.
- Ejecutar una llamada implícita a una tarea de controlador
6.4 Conceptos básicos de la arquitectura informática ARM de 64 bits
Las arquitecturas ARM definen una familia de procesadores RISC que son adecuados para su uso en una amplia variedad de aplicaciones. ARM es una arquitectura de carga/almacenamiento que requiere que los datos se carguen desde la memoria a un registro antes de que pueda realizarse cualquier procesamiento, como una operación ALU (Unidad Aritmética Lógica). Una instrucción posterior almacena el resultado en la memoria. Si bien esto puede parecer un paso atrás con respecto a las arquitecturas x86 y x64, que operan directamente sobre los operandos en la memoria en una sola instrucción (usando registros del procesador, por supuesto), el enfoque de carga/almacenamiento, en la práctica, permite varias operaciones secuenciales. para realizarse a alta velocidad en un operando una vez que se carga en uno de los muchos registros del procesador. Los procesadores ARM tienen la opción de little endianness o big endianness. La configuración predeterminada de ARM 64 es little-endian, que es la configuración que utilizan habitualmente los sistemas operativos. La arquitectura ARM de 64 bits es moderna y está destinada a reemplazar la arquitectura ARM de 32 bits.
Nota : Cada instrucción para ARM µP de 64 bits tiene una longitud de 4 bytes (32 bits).
6.41 Conjunto de registros ARM de 64 bits
Hay 31 registros de propósito general de 64 bits para el µP ARM de 64 bits. El siguiente diagrama muestra los registros de propósito general y algunos registros importantes:
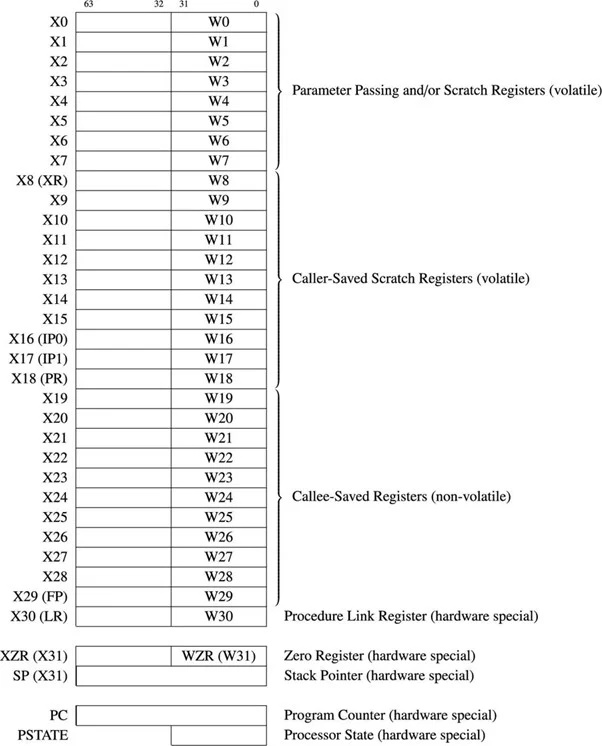
Fig.4.11.1 Propósito general de 64 bits y algunos registros importantes
Los registros de propósito general se denominan desde X0 hasta X30. La primera parte de 32 bits de cada registro se denomina W0 hasta W30. Cuando no se enfatiza la diferencia entre 32 bits y 64 bits, se utiliza el prefijo 'R'. Por ejemplo, R14 se refiere a W14 o X14.
El 6502 µP tiene un contador de programa de 16 bits y puede direccionar los 2 16 Ubicaciones de bytes de memoria. El ARM µP de 64 bits tiene un contador de programa de 64 bits y puede direccionar hasta 2 64 = 1,844674407 x 1019 (en realidad, 18.446.744.073.709.551.616) ubicaciones de bytes de memoria. El contador del programa contiene la dirección de la siguiente instrucción a ejecutar. La longitud de la instrucción de ARM64 o AArch64 suele ser de cuatro bytes. El procesador incrementa automáticamente este registro en cuatro después de que se recupera cada instrucción de la memoria.
El registro Stack Pointer o SP no se encuentra entre los 31 registros de propósito general. El puntero de pila de cualquier arquitectura apunta a la última entrada de la pila en la memoria. Para el ARM-64, la pila crece hacia abajo.
El 6502 µP tiene un registro de estado del procesador de 8 bits. El equivalente en ARM64 se llama registro PSTATE. Este registro almacena los indicadores que se utilizan para los resultados de las operaciones y para controlar el procesador (μP). Tiene 32 bits de ancho. La siguiente tabla proporciona los nombres, índices y significados de los bits comúnmente utilizados en el registro PSTATE:
| Tabla 6.41.1 Banderas PSTATE más utilizadas (Bits) |
||
|---|---|---|
| Símbolo | Poco | Objetivo |
| METRO | 0-3 | Modo: el nivel de privilegio de ejecución actual (USR, SVC, etc.). |
| t | 4 | Pulgar: Se configura si el conjunto de instrucciones T32 (Pulgar) está activo. Si está claro, el conjunto de instrucciones ARM está activo. El código de usuario puede configurar y borrar este bit. |
| Y | 9 | Endianidad: Establecer este bit habilita el modo big-endian. Si está claro, el modo little-endian está activo. El valor predeterminado es el modo little-endian. |
| q | 27 | Bandera de saturación acumulada: Se establece si, en algún momento de una serie de operaciones, se produce un desbordamiento o saturación. |
| EN | 28 | Indicador de desbordamiento: se establece si la operación resultó en un desbordamiento firmado. |
| C | 29 | Bandera de acarreo: Indica si la suma produjo un acarreo o la resta produjo un préstamo. |
| CON | 30 | Bandera cero: Se establece si el resultado de una operación es cero. |
| norte | 31 | Bandera negativa: Se establece si el resultado de una operación es negativo. |
El ARM-64 µP tiene muchos otros registros.
SIMD
SIMD significa instrucción única, datos múltiples. Esto significa que una instrucción en lenguaje ensamblador puede actuar sobre múltiples datos al mismo tiempo en un microprocesador. Hay treinta y dos registros de 128 bits de ancho para usar con operaciones SIMD y de punto flotante.
6.42 Mapeo de memoria
Tanto la RAM como la DRAM son memorias de acceso aleatorio. La DRAM tiene un funcionamiento más lento que la RAM. La DRAM es más barata que la RAM. Si hay más de 32 gigabytes (GB) de DRAM continua en la memoria, habrá más problemas de administración de memoria: 32 GB = 32 x 1024 x 1024 x 1024 bytes. Para un espacio de memoria total mucho mayor que 32 GB, la DRAM superior a 32 GB debe intercalarse con RAM para una mejor gestión de la memoria. Para comprender el mapa de memoria ARM-64, primero debe comprender el mapa de memoria de 4 GB para la unidad central de procesamiento (CPU) ARM de 32 bits. CPU significa µP. Para una computadora de 32 bits, el espacio máximo de memoria direccionable es 2 32 = 4 x 2 10 x2 10 x2 10 = 4 x 1024 x 1024 x 1024 = 4.294.967.296 = 4 GB.
Mapa de memoria ARM de 32 bits
El mapa de memoria para un ARM de 32 bits es:

Para una computadora de 32 bits, el tamaño máximo de la memoria total es de 4 GB. Desde la dirección de 0 GB hasta la dirección de 1 GB se encuentran el sistema operativo ROM, la RAM y las ubicaciones de E/S. La idea general de ROM OS, RAM y direcciones de E/S es similar a la situación del Commodore-64 con una posible CPU 6502. La ROM del sistema operativo para el Commodore-64 se encuentra en el extremo superior del espacio de memoria. El sistema operativo ROM aquí es mucho más grande que el del Commodore-64 y está al comienzo de todo el espacio de direcciones de memoria. En comparación con otras computadoras modernas, el sistema operativo ROM aquí es completo, en el sentido de que es comparable con la cantidad de sistemas operativos en sus discos duros. Hay dos razones principales para tener el sistema operativo en los circuitos integrados ROM: 1) Las CPU ARM se utilizan principalmente en dispositivos pequeños como teléfonos inteligentes. Muchos discos duros son más grandes que los teléfonos inteligentes y otros dispositivos pequeños, 2) por seguridad. Cuando el sistema operativo está en la memoria de solo lectura, los piratas informáticos no pueden dañarlo (sobrescribir partes). Las secciones de RAM y las secciones de entrada/salida también son muy grandes en comparación con las del Commodore-64.
Cuando se enciende el sistema operativo ROM de 32 bits, el sistema operativo debe iniciarse (iniciar desde) la dirección 0x00000000 o la dirección 0xFFFF0000 si HiVEC está habilitado. Entonces, cuando se enciende después de la fase de reinicio, el hardware de la CPU carga 0x00000000 o 0xFFFF0000 en el contador de programa. El prefijo '0x' significa hexadecimal. La dirección de arranque de las CPU ARMv8 de 64 bits es una implementación definida. Sin embargo, el autor aconseja al ingeniero informático que comience en 0x00000000 o 0xFFFF0000 por motivos de compatibilidad con versiones anteriores.
De 1 GB a 2 GB es la entrada/salida asignada. Existe una diferencia entre las E/S asignadas y solo las E/S que se encuentran entre 0 GB y 1 GB. Con E/S, la dirección de cada puerto se fija como en el Commodore-64. Con E/S asignadas, la dirección de cada puerto no es necesariamente la misma para cada operación de la computadora (dinámica).
De 2GB a 4GB es DRAM. Esta es la RAM esperada (o habitual). DRAM significa RAM dinámica, no es el sentido de una dirección cambiante durante el funcionamiento de la computadora, sino el sentido de que el valor de cada celda en la RAM física debe actualizarse con cada pulso de reloj.
Nota :
- De 0x0000,0000 a 0x0000,FFFF es la ROM del sistema operativo.
- De 0x0001,0000 a 0x3FFF,FFFF, puede haber más ROM, luego RAM y luego algunas E/S.
- De 0x4000,0000 a 0x7FFF,FFFF, se permite una E/S adicional y/o una E/S asignada.
- De 0x8000,0000 a 0xFFFF,FFFF es la DRAM esperada.
Esto significa que, en la práctica, la DRAM esperada no tiene que comenzar en el límite de memoria de 2 GB. ¿Por qué el programador debería respetar los límites ideales cuando no hay suficientes bancos de RAM físicos insertados en la placa base? Esto se debe a que el cliente no tiene suficiente dinero para todos los bancos de RAM.
Mapa de memoria ARM de 36 bits
Para una computadora ARM de 64 bits, los 32 bits se utilizan para direccionar toda la memoria. Para una computadora ARM de 64 bits, los primeros 36 bits se pueden usar para direccionar toda la memoria que, en este caso, es 2 36 = 68.719.476.736 = 64 GB. Esto ya es mucha memoria. Las computadoras comunes hoy en día no necesitan esta cantidad de memoria. Esto aún no alcanza el rango máximo de memoria al que se puede acceder con 64 bits. El mapa de memoria de 36 bits para la CPU ARM es:
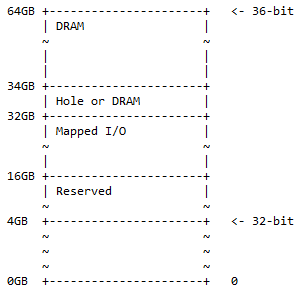
Desde la dirección de 0 GB hasta la dirección de 4 GB está el mapa de memoria de 32 bits. “Reservado” significa no utilizado y se conserva para uso futuro. No es necesario que sean bancos de memoria físicos insertados en la placa base para ese espacio. Aquí, la DRAM y las E/S asignadas tienen el mismo significado que para el mapa de memoria de 32 bits.
En la práctica se puede encontrar la siguiente situación:
- 0x1 0000 0000 – 0x3 FFFF FFFF; reservado. Se reservan 12 GB de espacio de direcciones para uso futuro.
- 0x4 0000 0000 – 0x7 FFFF FFFF; E/S asignadas. Hay 16 GB de espacio de direcciones disponibles para E/S asignadas dinámicamente.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF; Agujero o DRAM. 2 GB de espacio de direcciones pueden contener cualquiera de los siguientes:
- Orificio para habilitar la partición del dispositivo DRAM (como se describe en la siguiente discusión).
- DRACMA.
- 0x8 8000 0000 – 0xF FFFF FFFF; DRACMA. 30 GB de espacio de direcciones para DRAM.
Este mapa de memoria es un superconjunto del mapa de direcciones de 32 bits, con el espacio adicional dividido en 50% de DRAM (1/2) con un orificio opcional y 25% de espacio de E/S asignado y espacio reservado (1/4). ). El 25% restante (1/4) es para el mapa de memoria de 32 bits ½ + ¼ + ¼ = 1.
Nota : De 32 bits a 360 bits es una suma de 4 bits al lado más significativo de 36 bits.
Mapa de memoria de 40 bits
El mapa de direcciones de 40 bits es un superconjunto del mapa de direcciones de 36 bits y sigue el mismo patrón de 50 % de DRAM de un orificio opcional, 25 % de espacio de E/S asignado y espacio reservado, y el resto del 25 %. espacio para el mapa de memoria anterior (36 bits). El diagrama del mapa de memoria es:
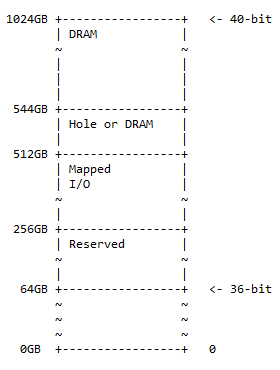
El tamaño del agujero es 544 – 512 = 32 GB. En la práctica se puede encontrar la siguiente situación:
- 0x10 0000 0000 – 0x3F FFFF FFFF; reservado. Se reservan 192 GB de espacio de direcciones para uso futuro.
- 0x40 0000 0000 – 0x7F FFFF FFFF; mapeado. E/S Hay 256 GB de espacio de direcciones disponibles para E/S asignadas dinámicamente.
- 0x80 0000 0000 – 0x87 FFFF FFFF; agujero o DRAM. 32 GB de espacio de direcciones pueden contener cualquiera de los siguientes:
- Orificio para habilitar la partición del dispositivo DRAM (como se describe en la siguiente discusión)
- DRACMA
- 0x88 0000 0000 – 0xFF FFFF FFFF; DRACMA. 480 GB de espacio de direcciones para DRAM.
Nota : De 36 bits a 40 bits es una suma de 4 bits al lado más significativo de 36 bits.
Agujero de DRAM
En el mapa de memoria más allá de 32 bits, es un agujero DRAM o una continuación de la DRAM desde arriba. Cuando se trata de un agujero, se debe apreciar de la siguiente manera: El agujero DRAM proporciona una manera de dividir un dispositivo DRAM grande en múltiples rangos de direcciones. El orificio DRAM opcional se propone al comienzo del límite superior de direcciones DRAM. Esto permite un esquema de decodificación simplificado al particionar un dispositivo DRAM de gran capacidad en la región inferior con dirección física.
Por ejemplo, una parte de DRAM de 64 GB se subdivide en tres regiones y los desplazamientos de direcciones se realizan mediante una simple resta en los bits de dirección de orden superior de la siguiente manera:
| Tabla 6.42.1 Ejemplo de partición de DRAM de 64 GB con agujeros |
|||
|---|---|---|---|
| Direcciones físicas en SoC | Compensar | Dirección DRAM interna | |
| 2 GB (mapa de 32 bits) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 – 0x00 7FFFFFFF |
| 30 GB (mapa de 36 bits) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32 GB (mapa de 40 bits) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
Mapas de memoria direccionados de 44 y 48 bits propuestos para CPU ARM
Supongamos que una computadora personal tiene 1024 GB (= 1 TB) de memoria; Eso es demasiada memoria. Y así, los mapas de memoria direccionados de 44 y 48 bits para CPU ARM de 16 TB y 256 TB, respectivamente, son solo propuestas para las necesidades futuras de la computadora. De hecho, estas propuestas para las CPU ARM siguen la misma división de memoria por ratio que los mapas de memoria anteriores. Es decir: 50% de DRAM con un orificio opcional, 25% de espacio de E/S asignado y espacio reservado, y el resto del 25% de espacio para el mapa de memoria anterior.
Los mapas de memoria direccionados de 52, 56, 60 y 64 bits aún deben proponerse para ARM de 64 bits en un futuro lejano. Si los científicos de aquella época todavía encuentran útil la partición 50: 25: 25 de todo el espacio de memoria, mantendrán la proporción.
Nota : SoC significa System-on-Chip, que se refiere a circuitos en el chip µP que de otro modo no habrían estado allí.
SRAM o memoria estática de acceso aleatorio es más rápida que la DRAM más tradicional, pero requiere más área de silicio. SRAM no requiere actualización. El lector puede imaginar la RAM como SRAM.
6.43 Modos de direccionamiento en lenguaje ensamblador para ARM 64
ARM es una arquitectura de carga/almacenamiento que requiere que los datos se carguen desde la memoria a un registro del procesador antes de que pueda realizarse cualquier procesamiento, como una operación lógica aritmética. Una instrucción posterior almacena el resultado en la memoria. Si bien esto podría parecer un paso atrás con respecto a x86 y sus arquitecturas x64 posteriores, que operan directamente sobre los operandos en la memoria en una sola instrucción, en la práctica, el enfoque de carga/almacenamiento permite que se realicen varias operaciones secuenciales a alta velocidad en un operando una vez que se carga en uno de los muchos registros del procesador.
El formato del lenguaje ensamblador ARM tiene similitudes y diferencias con la serie x64 (x86).
- Compensar : Se puede agregar una constante con signo al registro base. El desplazamiento se escribe como parte de la instrucción. Por ejemplo: ldr x0, [rx, #10] carga r0 con la palabra en la dirección r1+10.
- Registro : Un incremento sin signo que se almacena en un registro se puede sumar o restar del valor en un registro base. Por ejemplo: ldr r0, [x1, x2] carga r0 con la palabra en la dirección x1+x2. Cualquiera de los registros puede considerarse como el registro base.
- Registro escalado : Un incremento en un registro se desplaza hacia la izquierda o hacia la derecha un número específico de posiciones de bits antes de agregarlo o restarlo del valor del registro base. Por ejemplo: ldr x0, [x1, x2, lsl #3] carga r0 con la palabra en la dirección r1+(r2×8). El desplazamiento puede ser un desplazamiento lógico hacia la izquierda o hacia la derecha (lsl o lsr) que inserta cero bits en las posiciones de bits desocupadas o un desplazamiento aritmético hacia la derecha (asr) que replica el bit de signo en las posiciones desocupadas.
Cuando hay dos operandos involucrados, el destino viene antes (a la izquierda) de la fuente (hay algunas excepciones a esto). Los códigos de operación para el lenguaje ensamblador ARM no distinguen entre mayúsculas y minúsculas.
Modo de direccionamiento ARM64 inmediato
Ejemplo:
movimiento r0, #0xFF000000; Cargue el valor de 32 bits FF000000h en r0
Un valor decimal no tiene 0x pero aún está precedido por #.
Regístrate Directo
Ejemplo:
movimiento x0, x1; Copiar x1 a x0
Registrarse Indirecto
Ejemplo:
cadena x0, [x3]; Almacene x0 en la dirección en x3
Registrar Indirecto con Offset
Ejemplos:
ldr x0, [x1, #32] ; Cargue r0 con el valor en la dirección [r1+32]; r1 es el registro base
cadena x0, [x1, #4]; Almacene r0 en la dirección [r1+4]; r1 es el registro base; los numeros son base 10
Registro indirecto con compensación (preincrementado)
Ejemplos:
ldr x0, [x1, #32]! ; Cargue r0 con [r1+32] y actualice r1 a (r1+32)
cadena x0, [x1, #4]! ; Almacene r0 en [r1+4] y actualice r1 a (r1+4)
Tenga en cuenta el uso del '!' símbolo.
Registro indirecto con compensación (postincrementado)
Ejemplos:
ldr x0, [x1], #32; Cargue [x1] en x0, luego actualice x1 a (x1+32)
cadena x0, [x1], #4; Almacene x0 en [x1], luego actualice x1 a (x1+4)
Doble Registro Indirecto
La dirección del operando es la suma de un registro base y un registro incremental. Los nombres de los registros están entre corchetes.
Ejemplos:
ldr x0, [x1, x2] ; Cargar x0 con [x1+x2]
cadena x0, [rx, x2]; Almacenar x0 en [x1+x2]
Modo de direccionamiento relativo
En el modo de direccionamiento relativo, la instrucción efectiva es la siguiente instrucción en el contador de programa, más un índice. El índice puede ser positivo o negativo.
Ejemplo:
ldr x0, [ordenador personal, #24]
Esto significa el registro de carga X0 con la palabra a la que apunta el contenido de la PC más 24.
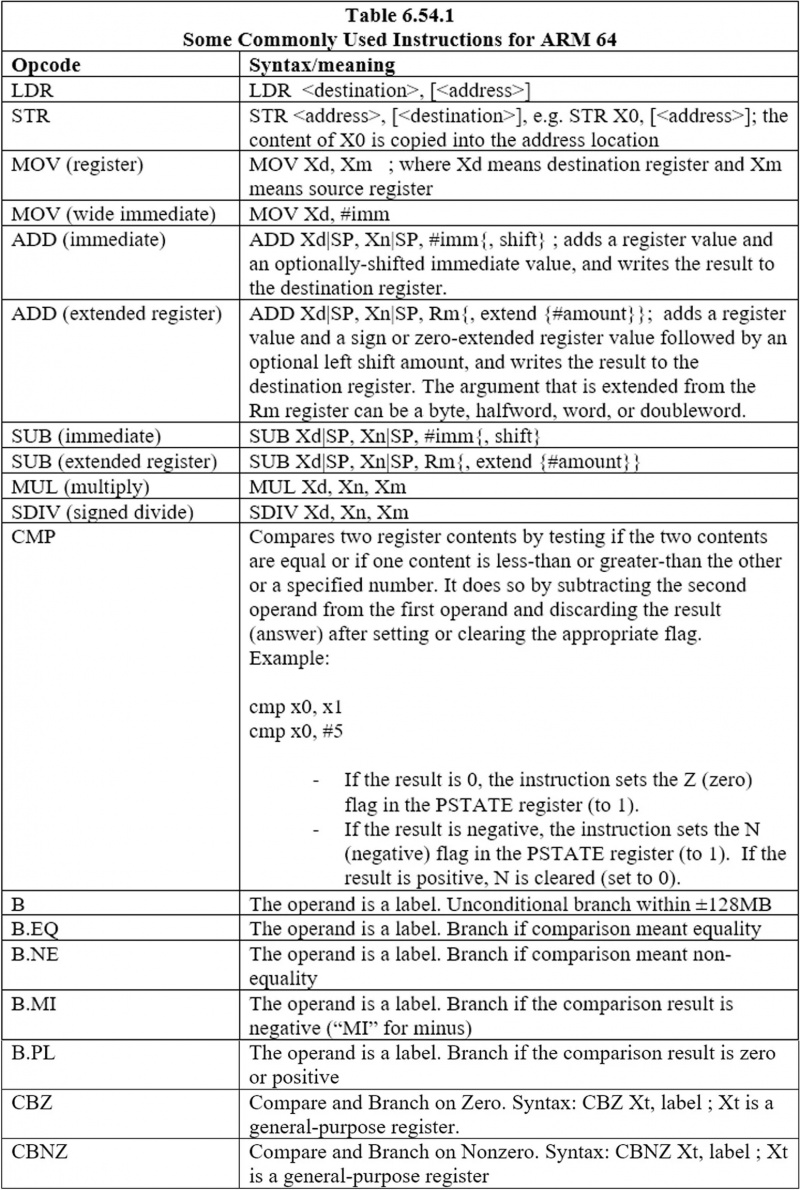
6.44 Algunas instrucciones de uso común para ARM 64
Estas son las instrucciones más utilizadas:
6.45 Bucle
Ilustración
El siguiente código sigue sumando el valor en el registro X10 al valor en X9 hasta que el valor en X8 sea cero. Supongamos que todos los valores son números enteros. El valor en X8 se resta en 1 en cada iteración:
bucle:
CBZ X8, saltar
AÑADIR X9, X9, X10; El primer X9 es el destino y el segundo X9 es el origen.
SUB X8, X8, #1; El primer X8 es el destino y el segundo X8 es el origen.
bucle B
saltar:
Al igual que con el 6502 µP y el X64 µP, la etiqueta en el ARM 64 µP comienza al principio de la línea. El resto de las instrucciones comienzan en algunos espacios después del inicio de la línea. Con x64 y ARM 64, la etiqueta va seguida de dos puntos y una nueva línea. Mientras que con 6502, la etiqueta va seguida de una instrucción después de un espacio. En el código anterior, la primera instrucción que es 'CBZ X8, skip' significa que si el valor en X8 es cero, continúa en la etiqueta 'skip:', omitiendo las instrucciones intermedias y continuando con el resto de las instrucciones a continuación. 'saltar:'. El “bucle B” es un salto incondicional a la etiqueta “bucle”. Se puede utilizar cualquier otro nombre de etiqueta en lugar de 'bucle'.
Entonces, al igual que con el 6502 µP, use las instrucciones de bifurcación para tener un bucle con el ARM 64.
6.46 ARM 64 Entrada/Salida
Todos los periféricos ARM (puertos internos) están asignados en memoria. Esto significa que la interfaz de programación es un conjunto de registros direccionados en memoria (puertos internos). La dirección de dicho registro es un desplazamiento de una dirección base de memoria específica. Esto es similar a cómo el 6502 realiza la entrada/salida. ARM no tiene la opción de un espacio de direcciones de E/S separado.
6.47 Pila de ARM 64
El ARM 64 tiene una pila en memoria (RAM) de forma similar a la que tienen el 6502 y el x64. Sin embargo, con el ARM64, no hay ningún código de operación push o pop. La pila en ARM 64 también crece hacia abajo. La dirección en el puntero de la pila apunta justo después del último byte del último valor colocado en la pila.
La razón por la que no existe un código de operación emergente o push genérico para ARM64 es que ARM 64 administra su pila en grupos de 16 bytes consecutivos. Sin embargo, los valores existen en grupos de bytes de un byte, dos bytes, cuatro bytes y 8 bytes. Por lo tanto, se puede colocar un valor en la pila y el resto de los lugares (ubicaciones de bytes) para compensar los 16 bytes se rellenan con bytes ficticios. Esto tiene la desventaja de desperdiciar memoria. Una mejor solución es llenar la ubicación de 16 bytes con valores más pequeños y tener algún código escrito por un programador que rastree de dónde provienen los valores en la ubicación de 16 bytes (registros). Este código adicional también es necesario para recuperar los valores. Una alternativa a esto es llenar dos registros de propósito general de 8 bytes con los diferentes valores y luego enviar el contenido de los dos registros de 8 bytes a una pila. Aquí todavía se necesita un código adicional para rastrear los valores pequeños específicos que entran y salen de la pila.
El siguiente código almacena cuatro datos de 4 bytes en la pila:
cadena w0, [sp, #-4]!
cadena w1, [sp, #-8]!
cadena w2, [sp, #-12]!
cadena w3, [sp, #-16]!
Los primeros cuatro bytes (w) de los registros (x0, x1, x2 y x3) se envían a ubicaciones de 16 bytes consecutivos en la pila. Tenga en cuenta el uso de 'str' y no 'push'. Tenga en cuenta el símbolo de exclamación al final de cada instrucción. Dado que la pila de memoria crece hacia abajo, el primer valor de cuatro bytes comienza en una posición que está menos cuatro bytes por debajo de la posición del puntero de la pila anterior. El resto de los valores de cuatro bytes siguen hacia abajo. El siguiente segmento de código hará el equivalente correcto (y en orden) de extraer los cuatro bytes:
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
ldr w0, [sp], #12
Tenga en cuenta el uso del código de operación ldr en lugar de pop. Tenga en cuenta también que aquí no se utiliza el símbolo de exclamación.
Todos los bytes en X0 (8 bytes) y X1 (8 bytes) se pueden enviar a la ubicación de 16 bytes en la pila de la siguiente manera:
paso x0, x1, [sp, #-16]! ; 8 + 8 = 16
En este caso, los registros x2 (w2) y x3 (w3) no son necesarios. Todos los bytes buscados están en los registros X0 y X2. Tenga en cuenta el código de operación stp para almacenar los pares de contenidos de registros en la RAM. Tenga en cuenta también el símbolo de exclamación. El equivalente pop es:
ldp x0, x1, [sp], #0
No hay ningún signo de exclamación para esta instrucción. Tenga en cuenta el código de operación LDP en lugar de LDR para cargar dos ubicaciones de datos consecutivas desde la memoria a dos registros µP. Recuerde también que copiar desde la memoria a un registro µP es cargar, no debe confundirse con cargar un archivo desde el disco a la RAM, y copiar desde un registro µP a la RAM es almacenar.
6.48 Subrutina
Una subrutina es un bloque de código que realiza una tarea, opcionalmente basándose en algunos argumentos y, opcionalmente, devuelve un resultado. Por convención, los registros R0 a R3 (cuatro registros) se utilizan para pasar los argumentos (parámetros) a una subrutina, y R0 se utiliza para devolver un resultado al autor de la llamada. Una subrutina que necesita más de 4 entradas utiliza la pila para las entradas adicionales. Para llamar a una subrutina, utilice el enlace o la instrucción de rama condicional. La sintaxis de la instrucción de enlace es:
etiqueta BL
Donde BL es el código de operación y la etiqueta representa el inicio (dirección) de la subrutina. Esta rama es incondicional, hacia adelante o hacia atrás dentro de 128 MB. La sintaxis de la instrucción de rama condicional es:
B. segunda etiqueta
Donde cond es la condición, por ejemplo, eq (igual) o ne (no igual). El siguiente programa tiene la subrutina doadd que suma los valores de dos argumentos y devuelve un resultado en R0:
Subruta de ÁREA, CÓDIGO, SÓLO LECTURA; Nombra este bloque de código
ENTRADA ; Marcar la primera instrucción para ejecutar
iniciar MOV r0, #10; Configurar parámetros
MOV r1, #3
BL dodd ; Llamar a subrutina
detener MOV r0, #0x18; angel_SWIreason_ReportException
LDR r1, =0x20026; ADP_Stopped_ApplicationSalir
SVC #0x123456; Semihosting ARM (anteriormente SWI)
doadd AGREGAR r0, r0, r1; código de subrutina
BXlr; Regreso de subrutina
;
FIN ; Marcar el final del archivo
Los números a sumar son el decimal 10 y el decimal 3. Las dos primeras líneas de este bloque de código (programa) se explicarán más adelante. Las siguientes tres líneas envían 10 al registro R0 y 3 al registro R1, y también llaman a la subrutina doadd. El “doadd” es la etiqueta que contiene la dirección del inicio de la subrutina.
La subrutina consta de sólo dos líneas. La primera línea suma el contenido 3 de R al contenido 10 de R0 lo que permite el resultado de 13 en R0. La segunda línea con el código de operación BX y el operando LR regresa de la subrutina al código de la persona que llama.
BIEN
El código de operación RET en ARM 64 todavía trata con la subrutina, pero funciona de manera diferente a RTS en 6502 o RET en x64, o la combinación 'BX LR' en ARM 64. En ARM 64, la sintaxis de RET es:
RECTA {Xn}
Esta instrucción le da la oportunidad al programa de continuar con una subrutina que no es la subrutina llamante, o simplemente continuar con alguna otra instrucción y su siguiente segmento de código. Xn es un registro de propósito general que contiene la dirección a la que debe continuar el programa. Esta instrucción se bifurca incondicionalmente. El contenido predeterminado es X30 si no se proporciona Xn.
Estándar de llamada a procedimiento
Si el programador quiere que su código interactúe con un código escrito por otra persona o con un código producido por un compilador, el programador debe acordar con la persona o el escritor del compilador las reglas para el uso de registros. Para la arquitectura ARM, estas reglas se denominan Estándar de llamada a procedimiento o PCS. Son acuerdos entre dos o tres partes. El PCS especifica lo siguiente:
- Qué registros µP se utilizan para pasar los argumentos a la función (subrutina)
- ¿Qué registros µP se utilizan para devolver el resultado a la función que realiza la llamada, conocida como la persona que llama?
- Qué µP registra la función que se está llamando, que se conoce como destinatario, puede corromper
- ¿Qué registros µP el destinatario de la llamada no puede corromper?
6.49 Interrupciones
Hay dos tipos de circuitos controladores de interrupciones disponibles para el procesador ARM:
- Controlador de interrupciones estándar: el controlador de interrupciones determina qué dispositivo requiere servicio leyendo un registro de mapa de bits del dispositivo en el controlador de interrupciones.
- Controlador vectorial de interrupciones (VIC): prioriza las interrupciones y simplifica la determinación de qué dispositivo causó la interrupción. Después de asociar una prioridad y una dirección de controlador con cada interrupción, el VIC solo afirma una señal de interrupción al procesador si la prioridad de una nueva interrupción es mayor que la del controlador de interrupciones que se está ejecutando actualmente.
Nota : La excepción se refiere a un error. Los detalles del controlador de interrupción vectorial para la computadora ARM de 32 bits son los siguientes (64 bits es similar):
| Tabla 6.49.1 Excepción/interrupción de vector ARM para computadora de 32 bits |
|||
|---|---|---|---|
| Excepción/Interrupción | mano corta | DIRECCIÓN | Dirección alta |
| Reiniciar | REINICIAR | 0x00000000 | 0xffff0000 |
| Instrucción indefinida | FNUD | 0x00000004 | 0xffff0004 |
| Interrupción de software | SWI | 0x00000008 | 0xffff0008 |
| Aborto de captación previa | pabt | 0x0000000C | 0xffff000C |
| fecha del aborto | DABT | 0x00000010 | 0xffff0010 |
| Reservado | – | 0x00000014 | 0xffff0014 |
| Solicitud de interrupción | IRQ | 0x00000018 | 0xffff0018 |
| Solicitud de interrupción rápida | FIQ | 0x0000001C | 0xffff001C |
Este se parece al arreglo para la arquitectura 6502 donde NMI , BR , y IRQ puede tener punteros en la página cero y las rutinas correspondientes están en lo alto de la memoria (ROM OS). A continuación se describen brevemente las filas de la tabla anterior:
REINICIAR
Esto sucede cuando el procesador se enciende. Inicializa el sistema y configura las pilas para diferentes modos de procesador. Es la excepción de mayor prioridad. Al ingresar al controlador de reinicio, el CPSR está en modo SVC y los bits IRQ y FIQ se establecen en 1, enmascarando cualquier interrupción.
FECHA DEL ABORTO
La segunda prioridad más alta. Esto sucede cuando intentamos leer/escribir en una dirección no válida o acceder al permiso de acceso incorrecto. Al ingresar al Controlador de aborto de datos, las IRQ se deshabilitarán (I-bit establecido en 1) y se habilitará FIQ. Las IRQ están enmascaradas, pero las FIQ se mantienen desenmascaradas.
FIQ
La interrupción de mayor prioridad, IRQ y FIQ, están deshabilitadas hasta que se maneje FIQ.
IRQ
La interrupción de alta prioridad, el controlador IRQ, se ingresa solo si no hay FIQ ni aborto de datos en curso.
Aborto de búsqueda previa
Esto es similar a la cancelación de datos, pero ocurre cuando falla la recuperación de la dirección. Al ingresar al controlador, las IRQ se deshabilitan, pero las FIQ permanecen habilitadas y pueden ocurrir durante un aborto de búsqueda previa.
SWI
Se produce una excepción de interrupción de software (SWI) cuando se ejecuta la instrucción SWI y no se ha marcado ninguna de las otras excepciones de mayor prioridad.
Instrucción indefinida
La excepción de instrucción no definida ocurre cuando una instrucción que no está en el conjunto de instrucciones ARM o Thumb llega a la etapa de ejecución de la canalización y ninguna de las otras excepciones ha sido marcada. Esta es la misma prioridad que SWI, ya que puede suceder una a la vez. Esto significa que la instrucción que se está ejecutando no puede ser al mismo tiempo una instrucción SWI y una instrucción indefinida.
Manejo de excepciones ARM
Los siguientes eventos ocurren cuando ocurre una excepción:
- Guarde el CPSR en el SPSR del modo de excepción.
- La PC se almacena en el LR del modo de excepción.
- El registro de enlace se establece en una dirección específica según la instrucción actual. Por ejemplo: para ISR, LR = última instrucción ejecutada + 8.
- Actualice el CPSR sobre la excepción.
- Configure la PC con la dirección del controlador de excepciones.
6.5 Instrucciones y datos
Los datos se refieren a variables (etiquetas con sus valores) y matrices y otras estructuras similares a las matrices. La cadena es como una serie de caracteres. En uno de los capítulos anteriores se ve una serie de números enteros. Las instrucciones se refieren a códigos de operación y sus operandos. Se puede escribir un programa con los códigos de operación y los datos mezclados en una sección continua de memoria. Este enfoque tiene desventajas pero no se recomienda.
Un programa debe escribirse primero con las instrucciones, seguidas de los datos (el plural de dato es datos). La separación entre las instrucciones y los datos puede ser de sólo unos pocos bytes. Para un programa, tanto las instrucciones como los datos pueden estar en una o dos secciones separadas de la memoria.
6.6 La arquitectura de Harvard
Una de las primeras computadoras se llama Harvard Mark I (1944). Una arquitectura estricta de Harvard utiliza un espacio de direcciones para las instrucciones del programa y un espacio de direcciones separado diferente para los datos. Esto significa que hay dos recuerdos separados. A continuación se muestra la arquitectura:
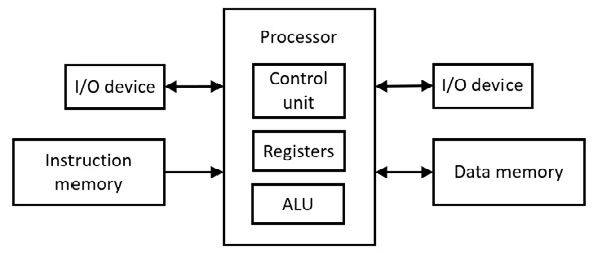
Figura 6.71 Arquitectura de Harvard
La Unidad de Control realiza la decodificación de instrucciones. La Unidad Aritmética Lógica (ALU) realiza las operaciones aritméticas con lógica combinacional (compuertas). ALU también realiza las operaciones lógicas (por ejemplo, cambios).
Con el microprocesador 6502, una instrucción va primero al microprocesador (unidad de control) antes de que el dato (singular de datos) vaya al registro µP antes de interactuar. Esto necesita al menos dos pulsos de reloj y no es un acceso simultáneo a la instrucción y al dato. Por otro lado, la arquitectura Harvard proporciona acceso simultáneo a las instrucciones y datos, con la instrucción y el dato ingresando al µP al mismo tiempo (código de operación a la unidad de control y dato al registro µP), ahorrando al menos un pulso de reloj. Ésta es una forma de paralelismo. Esta forma de paralelismo se utiliza en la caché de hardware de las placas base modernas (consulte la siguiente discusión).
6.7 Memoria caché
La memoria caché (RAM) es una región de memoria de alta velocidad (en comparación con la velocidad de la memoria principal) que almacena temporalmente las instrucciones o datos del programa para uso futuro. La memoria caché funciona más rápido que la memoria principal. Por lo general, estas instrucciones o elementos de datos se recuperan de la memoria principal reciente y es probable que se vuelvan a necesitar en breve. El objetivo principal de la memoria caché es aumentar la velocidad de acceso repetido a las mismas ubicaciones de la memoria principal. Para que sea efectivo, el acceso a los elementos almacenados en caché debe ser significativamente más rápido que el acceso a la fuente original de las instrucciones o datos, conocida como Backing Store.
Cuando se utiliza el almacenamiento en caché, cada intento de acceder a una ubicación de la memoria principal comienza con una búsqueda en el caché. Si el artículo solicitado está presente, el procesador lo recupera y lo utiliza inmediatamente. Esto se llama acierto de caché. Si la búsqueda de caché no tiene éxito (una pérdida de caché), la instrucción o el elemento de datos deben recuperarse del almacén de respaldo (memoria principal). En el proceso de recuperación del elemento solicitado, se agrega una copia al caché para un uso previsto en el futuro cercano.
Unidad de gestión de memoria
La Unidad de administración de memoria (MMU) es un circuito que administra la memoria principal y los registros de memoria relacionados en la placa base. En el pasado, era un circuito integrado separado en la placa base; pero hoy en día suele formar parte del microprocesador. La MMU también debería gestionar el caché (circuito) que también forma parte del microprocesador actual. El circuito de caché es en el pasado un circuito integrado separado.
RAM estática
La RAM estática (SRAM) tiene un tiempo de acceso sustancialmente más rápido que la DRAM, aunque a expensas de circuitos significativamente más complejos. Las celdas de bits SRAM ocupan mucho más espacio en el circuito integrado que las celdas de un dispositivo DRAM que es capaz de almacenar una cantidad equivalente de datos. La memoria principal (RAM) normalmente consta de DRAM (RAM dinámica).
La memoria caché mejora el rendimiento de la computadora porque muchos algoritmos ejecutados por sistemas operativos y aplicaciones exhiben la localidad de referencia. La Localidad de Referencia se refiere a la reutilización de datos a los que se ha accedido recientemente. Esto se conoce como Localidad Temporal. En una placa base moderna, la memoria caché se encuentra en el mismo circuito integrado que el microprocesador. La memoria principal (DRAM) está lejos y es accesible a través de los autobuses. La Localidad de Referencia también se refiere a la localidad espacial. La localidad espacial tiene que ver con la mayor velocidad de acceso a los datos debido a la proximidad física.
Como regla general, las regiones de la memoria caché son pequeñas (en número de ubicaciones de bytes) en comparación con el almacén de respaldo (memoria principal). Los dispositivos de memoria caché están diseñados para una velocidad máxima, lo que generalmente significa que son más complejos y costosos por bit que la tecnología de almacenamiento de datos que se utiliza en el almacén de respaldo. Debido a su tamaño limitado, los dispositivos de memoria caché tienden a llenarse rápidamente. Cuando un caché no tiene una ubicación disponible para almacenar una nueva entrada, se debe descartar una entrada más antigua. El controlador de caché utiliza una política de reemplazo de caché para seleccionar qué entrada de caché se sobrescribirá con la nueva entrada.
El objetivo de la memoria caché del microprocesador es maximizar el porcentaje de aciertos de la caché a lo largo del tiempo, proporcionando así la tasa más alta y sostenida de ejecución de instrucciones. Para lograr este objetivo, la lógica de almacenamiento en caché debe determinar qué instrucciones y datos se colocarán en el caché y se conservarán para su uso en el futuro cercano.
La lógica de almacenamiento en caché de un procesador no garantiza que un elemento de datos almacenado en caché se vuelva a utilizar una vez que se haya insertado en el caché.
La lógica del almacenamiento en caché se basa en la probabilidad de que, debido a la localidad temporal (repetición en el tiempo) y espacial (espacio), exista una muy buena posibilidad de que se acceda a los datos almacenados en caché en un futuro próximo. En implementaciones prácticas en procesadores modernos, los accesos a la memoria caché suelen ocurrir en entre el 95 y el 97 por ciento de los accesos a la memoria. Dado que la latencia de la memoria caché es una pequeña fracción de la latencia de la DRAM, una alta tasa de aciertos de la caché conduce a una mejora sustancial del rendimiento en comparación con un diseño sin caché.
Algo de paralelismo con el caché
Como se mencionó anteriormente, un buen programa en memoria tiene las instrucciones separadas de los datos. En algunos sistemas de caché, hay un circuito de caché a la 'izquierda' del procesador y otro circuito de caché a la 'derecha' del procesador. El caché izquierdo maneja las instrucciones de un programa (o aplicación) y el caché derecho maneja los datos del mismo programa (o misma aplicación). Esto conduce a un mejor aumento de velocidad.
6.8 Procesos y Subprocesos
Tanto las computadoras CISC como RISC tienen procesos. Hay un proceso en el software. Un programa que se está ejecutando (ejecutando) es un proceso. El sistema operativo viene con sus propios programas. Mientras la computadora está en funcionamiento, también se ejecutan los programas del sistema operativo que permiten que la computadora funcione. Estos son procesos del sistema operativo. El usuario o programador puede escribir sus propios programas. Cuando el programa del usuario se está ejecutando, es un proceso. No importa si el programa está escrito en lenguaje ensamblador o en lenguaje de alto nivel como C o C++. Todos los procesos (usuario u sistema operativo) son administrados por otro proceso llamado 'programador'.
Un hilo es como un subproceso que pertenece a un proceso. Un proceso puede comenzar y dividirse en subprocesos y luego continuar como un solo proceso. Un proceso sin hilos puede considerarse como hilo principal. Los procesos y sus subprocesos son gestionados por el mismo programador. El programador en sí es un programa cuando reside en el disco del sistema operativo. Cuando se ejecuta en la memoria, el programador es un proceso.
6.9 Multiprocesamiento
Los subprocesos se gestionan casi como procesos. Multiprocesamiento significa ejecutar más de un proceso al mismo tiempo. Hay computadoras con un solo microprocesador. Hay ordenadores con más de un microprocesador. Con un solo microprocesador, los procesos y/o subprocesos utilizan el mismo microprocesador de manera entrelazada (o segmentada en el tiempo). Eso significa que un proceso utiliza el procesador y se detiene sin finalizar. Otro proceso o hilo utiliza el procesador y se detiene sin finalizar. Luego, otro proceso o hilo utiliza el microprocesador y se detiene sin terminar. Esto continúa hasta que todos los procesos y subprocesos que fueron puestos en cola por el programador hayan tenido una parte del procesador. Esto se conoce como multiprocesamiento concurrente.
Cuando hay más de un microprocesador se produce un multiprocesamiento paralelo, a diferencia de la concurrencia. En este caso, cada procesador ejecuta un proceso o subproceso particular, diferente del que ejecuta el otro procesador. Todos los procesadores de una misma placa base ejecutan sus diferentes procesos y/o diferentes subprocesos al mismo tiempo en multiprocesamiento paralelo. El programador todavía gestiona los procesos y subprocesos en multiprocesamiento paralelo. El multiprocesamiento paralelo es más rápido que el multiprocesamiento concurrente.
En este punto, el lector puede preguntarse cómo el procesamiento paralelo es más rápido que el procesamiento concurrente. Esto se debe a que los procesadores comparten (tienen que usar en diferentes momentos) la misma memoria y puertos de entrada/salida. Bueno, con el uso de caché, el funcionamiento general de la placa base es más rápido.
6.10 Localización
La Unidad de Gestión de Memoria (MMU) es un circuito que está cerca del microprocesador o en el chip del microprocesador. Maneja el mapa de memoria o paginación y otros problemas de memoria. Ni el 6502 µP ni el Commodore-64 tienen una MMU per se (aunque todavía hay algo de gestión de memoria en el Commodore-64). El Commodore-64 maneja la memoria paginando donde cada página tiene 256 10 bytes de longitud (100 16 bytes de longitud). No era obligatorio que manejara la memoria mediante paginación. Todavía podría tener simplemente un mapa de memoria y luego programas que simplemente se ajusten a sus diferentes áreas designadas. Bueno, la paginación es una forma de proporcionar un uso eficiente de la memoria sin tener muchas secciones de memoria que no pueden contener datos o programas.
La arquitectura informática x86 386 se lanzó en 1985. El bus de direcciones tiene 32 bits de ancho. Entonces, un total de 2 32 = 4.294.967.296 espacios de direcciones posibles. Este espacio de direcciones se divide en 1.048.576 páginas = páginas de 1.024 KB. Con este número de páginas, una página consta de 4096 bytes = 4 KB. La siguiente tabla muestra las páginas de direcciones físicas para la arquitectura x86 de 32 bits:
| Tabla 6.10.1 Páginas físicas direccionables para la arquitectura x86 |
||
|---|---|---|
| Direcciones de Base 16 | paginas | Direcciones de base 10 |
| FFFFFF000 – FFFFFFFF | Página 1.048.575 | 4,294,963,200 – 4,294,967,295 |
| FFFFFE000 – FFFFEFFF | Página 1.044.479 | 4,294,959,104 – 4,294,963,199 |
| FFFFD000 – FFFFDFFF | Página 1.040.383 | 4,294,955,008 – 4,294,959,103 |
| | | | |
| | | |
| | | |
| 00002000 – 00002FFF | Página 2 | 8,192 – 12,288 |
| 00001000 – 00001FFF | Página 1 | 4,096 – 8,191 |
| 00000000 – 00000FFF | Página 0 | 0 – 4,095 |
Una aplicación hoy consta de más de un programa. Un programa puede ocupar menos de una página (menos de 4096) o puede ocupar dos o más páginas. Por lo tanto, una aplicación puede ocupar una o más páginas, cada una de las cuales tiene una longitud de 4096 bytes. Diferentes personas pueden escribir una solicitud, y a cada persona se le asigna una o más páginas.
Observe que la página 0 es de 00000000H a 00000FFF
la página 1 es de 00001000H a 00001FFFH, la página 2 es de 00002000 h – 00002FFF h , etcétera. Para una computadora de 32 bits, hay dos registros de 32 bits en el procesador para el direccionamiento de páginas físicas: uno para la dirección base y el otro para la dirección de índice. Para acceder a las ubicaciones de bytes de la página 2, por ejemplo, el registro de la dirección base debe ser 00002 h que son los primeros 20 bits (desde la izquierda) para las direcciones iniciales de la página 2. El resto de bits en el rango 000. h a FFF h están en el registro llamado “registro índice”. Entonces, se puede acceder a todos los bytes de la página simplemente incrementando el contenido en el registro de índice desde 000 h a FFF h . El contenido del registro índice se agrega al contenido que no cambia en el registro base para obtener la dirección efectiva. Este esquema de direccionamiento de índice es válido para las demás páginas.
Sin embargo, en realidad no es así como se escribe el programa en lenguaje ensamblador para cada página. Para cada página, el programador escribe el código a partir de la página 000. h a la página FFF h . Dado que el código de diferentes páginas está conectado, el compilador utiliza el direccionamiento de índice para conectar todas las direcciones relacionadas en diferentes páginas. Por ejemplo, suponiendo que la página 0, la página 1 y la página 2 son para una aplicación y cada una tiene el 555 h direcciones que están conectadas entre sí, el compilador compila de tal manera que cuando 555 h de la página 0 se va a acceder, 00000 h estará en el registro base y 555 h estará en el registro índice. Cuando 555 h de la página 1 se debe acceder, 00001 h estará en el registro base y 555 h estará en el registro índice. Cuando 555 h Se debe acceder a la página 2, 00002. h estará en el registro base y 555H estará en el registro índice. Esto es posible porque las direcciones se pueden identificar mediante etiquetas (variables). Los diferentes programadores deben ponerse de acuerdo sobre el nombre de las etiquetas que se utilizarán para las diferentes direcciones de conexión.
Página de memoria virtual
La paginación, como se describió anteriormente, se puede modificar para aumentar el tamaño de la memoria en una técnica que se conoce como 'Memoria virtual de página'. Suponiendo que todas las páginas de memoria física, como se describió anteriormente, tienen algo (instrucciones y datos), no todas las páginas están activas actualmente. Las páginas que no están actualmente activas se envían al disco duro y se reemplazan por las páginas del disco duro que deben estar ejecutándose. De esa forma, aumenta el tamaño de la memoria. A medida que la computadora continúa funcionando, las páginas que quedan inactivas se intercambian con las páginas del disco duro que aún pueden ser las páginas que se enviaron desde la memoria al disco. Todo esto lo realiza la Unidad de Gestión de Memoria (MMU).
6.11 Problemas
Se recomienda al lector que resuelva todos los problemas de un capítulo antes de pasar al siguiente.
1) Indique las similitudes y diferencias de las arquitecturas informáticas CISC y RISC. Nombra un ejemplo de computadora SISC y RISC.
2) a) ¿Cuáles son los siguientes nombres para la computadora CISC en términos de bits: byte, palabra, palabra doble, palabra cuádruple y palabra cuádruple doble?
b) ¿Cuáles son los siguientes nombres para la computadora RISC en términos de bits: byte, media palabra, palabra y palabra doble?
c) Sí o No. ¿Las palabras dobles y cuádruples significan lo mismo en las arquitecturas CISC y RISC?
3 a) Para x64, ¿el número de bytes para las instrucciones en lenguaje ensamblador varía de qué a qué?
b) ¿Es fijo el número de bytes para todas las instrucciones en lenguaje ensamblador para ARM 64? En caso afirmativo, ¿cuál es el número de bytes de todas las instrucciones?
4) Enumere las instrucciones en lenguaje ensamblador más utilizadas para x64 y sus significados.
5) Enumere las instrucciones en lenguaje ensamblador más utilizadas para ARM 64 y sus significados.
6) Dibuje un diagrama de bloques etiquetado de la antigua computadora Harvard Architecture. Explique cómo se utilizan sus instrucciones y características de datos en el caché de las computadoras modernas.
7) Diferenciar entre un proceso y un hilo y dar el nombre del proceso que maneja los procesos y los hilos en la mayoría de los sistemas informáticos.
8) Explique brevemente qué es el multiprocesamiento.
9) a) Explique la paginación según sea aplicable a la arquitectura de computadora x86 386 µP.
b) ¿Cómo se puede modificar esta paginación para aumentar el tamaño de toda la memoria?