5.1 Introducción
El sistema operativo de la computadora Commodore-64 viene con la computadora en memoria de solo lectura (ROM). El número de ubicaciones de bytes de memoria para el Commodore-64 varía de $0000 a $FFFF (es decir, de 000016 a FFFF16, que es de 010 a 65,53510). El sistema operativo va de $E000 a $FFFF (es decir, de 57,34410 a 65,53610).
Por qué estudiar el sistema operativo Commodore-64
¿Por qué estudiar el sistema operativo Commodore-64 hoy cuando era un sistema operativo de una computadora que se lanzó en 1982? Bueno, la computadora Commodore-64 usa la Unidad Central de Procesamiento 6510, que es una actualización (aunque no una gran actualización) del 6502 µP.
El 6502 µP todavía se produce hoy en día en grandes cantidades; ya no es para ordenadores de casa o de oficina sino para aparatos (dispositivos) eléctricos y electrónicos. El 6502 µP también es fácil de entender y operar en comparación con otros microprocesadores de su época. Como resultado de esto, es uno de los mejores (si no el mejor) microprocesador que se utiliza para enseñar el lenguaje ensamblador.
El 65C02 µP, todavía perteneciente a la clase de microprocesador 6502, tiene 66 instrucciones en lenguaje ensamblador, todas las cuales pueden aprenderse incluso de memoria. Los microprocesadores modernos tienen muchas instrucciones en lenguaje ensamblador y no se pueden aprender de memoria. Cada µP tiene su propio lenguaje ensamblador. Cualquier sistema operativo, ya sea nuevo o antiguo, es de lenguaje ensamblador. Con eso, el lenguaje ensamblador 6502 es bueno para enseñar el sistema operativo a principiantes. Después de aprender un sistema operativo, como el del Commodore-64, se puede aprender fácilmente un sistema operativo moderno utilizándolo como base.
Esta no es sólo la opinión del autor (yo mismo). Es una tendencia creciente en el mundo. Cada vez se escriben más artículos en Internet sobre cómo mejorar el sistema operativo Commodore-64 para que parezca un sistema operativo moderno. Los sistemas operativos modernos se explican en el capítulo siguiente al siguiente.
Nota : El sistema operativo Commodore-64 (Kernal) todavía funciona bien con dispositivos de entrada y salida modernos (no con todos).
Computadora de ocho bits
En una microcomputadora de ocho bits como la Commodore 64, la información se almacena, transfiere y manipula en forma de códigos binarios de ocho bits.
Mapa de memoria
Un mapa de memoria es una escala que divide el rango completo de memoria en rangos más pequeños de diferentes tamaños y muestra qué (subrutina y/o variable) pertenece a qué rango. Una variable es una etiqueta que corresponde a una dirección de memoria particular que tiene un valor. Las etiquetas también se utilizan para identificar el inicio de las subrutinas. Pero en este caso se les conoce como los nombres de las subrutinas. A una subrutina se le puede denominar simplemente rutina.
El mapa de memoria (diseño) del capítulo anterior no está lo suficientemente detallado. Es bastante sencillo. El mapa de memoria de la computadora Commodore-64 se puede mostrar con tres niveles de detalle. Cuando se muestra en el nivel intermedio, la computadora Commodore-64 tiene diferentes mapas de memoria. El mapa de memoria predeterminado de la computadora Commodore-64 en el nivel intermedio es:

Fig. 5.11 Mapa de memoria del Commodore-64
En aquellos días, existía un lenguaje informático popular llamado BASIC. Muchos usuarios de computadoras necesitaban conocer algunos comandos mínimos del lenguaje BÁSICO, como cargar un programa desde el disquete (disco) a la memoria, ejecutar (ejecutar) un programa en la memoria y salir (cerrar) un programa. Cuando el programa BASIC se está ejecutando, el usuario tiene que introducir los datos, línea por línea. No es como hoy en día cuando una aplicación (varios programas forman una aplicación) está escrita en un lenguaje de alto nivel con Windows y el usuario sólo tiene que introducir los diferentes datos en lugares especializados de una ventana. En algunos casos, utilizamos un mouse para seleccionar los datos reservados. BASIC era un lenguaje de alto nivel en ese momento, pero está bastante cerca del lenguaje ensamblador.
Observe que BASIC ocupa la mayor parte de la memoria en el mapa de memoria predeterminado. BASIC tiene comandos (instrucciones) que son ejecutados por lo que se conoce como el Intérprete BASIC. De hecho, el intérprete de BASIC está en ROM desde la ubicación $A000 hasta $BFFF (inclusive) que supuestamente es un área de RAM. ¡Estos 8 Kbytes son bastante grandes en ese momento! En realidad, está en ROM en ese lugar de toda la memoria. Tiene el mismo tamaño que el sistema operativo desde $E000 hasta $FFFF (inclusive). Los programas que están escritos en BASIC también se colocan en el rango de $0200 a $BFFF.
La RAM para el programa de usuario en lenguaje ensamblador es de $C000 a $CFFF, sólo 4 Kbytes de 64 Kbytes. Entonces, ¿por qué usamos o aprendemos el lenguaje ensamblador? Los sistemas operativos nuevos y antiguos son de lenguajes ensambladores. El sistema operativo del Commodore-64 está en ROM, desde $E000 hasta $FFFF. Está escrito en el lenguaje ensamblador 65C02 µP (6510 µP). Consta de subrutinas. El programa de usuario en lenguaje ensamblador necesita llamar a estas subrutinas para poder interactuar con los periféricos (dispositivos de entrada y salida). Comprender el sistema operativo Commodore-64 en lenguaje ensamblador permite al estudiante comprender los sistemas operativos rápidamente y de una manera mucho menos tediosa. Nuevamente, en aquellos días, muchos programas de usuario para Commodore-64 estaban escritos en BASIC y no en lenguaje ensamblador. Los lenguajes ensambladores de aquella época eran utilizados más por los propios programadores con fines técnicos.
El Kernal, escrito como K-e-r-n-a-l, es el sistema operativo del Commodore-64. Viene con la computadora Commodore-64 en ROM y no en un disco (o disquete). El Kernal consta de subrutinas. Para acceder a los periféricos, el programa de usuario en lenguaje ensamblador (lenguaje de máquina) debe utilizar estas subrutinas. El Kernal no debe confundirse con el kernel, que se escribe como K-e-r-n-e-l de los sistemas operativos modernos, aunque son casi lo mismo.
El área de memoria de $C000 (49,15210) a $CFFF (6324810) de 4 Kbytes10 de la memoria es RAM o ROM. Cuando es RAM, se utiliza para acceder a los periféricos. Cuando es ROM, se utiliza para imprimir los caracteres de la pantalla (monitor). Esto significa que los caracteres se imprimen en la pantalla o se accede a los periféricos mediante el uso de esta parte de la memoria. Hay un banco de ROM (ROM de caracteres) en la unidad del sistema (placa base) que entra y sale de todo el espacio de memoria para lograrlo. Es posible que el usuario no note el cambio.
El área de memoria de $0100 (256 10 ) a $01FF (511 10 ) es la pila. Lo utilizan tanto el sistema operativo como los programas de usuario. El papel de la pila se explicó en el capítulo anterior de este curso profesional en línea. El área de la memoria desde $0000 (0 10 ) a $00FF (255 10 ) es utilizado por el sistema operativo. Allí se asignan muchas indicaciones.
Mesa de salto Kernal
Kernal tiene rutinas que son llamadas por el programa de usuario. A medida que aparecieron nuevas versiones del sistema operativo, las direcciones de estas rutinas cambiaron. Esto significa que los programas de usuario ya no podrían funcionar con las nuevas versiones del sistema operativo. Esto no sucedió porque Commodore-64 proporcionó una mesa de salto. La tabla de salto es una lista de 39 entradas. Cada entrada en la tabla tiene tres direcciones (excepto los últimos 6 bytes) que nunca cambiaron incluso con el cambio de versión del sistema operativo.
La primera dirección de una entrada tiene una instrucción JSR. Las dos direcciones siguientes constan de un puntero de dos bytes. Este puntero de dos bytes es la dirección (o nueva dirección) de una rutina real que todavía se encuentra en la ROM del sistema operativo. El contenido del puntero podría cambiar con las nuevas versiones del sistema operativo, pero las tres direcciones para cada entrada de la tabla de salto nunca cambian. Por ejemplo, considere las direcciones $FF81, $FF82 y $FF83. Estas tres direcciones son para que la rutina inicialice los circuitos (registros) de pantalla y teclado de la placa base. La dirección $FF81 siempre tiene el código de operación (un byte) de JSR. Las direcciones $FF82 y $FF83 tienen la dirección antigua o nueva de la subrutina (aún en la ROM del sistema operativo) para realizar la inicialización. En un momento, las direcciones $FF82 y $FF83 tenían el contenido (dirección) de $FF5B que podría cambiar con la próxima versión del sistema operativo. Sin embargo, las direcciones $FF81, $FF82 y $FF83 de la tabla de salto nunca cambian.
Para cada entrada de tres direcciones, la primera dirección con JSR tiene una etiqueta (nombre). La etiqueta de $FF81 es PCINT. PCINT nunca cambia. Entonces, para inicializar los registros de pantalla y teclado, el programador puede simplemente escribir 'JSR PCINT', que funciona para todas las versiones del sistema operativo Commodore-64. La ubicación (dirección de inicio) de la subrutina real, por ejemplo, $FF5B, podría cambiar con el tiempo con diferentes sistemas operativos. Sí, hay al menos dos instrucciones JSR involucradas en el programa de usuario que utiliza el sistema operativo ROM. En el programa de usuario hay una instrucción JSR que salta a una entrada en la tabla de salto. Con excepción de las últimas seis direcciones de la tabla de salto, la primera dirección de una entrada en la tabla de salto tiene una instrucción JSR. En el Kernal, algunas subrutinas pueden llamar a otras subrutinas.
La tabla de salto de Kernal comienza desde $FF81 (inclusive) y va hacia arriba en grupos de tres, excepto los últimos seis bytes que son tres punteros con direcciones de bytes inferiores: $FFFA, $FFFC y $FFFE. Todas las rutinas del sistema operativo ROM son códigos reutilizables. Por tanto, el usuario no tiene que reescribirlos.
Diagrama de bloques de la unidad del sistema Commodore-64
El siguiente diagrama es más detallado que el del capítulo anterior:
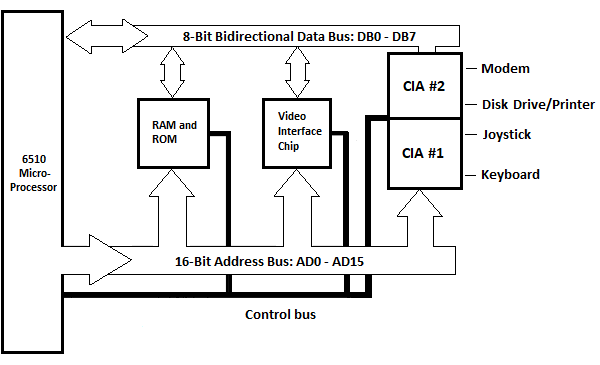
Fig. 5.12 Diagrama de bloques de la unidad del sistema Commodore_64
La ROM y la RAM se muestran aquí como un bloque. Aquí se muestra el chip de interfaz de video (IC) para manejar la información en la pantalla, que no se mostró en el capítulo anterior. El bloque único para dispositivos de entrada/salida, que se muestra en el capítulo anterior, se muestra aquí como dos bloques: CIA #1 y CIA #2. CIA significa Adaptador de interfaz complejo. Cada uno tiene dos puertos paralelos de ocho bits (que no deben confundirse con puertos externos en una superficie vertical de la unidad del sistema) llamados puerto A y puerto B. Los CIA están conectados a cinco dispositivos externos en esta situación. Los dispositivos son el teclado, el joystick, la unidad de disco/impresora y un módem. La impresora está conectada en la parte posterior de la unidad de disco. También hay un circuito de dispositivo de interfaz de sonido y un circuito de matriz lógica programable que no se muestran.
Aún así, hay una ROM de personajes que se puede intercambiar con ambas CIA cuando se envía un personaje a la pantalla y no se muestra en el diagrama de bloques.
Las direcciones RAM de $D000 a $DFFF para circuitos de entrada/salida en ausencia de ROM de caracteres tienen el siguiente mapa de memoria detallado:
| Tabla 5.11 Mapa de memoria detallado de $D000 a $DFFF |
||
|---|---|---|
| Rango de subdirecciones | Circuito | Tamaño (bytes) |
| D000-D3FF | VIC (controlador de interfaz de vídeo (chip)) | 1K |
| D400 – D7FF | SID (Circuito de sonido) | 1K |
| D800 – DBFF | RAM de colores | 1K mordiscos |
| DC00 – DCFF | CIA #1 (teclado, joystick) | 256 |
| DD00 – DDFF | CIA #2 (Bus serie, puerto de usuario/RS-232) | 256 |
| DE00 – DEF | Abrir ranura de E/S n.º 1 | 256 |
| DF00 – DFFF | Abrir ranura de E/S n.º 2 | 256 |
5.2 Los dos adaptadores de interfaz complejos
Hay dos circuitos integrados (CI) particulares en la unidad del sistema Commodore-64, y cada uno de ellos se denomina adaptador de interfaz complejo. Estos dos chips se utilizan para conectar el teclado y otros periféricos al microprocesador. Con excepción del VIC y la pantalla, todas las señales de entrada/salida entre el microprocesador y los periféricos pasan a través de estos dos circuitos integrados. Con el Commodore-64 no existe comunicación directa entre la memoria y ningún periférico. La comunicación entre la memoria y cualquier periférico pasa a través del acumulador del microprocesador, y uno de estos son los adaptadores CIA (IC). Los CI se conocen como CIA #1 y CIA #2. CIA significa Adaptador de interfaz complejo.
Cada CIA tiene 16 registros. Con la excepción de los registros del temporizador/contador en la CIA, cada registro tiene 8 bits de ancho y tiene una dirección de memoria. Las direcciones de registro de memoria para CIA #1 son de $DC00 (56320 10 ) a $DC0F (56335 10 ). Las direcciones de registro de memoria para CIA #2 son de $DD00 (56576 10 ) a $DD0F (56591 10 ). Aunque estos registros no están en la memoria del IC, son parte de la memoria. En el mapa de memoria intermedia, el área de E/S de $D000 a $DFFF incluye las direcciones CIA de $DC00 a $DC0F y de $DD00 a $DD0F. La mayor parte del área de memoria RAM I/O de $D000 a $DFFF se puede intercambiar con el banco de memoria de la ROM de caracteres para caracteres de pantalla. Es por eso que cuando los caracteres son enviados a la pantalla, los periféricos no pueden operar; aunque es posible que el usuario no se dé cuenta de esto ya que el intercambio de ida y vuelta es rápido.
Hay dos registros en CIA #1 llamados Puerto A y Puerto B. Sus direcciones son $DC00 y $DC01, respectivamente. También hay dos registros en CIA #2 llamados Puerto A y Puerto B. Por supuesto, sus direcciones son diferentes; son $DD00 y $DD01, respectivamente.
El puerto A o el puerto B en cualquiera de los CIA es un puerto paralelo. Esto significa que puede enviar datos al periférico en ocho bits a la vez o recibir datos del microprocesador en ocho bits a la vez.
Asociado con el puerto A o el puerto B hay un registro de dirección de datos (DDR). El registro de dirección de datos para el puerto A de CIA #1 (DDRA1) está en la ubicación del byte de memoria $DC02. El registro de dirección de datos para el puerto B de CIA #1 (DDRB1) está en la ubicación del byte de memoria $DC03. El registro de dirección de datos para el puerto A de CIA #2 (DDRA2) está en la ubicación del byte de memoria $DD02. El registro de dirección de datos para el puerto B de CIA #2 (DDRB2) está en la ubicación del byte de memoria $DD03.
Ahora, cada bit para el puerto A o el puerto B puede ser configurado mediante el registro de dirección de datos correspondiente para que sea la entrada o la salida. Entrada significa que la información va desde el periférico al microprocesador a través de una CIA. Salida significa que la información pasa del microprocesador al periférico a través de una CIA.
Si se va a ingresar una celda de un puerto (registro), el bit correspondiente en el registro de dirección de datos es 0. Si se va a generar una celda de un puerto (registro), el bit correspondiente en el registro de dirección de datos es 1. En la mayoría de los casos, los 8 bits de un puerto están programados para ser entrada o salida. Cuando la computadora está encendida, el puerto A está programado para salida y el puerto B está programado para entrada. El siguiente código convierte el puerto A CIA #1 en salida y el puerto B CIA #1 en entrada:
#$FF
STA DDRA1; $DC00 está dirigido por $DC02
LDA#$00
STA DDRB1; $DC01 está dirigido por $DC03
DDRA1 es la etiqueta (nombre de variable) para la ubicación del byte de memoria de $DC02 y DDRB1 es la etiqueta (nombre de variable) para la ubicación del byte de memoria de $DC03. La primera instrucción carga 11111111 al acumulador del µP. La segunda instrucción copia esto al registro de dirección de datos del puerto A del CIA no. 1. La tercera instrucción carga 00000000 al acumulador del µP. La cuarta instrucción copia esto al registro de dirección de datos del puerto B del CIA no. 1. Este código se encuentra en una de las subrutinas del sistema operativo que realiza esta inicialización al encender la computadora.
Cada CIA tiene una línea de solicitud de servicio de interrupción al microprocesador. El de la CIA #1 va al IRQ pin del µP. El de la CIA #2 va al NMI pin del µP. Recuerda eso NMI tiene mayor prioridad que IRQ .
5.3 Programación en lenguaje ensamblador del teclado
Sólo hay tres posibles interrupciones para el Commodore-64: IRQ , BRK y NMI . El puntero de la tabla de salto para IRQ está en las direcciones $FFFE y $FFFF en la ROM (sistema operativo) que corresponde a una subrutina todavía en el SO (ROM). El puntero de la tabla de salto para BRK está en las direcciones $FFFC y $FFFD en el sistema operativo, lo que corresponde a una subrutina que todavía está en el sistema operativo (ROM). El puntero de la tabla de salto para NMI está en las direcciones $FFFA y $FFFB en el sistema operativo que corresponde a una subrutina todavía en el sistema operativo (ROM). Para el IRQ , en realidad hay dos subrutinas. Entonces, la interrupción (instrucción) del software BRK tiene su propio puntero de tabla de salto. El puntero de la tabla de salto para IRQ conduce al código que decide si es la interrupción de hardware o la interrupción de software la que está activada. Si se trata de una interrupción de hardware, la rutina para IRQ se llama. Si se trata de la interrupción de software (BRK), se llama a la rutina para BRK. En una de las versiones del sistema operativo, la subrutina para IRQ está en $EA31 y la subrutina para BRK está en $FE66. Estas direcciones están por debajo de $FF81, por lo que no son entradas de tabla de salto y podrían cambiar según la versión del sistema operativo. Hay tres rutinas de interés en este tema: la que comprueba si es una tecla pulsada o un BRK, la que está en $FE43 y la que también puede cambiar con la versión del SO.
La computadora Commodore-64 tiene la apariencia de una enorme máquina de escribir (hacia arriba) sin la sección de impresión (cabezal y papel). El teclado está conectado a la CIA #1. El CIA #1 escanea el teclado cada 1/60 de segundo por sí solo sin ninguna interferencia de programación, de forma predeterminada. Entonces, cada 1/60 de segundo, la CIA #1 envía un IRQ al µP. Sólo hay uno IRQ pin en el µP que proviene solo de CIA #1. El pin de entrada de NMI del µP, que es diferente de IRQ , proviene únicamente de la CIA #2 (consulte la siguiente ilustración). BRK es en realidad una instrucción en lenguaje ensamblador que está codificada en un programa de usuario.
Entonces, cada 1/60 de segundo, el IRQ Se llama a la rutina a la que apuntan $FFFE y $FFFF. La rutina verifica si se presiona una tecla o si se encuentra la instrucción BRK. Si se presiona una tecla, se llama a la rutina para manejar la pulsación de tecla. Si es una instrucción BRK, se llama a la rutina para manejar BRK. Si no es ninguna de las dos cosas, no pasa nada. Puede que ninguna de las dos cosas ocurra, pero la CIA #1 envía IRQ al µP cada 1/60 segundo.
La cola de teclado, también conocida como búfer de teclado, es un rango de ubicaciones de bytes de RAM desde $0277 hasta $0280, inclusive; 1010 bytes en total. Este es un búfer de primero en entrar, primero en salir. Eso significa que el primer personaje que llega es el primero en irse. Un carácter de Europa occidental ocupa un byte.
Entonces, aunque el programa no consume ningún carácter cuando se presiona una tecla, el código de la tecla va a este búfer (cola). El búfer se sigue llenando hasta que hay diez caracteres. Cualquier carácter que se presione después del décimo carácter no se graba. Se ignora hasta que se obtiene (consume) al menos un carácter de la cola. La tabla de salto tiene una entrada para una subrutina que lleva el primer carácter de la cola al microprocesador. Eso significa que toma ese primer carácter que entra en la cola y lo coloca en el acumulador del µP. La subrutina de la tabla de salto para hacer esto se llama GETIN (para Get-In). El primer byte de la entrada de tres bytes en la tabla de salto está etiquetado como GETIN (dirección $FFE4). Los siguientes dos bytes son el puntero (dirección) que apunta a la rutina real en la ROM (OS). Es responsabilidad del programador llamar a esta rutina. De lo contrario, el búfer del teclado permanecerá lleno y se ignorarán todas las teclas presionadas recientemente. El valor que entra en el acumulador es el valor ASCII de la clave correspondiente.
¿Cómo llegan los códigos clave a la cola en primer lugar? Hay una rutina de tabla de salto llamada SCNKEY (para clave de escaneo). Esta rutina puede ser llamada tanto por software como por hardware. En este caso, es llamado por un circuito electrónico (física) en el microprocesador cuando la señal eléctrica IRQ es bajo. En este curso profesional en línea no se aborda cómo se hace eso exactamente.
El código para obtener el primer código de tecla del búfer del teclado al acumulador A es solo una línea:
ENTRA
Si el búfer del teclado está vacío, se coloca $00 en el acumulador. Recuerde que el código ASCII para cero no es $00; son $30. $00 significa nulo. En un programa, puede haber un punto en el que el programa tenga que esperar a que se presione una tecla. El código para esto es:
ESPERE JSR OBTENER
CMP #$00
ESPERA RANA
En la primera línea, 'WAIT' es una etiqueta que identifica la dirección RAM donde se ingresa (escribe) la instrucción JSR. GETIN también es una dirección. Es la dirección del primero de los tres bytes correspondientes en la tabla de salto. La entrada GETIN, así como todas las entradas de la tabla de salto (excepto las tres últimas), consta de tres bytes. El primer byte de la entrada es la instrucción JSR. Los siguientes dos bytes son la dirección del cuerpo de la subrutina GETIN real que todavía está en la ROM (OS) pero debajo de la tabla de salto. Entonces, la entrada dice que saltemos a la subrutina GETIN. Si la cola del teclado no está vacía, GETIN coloca el código de tecla ASCII de la cola Primero en entrar, primero en salir en el acumulador. Si la cola está vacía, se coloca Null ($00) en el acumulador.
La segunda instrucción compara el valor del acumulador con $00. Si es $00, significa que la cola del teclado está vacía y la instrucción CMP envía 1 al indicador Z del registro de estado del procesador (simplemente llamado registro de estado). Si el valor en A no es $00, la instrucción CMP envía 0 al indicador Z del registro de estado.
La tercera instrucción, que es 'BEQ WAIT', envía el programa de regreso a la primera instrucción si el indicador Z del registro de estado es 1. La primera, segunda y tercera instrucciones se ejecutan repetidamente en orden hasta que se presiona una tecla en el teclado. . Si nunca se presiona una tecla, el ciclo se repite indefinidamente. Un segmento de código como este normalmente se escribe con un segmento de código de tiempo que sale del bucle después de un tiempo si nunca se presiona una tecla (consulte la siguiente discusión).
Nota : El teclado es el dispositivo de entrada predeterminado y la pantalla es el dispositivo de salida predeterminado.
5.4 Canal, número de dispositivo y número de archivo lógico
Los periféricos que utiliza este capítulo para explicar el sistema operativo Commodore-64 son el teclado, la pantalla (monitor), la disquetera con disquete, la impresora y el módem que se conecta a través de la interfaz RS-232C. Para que se produzca la comunicación entre estos dispositivos y la unidad del sistema (microprocesador y memoria) es necesario establecer un canal.
Un canal consta de un búfer, un número de dispositivo, un número de archivo lógico y, opcionalmente, una dirección secundaria. La explicación de estos términos es la siguiente:
Un amortiguador
Observe en la sección anterior que cuando se presiona una tecla, su código debe ir a una ubicación de byte en la RAM de una serie de diez ubicaciones consecutivas. Esta serie de diez ubicaciones es el búfer del teclado. Cada dispositivo de entrada o salida (periférico) tiene una serie de ubicaciones consecutivas en la RAM denominada buffer.
Número del dispositivo
Con el Commodore-64, a cualquier periférico se le asigna un número de dispositivo. La siguiente tabla muestra los diferentes dispositivos y sus números:
| Cuadro 5.41 Números de dispositivo Commodore 64 y sus dispositivos |
|
|---|---|
| Número | Dispositivo |
| 0 | Teclado |
| 1 | Unidad de cinta |
| 2 | Interfaz RS 232C para p.e. un módem |
| 3 | Pantalla |
| 4 | Impresora #1 |
| 5 | Impresora #2 |
| 6 | Trazador #1 |
| 7 | Trazador #2 |
| 8 | Disco duro |
| 9 ¦ ¦ ¦ 30 |
Desde 8 (inclusive) hasta 22 dispositivos de almacenamiento más |
Hay dos tipos de puertos para una computadora. Un tipo es externo, en la superficie vertical de la unidad del sistema. El otro tipo es interno. Este puerto interno es un registro. Commodore-64 tiene cuatro puertos internos: puerto A y puerto B para CIA 1 y puerto A y puerto B para CIA 2. Hay un puerto externo para Commodore-64 que se llama puerto serie. Los dispositivos con el número 3 hacia arriba están conectados al puerto serie. Están conectados en forma de cadena (uno que está conectado detrás del otro), cada uno de los cuales es identificable por su número de dispositivo. Los dispositivos con el número 8 hacia arriba son generalmente los dispositivos de almacenamiento.
Nota : El dispositivo de entrada predeterminado es el teclado con el número de dispositivo 0. El dispositivo de salida predeterminado es la pantalla con el número de dispositivo 3.
Número de archivo lógico
Un número de archivo lógico es un número asignado a un dispositivo (periférico) en el orden en que se abre para acceder a él. Van desde 010 hasta 255 10 .
Dirección secundaria
Imagine que se abren dos archivos (o más de un archivo) en el disco. Para diferenciar entre estos dos archivos, se utilizan las direcciones secundarias. Las direcciones secundarias son números que varían de un dispositivo a otro. El significado de 3 como dirección secundaria para una impresora es diferente del significado de 3 como dirección secundaria para una unidad de disco. El significado depende de características como cuándo se abre un archivo para leer o cuándo se abre un archivo para escribir. Los posibles números secundarios son desde 0. 10 a 15 10 para cada dispositivo. En muchos dispositivos, el número 15 se utiliza para enviar comandos.
Nota : El número de dispositivo también se conoce como dirección de dispositivo y el número secundario también se conoce como dirección secundaria.
Identificación de un objetivo periférico
Para el mapa de memoria predeterminado de Commodore, las direcciones de memoria de $0200 a $02FF (página 2) son utilizadas únicamente por el sistema operativo en ROM (Kernal) y no por el sistema operativo más el lenguaje BASIC. Aunque BASIC aún puede usar las ubicaciones a través del sistema operativo ROM.
El módem y la impresora son dos objetivos periféricos diferentes. Si se abren dos archivos desde el disco, son dos destinos diferentes. Con el mapa de memoria predeterminado, hay tres tablas (listas) consecutivas que pueden verse como una tabla grande. Estas tres tablas contienen la relación entre los números de archivos lógicos, los números de dispositivos y las direcciones secundarias. Con eso, un canal específico o un objetivo de entrada/salida se vuelve identificable. Las tres tablas se denominan tablas de archivos. Las direcciones de RAM y lo que tienen son:
$0259 — $0262: Tabla con etiqueta, LAT, de hasta diez números de archivos lógicos activos.
$0263 — $026C: Tabla con Etiqueta, FAT, de hasta diez números de dispositivo correspondientes.
$026D — $0276: Tabla con Etiqueta, SAT, de diez direcciones secundarias correspondientes.
Aquí, '—' significa 'a', y un número ocupa un byte.
El lector puede preguntarse: '¿Por qué no se incluye el búfer de cada dispositivo al identificar un canal?' Bueno, la respuesta es que con el commodore-64, cada dispositivo externo (periférico) tiene una serie fija de bytes en RAM (mapa de memoria). Sin ningún canal abierto, sus posiciones todavía están ahí en la memoria. El búfer para el teclado, por ejemplo, se fija entre $0277 y $0280 (inclusive) para el mapa de memoria predeterminado.
Las subrutinas Kernal SETLFS y SETNAM
SETLFS y SETNAM son rutinas Kernal. Un canal puede verse como un archivo lógico. Para abrir un canal, se deben generar el número de archivo lógico, el número de dispositivo y una dirección secundaria opcional. También puede ser necesario un nombre de archivo opcional (texto). La rutina SETLFS configura el número de archivo lógico, el número de dispositivo y una dirección secundaria opcional. Estos números se ponen en sus respectivas tablas. La rutina SETNAM configura un nombre de cadena para el archivo que puede ser obligatorio para un canal y opcional para otro canal. Consiste en un puntero (dirección de dos bytes) en la memoria. El puntero apunta al comienzo de la cadena (nombre) que puede estar en otro lugar de la memoria. El nombre de la cadena comienza con un byte que tiene la longitud de la cadena, seguido del texto (nombre). El nombre tiene como máximo dieciséis bytes (de longitud).
Para llamar a la rutina SETLFS, el programa de usuario tiene que saltar (JSR) a la dirección $FFBA de la tabla de salto del sistema operativo en ROM para obtener el mapa de memoria predeterminado. Recuerde que, a excepción de los últimos seis bytes de la tabla de salto, cada entrada consta de tres bytes. El primer byte es la instrucción JSR, que luego salta a la subrutina y comienza en la dirección de los dos bytes siguientes. Para llamar a la rutina SETNAM, el programa de usuario tiene que saltar (JSR) a la dirección $FFBD de la tabla de salto del sistema operativo en la ROM. El uso de estas dos rutinas se muestra en la siguiente discusión.
5.5 Abrir un canal, abrir un archivo lógico, cerrar un archivo lógico y cerrar todos los canales de E/S
Un canal consta de un búfer de memoria, un número de archivo lógico, un número de dispositivo (dirección del dispositivo) y una dirección secundaria opcional (un número). Un archivo lógico (una abstracción) que se identifica mediante un número de archivo lógico puede referirse a un periférico como una impresora, un módem, una unidad de disco, etc. Cada uno de estos diferentes dispositivos debe tener diferentes números de archivo lógico. Hay muchos archivos en el disco. Un archivo lógico también puede hacer referencia a un archivo particular en el disco. Ese archivo en particular también tiene un número de archivo lógico que es diferente al de los periféricos como la impresora o el módem. El número de archivo lógico lo proporciona el programador. Puede ser cualquier número desde 010 ($00) hasta 25510 ($FF).
La rutina OS SETLFS
La rutina OS SETLFS a la que se accede saltando (JSR) a la tabla de salto de OS ROM en $FFBA configura el canal. Debe colocar el número de archivo lógico en la tabla de archivos, que es LAT ($0259 - $0262). Debe colocar el número de dispositivo correspondiente en la tabla de archivos, que es FAT ($0263 — $026C). Si el acceso al archivo (dispositivo) necesita un número secundario, debe colocar la dirección secundaria (número) correspondiente en la tabla de archivos que es SAT ($026D - $0276).
Para funcionar, la subrutina SETLFS necesita obtener el número de archivo lógico del acumulador µP; necesita obtener el número de dispositivo del registro µP X. Si el canal lo necesita, debe obtener la dirección secundaria del registro µP Y.
El número de archivo lógico lo decide el programador. Los números de archivos lógicos que hacen referencia a diferentes dispositivos son diferentes. Ahora, antes de llamar a la rutina SETLFS, el programador debe poner el número del archivo lógico en el acumulador µP. El número de dispositivo se lee de una tabla (documento) como en la Tabla 5.41. El programador también debería introducir el número de dispositivo en el registro µP X. El proveedor de un dispositivo como una impresora, una unidad de disco, etc. proporciona las posibles direcciones secundarias y sus significados para el dispositivo. Si el canal necesita una dirección secundaria, el programador necesita obtenerla del documento que se suministra con el dispositivo (periférico). Si la dirección secundaria (número) es necesaria, el programador debe colocarla en el registro µP Y antes de llamar a la subrutina SETLFS. Si no hay necesidad de una dirección secundaria, el programador tiene que poner el número $FF en el registro µP Y antes de llamar a la subrutina SETLFS.
La subrutina SETLFS se llama sin ningún argumento. Sus argumentos ya están en los tres registros del 6502 µP. Después de poner los números apropiados en los registros, la rutina se llama en el programa simplemente con lo siguiente en una línea separada:
JSR SETLFS
La rutina coloca los diferentes números apropiadamente en sus tablas de archivos.
La rutina SETNAM del sistema operativo
Se accede a la rutina OS SETNAM saltando (JSR) a la tabla de salto de OS ROM en $FFBD. No todos los destinos tienen nombres de archivos. Para aquellos que tienen destinos (como los archivos en el disco), se debe configurar el nombre del archivo. Supongamos que el nombre del archivo es 'mydocum', que consta de 7 bytes sin comillas. Supongamos que este nombre está en las ubicaciones $C101 a $C107 (inclusive) y la longitud de $07 está en la ubicación $C100. La dirección inicial de los caracteres de la cadena es $C101. El byte inferior de la dirección inicial es $01 y el byte superior es $C1.
Antes de llamar a la rutina SETNAM, el programador tiene que poner el número $07 (longitud de la cadena) en el acumulador µP. El byte inferior de la dirección inicial de la cadena $01 se coloca en el registro µP X. El byte superior de la dirección inicial de la cadena $C1 se coloca en el registro µP Y. La subrutina se llama simplemente con lo siguiente:
JSR SETNAM
La rutina SETNAM asocia los valores de los tres registros con el canal. No es necesario que los valores permanezcan en los registros después de eso. Si el canal no necesita un nombre de archivo, el programador tiene que poner $00 en el acumulador µP. En este caso, se ignoran los valores que están en los registros X e Y.
La rutina OS OPEN
Se accede a la rutina OS OPEN saltando (JSR) a la tabla de salto de OS ROM en $FFC0. Esta rutina utiliza el número de archivo lógico, el número de dispositivo (y el búfer), una posible dirección secundaria y un posible nombre de archivo para proporcionar una conexión entre la computadora commodore y el archivo en el dispositivo externo o el dispositivo externo mismo.
Esta rutina, como todas las demás rutinas ROM de Commodore OS, no admite discusión. Aunque utiliza los registros µP, ninguno de los registros tuvo que estar precargado con argumentos (valores) para ello. Para codificarlo, simplemente escriba lo siguiente después de llamar a SETLFS y SETNAM:
JSR ABIERTO
Pueden ocurrir errores con la rutina OPEN. Por ejemplo, es posible que no se pueda encontrar el archivo para leerlo. Cuando ocurre un error, la rutina falla y coloca el número de error correspondiente en el acumulador µP y establece el indicador de acarreo (a 1) del registro de estado µP. La siguiente tabla proporciona los números de error y sus significados:
| Cuadro 5.51 Números de error del kernel y sus significados para la rutina OPEN de ROM del sistema operativo |
||
|---|---|---|
| Numero erroneo | Descripción | Ejemplo |
| 1 | DEMASIADOS ARCHIVOS | ABRIR cuando ya se hayan abierto diez archivos |
| 2 | ARCHIVO ABRIR | ABIERTO 1,3: ABIERTO 1,4 |
| 3 | ARCHIVO NO ABIERTO | IMPRIMIR#5 sin ABRIR |
| 4 | ARCHIVO NO ENCONTRADO | CARGAR “NO EXISTENTE”,8 |
| 5 | DISPOSITIVO NO PRESENTE | ABIERTO 11,11: IMPRESIÓN#11 |
| 6 | NO ENTRAR ARCHIVO | ABRIR “SEQ,S,W”: OBTENER#8,X$ |
| 7 | ARCHIVO NO SALIDA | ABRIR 1,0: IMPRIMIR#1 |
| 8 | NOMBRE DE ARCHIVO FALTANTE | CARGAR “”,8 |
| 9 | ILLEGAL DEVICE NO. | CARGAR “PROGRAMA”,3 |
Esta tabla se presenta de una manera que el lector probablemente verá en muchos otros lugares.
La rutina OS CHKIN
Se accede a la rutina OS CHKIN saltando (JSR) a la tabla de salto de OS ROM en $FFC6. Después de abrir un archivo (archivo lógico), hay que decidir si la apertura es para entrada o salida. La rutina CHKIN realiza la apertura de un canal de entrada. Esta rutina necesita leer el número de archivo lógico del registro µP X. Entonces, el programador tiene que poner el número de archivo lógico en el registro X antes de llamar a esta rutina. Se llama simplemente como:
JSR CHKIN
La rutina CHKOUT del sistema operativo
Se accede a la rutina OS CHKOUT saltando (JSR) a la tabla de salto de OS ROM en $FFC9. Después de abrir un archivo (archivo lógico), hay que decidir si la apertura es para entrada o salida. La rutina CHKOUT realiza la apertura de un canal de salida. Esta rutina necesita leer el número de archivo lógico del registro µP X. Entonces, el programador tiene que poner el número de archivo lógico en el registro X antes de llamar a esta rutina. Se llama simplemente como:
JSR CHKOUT
La rutina de cierre del sistema operativo
Se accede a la rutina OS CLOSE saltando (JSR) a la tabla de salto de OS ROM en $FFC3. Después de abrir un archivo lógico y transmitir los bytes, se debe cerrar el archivo lógico. Cerrar el archivo lógico libera el búfer en la unidad del sistema para que lo utilice algún otro archivo lógico que aún esté por abrir. También se eliminan los parámetros correspondientes en las tres tablas de archivos. La ubicación de RAM para el número de archivos abiertos se reduce en 1.
Cuando se enciende la computadora, se reinicia el hardware del microprocesador y otros chips principales (circuitos integrados) en la placa base. A esto le sigue la inicialización de algunas ubicaciones de memoria RAM y algunos registros en algunos chips de la placa base. En el proceso de inicialización, la ubicación de la memoria de bytes de la dirección $0098 en la página cero se proporciona con la etiqueta NFILES o LDTND, según la versión del sistema operativo. Mientras la computadora está en funcionamiento, esta ubicación de un byte de 8 bits contiene la cantidad de archivos lógicos que se abren y el índice de dirección inicial de las tres tablas de archivos consecutivas. En otras palabras, este byte tiene el número de archivos abiertos que se reduce en 1 cuando se cierra el archivo lógico. Cuando se cierra el archivo lógico, ya no es posible el acceso al dispositivo terminal (destino) o al archivo real en el disco.
Para cerrar un archivo lógico, el programador debe colocar el número del archivo lógico en el acumulador µP. Este es el mismo número de archivo lógico que se utiliza para abrir el archivo. La rutina CLOSE lo necesita para cerrar ese archivo en particular. Al igual que otras rutinas de ROM del sistema operativo, la rutina CLOSE no acepta un argumento, aunque el valor que se utiliza del acumulador es en cierto modo un argumento. La línea de instrucciones en lenguaje ensamblador es simplemente:
JSR CERRAR
Las subrutinas (rutinas) del lenguaje ensamblador 6502 personalizadas o predefinidas no toman argumentos. Sin embargo, los argumentos vienen de manera informal al poner los valores que utilizará la subrutina en los registros del microprocesador.
La rutina CLRCHN
Se accede a la rutina OS CLRCHN saltando (JSR) a la tabla de salto de OS ROM en $FFCC. CLRCHN significa canal claro. Cuando se cierra un archivo lógico, se eliminan sus parámetros de número de archivo lógico, número de dispositivo y posible dirección secundaria. Entonces, se borra el canal para el archivo lógico.
El manual dice que la rutina OS CLRCHN borra todos los canales abiertos y restaura los números de dispositivo predeterminados y otros valores predeterminados. ¿Significa esto que se puede cambiar el número de dispositivo de un periférico? Bueno, no del todo. Durante la inicialización del sistema operativo, la ubicación del byte de la dirección $0099 se proporciona con la etiqueta DFLTI para contener el número de dispositivo de entrada actual cuando la computadora está en funcionamiento. El comodoro-64 sólo puede acceder a un periférico a la vez. Durante la inicialización del sistema operativo, la ubicación del byte de la dirección $009A se proporciona con la etiqueta DFLTO para contener el número de dispositivo de salida actual cuando la computadora está en funcionamiento.
Cuando se llama a la subrutina CLRCHN, establece la variable DFLTI en 0 ($00), que es el número de dispositivo de entrada predeterminado (teclado). Establece la variable DFLTO en 3 ($03), que es el número de dispositivo de salida predeterminado (pantalla). Otras variables de número de dispositivo se restablecen de manera similar. Ese es el significado de restablecer (o restaurar) los dispositivos de entrada/salida a la normalidad (valores predeterminados).
El manual del Commodore-64 dice que después de llamar a la rutina CLRCHN, los archivos lógicos abiertos permanecen abiertos y aún pueden transmitir los bytes (datos). Esto significa que la rutina CLRCHN no elimina las entradas correspondientes en las tablas de archivos. El nombre CLRCHN es bastante ambiguo en cuanto a su significado.
5.6 Envío del personaje a la pantalla
El circuito integrado principal (IC) para manejar la visualización de caracteres y gráficos en la pantalla se llama Controlador de interfaz de video (chip), que se abrevia como VIC en el Commodore-64 (en realidad, VIC II para VIC versión 2). Para que una información (valores) vaya a la pantalla, tiene que pasar por VIC II antes de llegar a la pantalla.
La pantalla consta de 25 filas y 40 columnas de celdas de caracteres. Esto hace 40 x 25 = 1000 caracteres que se pueden mostrar en la pantalla. El VIC II lee las correspondientes ubicaciones de bytes consecutivos de la memoria RAM de 1000 para caracteres. Estas 1000 ubicaciones juntas se conocen como memoria de pantalla. Lo que entra en estas 1000 ubicaciones son los códigos de caracteres. Para el Commodore-64, los códigos de caracteres son diferentes de los códigos ASCII.
Un código de carácter no es un patrón de caracteres. También existe lo que se conoce como ROM de caracteres. La ROM de caracteres consta de todo tipo de patrones de caracteres, algunos de los cuales corresponden a los patrones de caracteres del teclado. La ROM de caracteres es diferente de la memoria de pantalla. Cuando se va a mostrar un carácter en la pantalla, el código de carácter se envía a una posición entre las 1000 posiciones de la memoria de la pantalla. A partir de ahí, se selecciona el patrón correspondiente de la ROM de caracteres que se va a mostrar en pantalla. La elección del patrón correcto en la ROM de caracteres a partir de un código de caracteres se realiza mediante VIC II (hardware).
Muchas ubicaciones de memoria entre $D000 y $DFFF tienen dos propósitos: se usan para manejar operaciones de entrada/salida distintas a la pantalla o se usan como ROM de caracteres para la pantalla. Se trata de dos bloques de memoria. Uno es RAM y el otro es ROM para ROM de caracteres. El intercambio de bancos para manejar la entrada/salida o los patrones de caracteres (ROM de caracteres) se realiza mediante software (rutina del SO en ROM de $F000 a $FFFF).
Nota : El VIC tiene registros que están direccionados con direcciones del espacio de memoria dentro del rango de $D000 y $DFFF.
La rutina CHROUT
Se accede a la rutina OS CHROUT saltando (JSR) a la tabla de salto de OS ROM en $FFD2. Esta rutina, cuando se llama, toma el byte que el programador ha puesto en el acumulador µP y lo imprime en la pantalla donde está el cursor. El segmento de código para imprimir el carácter “E”, por ejemplo, es:
LDA#$05
CROUT
El 0516 no es el código ASCII para “E”. El Commodore-64 tiene sus propios códigos de caracteres para la pantalla donde $05 significa “E”. El número #$05 se coloca en la memoria de la pantalla antes de que VIC lo envíe a la pantalla. Estas dos líneas de codificación deberían aparecer después de configurar el canal, abrir el archivo lógico y llamar a la rutina CHKOUT para la salida. El código completo es:
; Canal de configuración
LDA#$40; número de archivo lógico
LDX#$03; El número de dispositivo para la pantalla es $03.
LDY#$FF; sin dirección secundaria
JSR SETLFS ; canal de configuración adecuado
; no SETNAM ya que la pantalla no necesita un nombre
;
; Abrir archivo lógico
JSR ABIERTO
; Establecer canal para salida
LDX #$40; número de archivo lógico
JSR CHKOUT
;
; Carácter de salida a la pantalla
LDA#$05
JSR CROUT
; Cerrar archivo lógico
LDA#$40
JSR CERRAR
La apertura debe cerrarse antes de ejecutar otro programa. Supongamos que el usuario de la computadora escribe un carácter en el teclado cuando se espera. El siguiente programa imprime un carácter del teclado en la pantalla:
; Canal de configuración
LDA#$40; número de archivo lógico
LDX#$03; El número de dispositivo para la pantalla es $03.
LDY#$FF; sin dirección secundaria
JSR SETLFS ; canal de configuración adecuado
; no SETNAM ya que la pantalla no necesita un nombre
;
; Abrir archivo lógico
JSR ABIERTO
; Establecer canal para salida
LDX #$40; número de archivo lógico
JSR CHKOUT
;
; Ingrese caracteres desde el teclado
ESPERE JSR OBTENER; pone $00 en A si la cola del teclado está vacía
CMP#$00; Si $00 fueron a A, entonces Z es 1 con la comparación
BEQ ESPERA ; OBTENER de la cola nuevamente si 0 fue al acumulador
BNE PRNSCRN ; vaya a PRNSCRN si Z es 0, porque A ya no tiene $00
; Carácter de salida a la pantalla
PRNSCRN JSR CHROUT ; enviar el carácter en A a la pantalla
; Cerrar archivo lógico
LDA#$40
JSR CERRAR
Nota : WAIT y PRNSCRN son las etiquetas que identifican las direcciones. El byte del teclado que llega al acumulador µP es un código ASCII. El código correspondiente que Commodore-64 enviará a la pantalla tiene que ser diferente. Esto no se tiene en cuenta en el programa anterior por motivos de simplicidad.
5.7 Envío y recepción de bytes para la unidad de disco
Hay dos adaptadores de interfaz complejos en la unidad del sistema (placa base) del Commodore-64 llamados VIA #1 y CIA #2. Cada CIA tiene dos puertos paralelos que se denominan Puerto A y Puerto B. Hay un puerto externo en la superficie vertical en la parte posterior de la unidad del sistema Commodre-64 que se denomina puerto serie. Este puerto tiene 6 pines, uno de los cuales es para datos. Los datos entran o salen de la unidad del sistema en serie, un bit a la vez.
Ocho bits paralelos del puerto interno A del CIA #2, por ejemplo, pueden salir de la unidad del sistema a través del puerto serial externo después de ser convertidos en datos seriales mediante un registro de desplazamiento en el CIA. Los datos seriales de ocho bits del puerto serial externo pueden ir al puerto interno A de CIA #2 después de ser convertidos en datos paralelos mediante un registro de desplazamiento en el CIA.
La unidad del sistema Commodore-64 (unidad base) utiliza una unidad de disco externa con un disquete. Se puede conectar una impresora a esta unidad de disco en forma de cadena tipo margarita (conectando dispositivos en serie como una cadena). El cable de datos para la unidad de disco está conectado al puerto serie externo de la unidad del sistema Commodore-64. Esto significa que una impresora en cadena también está conectada al mismo puerto serie. Estos dos dispositivos se identifican mediante dos números de dispositivo diferentes (normalmente 8 y 4, respectivamente).
El envío o recepción de datos para la unidad de disco sigue el mismo procedimiento descrito anteriormente. Eso es:
- Establecer el nombre del archivo lógico (número) que es el mismo que el del archivo de disco real usando la rutina SETNAM.
- Abrir el archivo lógico usando la rutina OPEN.
- Decidir si es entrada o salida mediante la rutina CHKOUT o CHKIN.
- Enviar o recibir datos mediante la instrucción STA y/o LDA.
- Cerrar el archivo lógico mediante la rutina CLOSE.
El archivo lógico debe estar cerrado. Cerrar el archivo lógico cierra efectivamente ese canal en particular. Al configurar el canal para la unidad de disco, el programador decide el número de archivo lógico. Es un número entre $00 y $FF (inclusive). No debe ser un número que ya haya sido elegido para ningún otro dispositivo (o archivo real). El número de dispositivo es 8 si solo hay una unidad de disco. La dirección secundaria (número) se obtiene del manual de la unidad de disco. El siguiente programa utiliza 2. El programa escribe la letra 'E' (ASCII) en un archivo en el disco llamado 'mydoc.doc'. Se supone que este nombre comienza en la dirección de memoria $C101. Entonces, el byte inferior de $01 tiene que estar en el registro X y el byte superior de $C1 tiene que estar en el registro Y antes de que se llame a la rutina SETNAM. El registro A también debe tener el número $09 antes de llamar a la rutina SETNAM.
; Canal de configuración
LDA#$40; número de archivo lógico
LDX#$08; número de dispositivo para la primera unidad de disco
LDY #$02; dirección secundaria
JSR SETLFS ; canal de configuración adecuado
;
; El archivo en la unidad de disco necesita un nombre (ya en la memoria)
LDA#$09
LDX#$01
LDY#$C1
JSR SETNAM
; Abrir archivo lógico
JSR ABIERTO
; Establecer canal para salida
LDX #$40; número de archivo lógico
JSR CHKOUT ;para escribir
;
; Carácter de salida al disco
LDA#$45
JSR CROUT
; Cerrar archivo lógico
LDA#$40
JSR CERRAR
Para leer un byte del disco en el registro µP Y, repita el programa anterior con los siguientes cambios: En lugar de “JSR CHKOUT; para escribir”, utilice “JSR CHKIN; para leer'. Reemplace el segmento de código por “; Salida char al disco” con lo siguiente:
; Carbón de entrada desde el disco
JSR CHRIS
Se accede a la rutina OS CHRIN saltando (JSR) a la tabla de salto de OS ROM en $FFCF. Esta rutina, cuando se llama, obtiene un byte de un canal que ya está configurado como canal de entrada y lo coloca en el registro µP A. La rutina GETIN ROM OS también se puede utilizar en lugar de CHRIN.
Enviar un byte a la impresora
El envío de un byte a la impresora se realiza de forma similar a enviar un byte a un archivo en el disco.
5.8 La rutina SAVE del sistema operativo
Se accede a la rutina OS SAVE saltando (JSR) a la tabla de salto de OS ROM en $FFD8. La rutina OS SAVE en ROM guarda (vuelca) una sección de la memoria en el disco como un archivo (con un nombre). Es necesario conocer la dirección inicial de la sección en la memoria. También es necesario conocer la dirección final de la sección. El byte inferior de la dirección inicial se coloca en la página cero de la RAM en la dirección $002B. El byte superior de la dirección inicial se coloca en la ubicación de memoria del siguiente byte en la dirección $002C. En la página cero, la etiqueta TXTTAB se refiere a estas dos direcciones, aunque TXTTAB en realidad significa la dirección $002B. El byte inferior de la dirección final se coloca en el registro µP X. El byte mayor de la dirección final más 1 se coloca en el registro µP Y. El registro µP A toma el valor de $2B para TXTTAB ($002B). Con eso, la rutina SAVE se puede llamar con lo siguiente:
JSR GUARDAR
La sección de la memoria a guardar puede ser un programa en lenguaje ensamblador o un documento. Un ejemplo de documento puede ser una carta o un ensayo. Para utilizar la rutina de guardado se debe seguir el siguiente procedimiento:
- Configure el canal usando la rutina SETLFS.
- Establezca el nombre del archivo lógico (número) que sea el mismo que el del archivo de disco real usando la rutina SETNAM.
- Abra el archivo lógico usando la rutina OPEN.
- Conviértalo en un archivo para la salida usando CHKOUT.
- El código para guardar el archivo va aquí y termina con 'JSR SAVE'.
- Cierre el archivo lógico usando la rutina CLOSE.
El siguiente programa guarda un archivo que comienza en las ubicaciones de memoria de $C101 a $C200:
; Canal de configuración
LDA#$40; número de archivo lógico
LDX#$08; número de dispositivo para la primera unidad de disco
LDY #$02; dirección secundaria
JSR SETLFS ; canal de configuración adecuado
;
; Nombre del archivo en la unidad de disco (ya en la memoria a $C301)
LDA#$09; longitud del nombre del archivo
LDX#$01
LDY#$C3
JSR SETNAM
; Abrir archivo lógico
JSR ABIERTO
; Establecer canal para salida
LDX #$40; número de archivo lógico
JSR CHKOUT ; para la escritura
;
; Archivo de salida al disco
LDA#$01
STA $2 mil millones; TXTTAB
LDA#$C1
ESTA $2C
LDX #$00
LDY#$C2
LDA #$2 mil millones
JSR GUARDAR
; Cerrar archivo lógico
LDA#$40
JSR CERRAR
Tenga en cuenta que este es un programa que guarda otra sección de la memoria (no la sección del programa) en un disco (disquete para Commodore-64).
5.9 La rutina de carga del sistema operativo
Se accede a la rutina OS LOAD saltando (JSR) a la tabla de salto de OS ROM en $FFD5. Cuando una sección (área grande) de la memoria se guarda en el disco, se guarda con un encabezado que tiene la dirección inicial de la sección en la memoria. La subrutina OS LOAD carga los bytes de un archivo en la memoria. Con esta operación LOAD el valor del acumulador tiene que ser 010 ($00). Para que la operación LOAD lea la dirección inicial en el encabezado del archivo en el disco y coloque los bytes del archivo en la RAM a partir de esa dirección, la dirección secundaria para el canal debe ser 1 o 2 (el siguiente programa usa 2). Esta rutina devuelve la dirección más 1 de la ubicación de RAM más alta que está cargada. Esto significa que el byte bajo de la última dirección del archivo en la RAM más 1 se coloca en el registro µP X, y el byte alto de la última dirección del archivo en la RAM más 1 se coloca en el registro µP Y.
Si la carga no tiene éxito, el registro µP A contiene el número de error (posiblemente 4, 5, 8 o 9). También se establece la bandera C del registro de estado del microprocesador (se convierte en 1). Si la carga se realiza correctamente, el último valor del registro A no es importante.
Ahora, en el capítulo anterior de este curso profesional en línea, la primera instrucción del programa en lenguaje ensamblador está en la dirección en la RAM donde comenzó el programa. No tiene por qué ser así. Esto significa que la primera instrucción de un programa no tiene por qué estar al principio del programa en la RAM. La instrucción de inicio de un programa puede estar en cualquier lugar dentro del archivo en la RAM. Se recomienda al programador etiquetar el inicio de la instrucción en lenguaje ensamblador con START. Con eso, después de cargar el programa, se vuelve a ejecutar (ejecuta) con la siguiente instrucción en lenguaje ensamblador:
INICIO JSR
“JSR START” está en el programa en lenguaje ensamblador que carga el programa a ejecutar. Un lenguaje ensamblador que carga otro archivo en lenguaje ensamblador y ejecuta el archivo cargado tiene el siguiente procedimiento de código:
- Configure el canal usando la rutina SETLFS.
- Establezca el nombre del archivo lógico (número) que sea el mismo que el del archivo de disco real usando la rutina SETNAM.
- Abra el archivo lógico usando la rutina OPEN.
- Conviértalo en el archivo para entrada usando CHKIN.
- El código para cargar el archivo va aquí y termina con “JSR LOAD”.
- Cierre el archivo lógico usando la rutina CLOSE.
El siguiente programa carga un archivo del disco y lo ejecuta:
; Canal de configuración
LDA#$40; número de archivo lógico
LDX#$08; número de dispositivo para la primera unidad de disco
LDY #$02; dirección secundaria
JSR SETLFS ; canal de configuración adecuado
;
; Nombre del archivo en la unidad de disco (ya en la memoria a $C301)
LDA#$09; longitud del nombre del archivo
LDX#$01
LDY#$C3
JSR SETNAM
; Abrir archivo lógico
JSR ABIERTO
; Establecer canal para entrada
LDX #$40; número de archivo lógico
JSR CHKIN ; para leer
;
; Archivo de entrada desde el disco
LDA#$00
CARGA JSR
; Cerrar archivo lógico
LDA#$40
JSR CERRAR
; Iniciar programa cargado
INICIO JSR
5.10 El módem y el estándar RS-232
El módem es un dispositivo (periférico) que convierte los bits de la computadora en las correspondientes señales eléctricas de audio para ser transmitidas a través de la línea telefónica. En el extremo receptor, hay un módem antes de una computadora receptora. Este segundo módem convierte las señales de audio eléctricas en bits para la computadora receptora.
Un módem debe estar conectado a una computadora en un puerto externo (en la superficie vertical de la computadora). El estándar RS-232 se refiere a un tipo particular de conector que conecta un módem a la computadora (en el pasado). En otras palabras, muchas computadoras en el pasado tenían un puerto externo que era un conector RS-232 o un conector compatible con RS-232.
La unidad del sistema Commodore-64 (computadora) tiene un puerto externo en su superficie vertical posterior que se llama puerto de usuario. Este puerto de usuario es compatible con RS-232. Allí se puede conectar un dispositivo módem. El Commodore-64 se comunica con un módem a través de este puerto de usuario. El sistema operativo ROM del Commodore-64 tiene subrutinas para comunicarse con un módem llamadas rutinas RS-232. Estas rutinas tienen entradas en la tabla de salto.
Velocidad de baudios
El byte de ocho bits de la computadora se convierte en una serie de ocho bits antes de enviarse al módem. Lo contrario se hace desde el módem a la computadora. La velocidad en baudios es la cantidad de bits que se transmiten por segundo, en serie.
Fondo de la memoria
El término 'Parte inferior de la memoria' no se refiere a la ubicación del byte de memoria de la dirección $0000. Se refiere a la ubicación de RAM más baja donde el usuario puede comenzar a colocar sus datos y programas. Por defecto, es $0800. Recuerde de la discusión anterior que muchas de las ubicaciones entre $0800 y $BFFF son utilizadas por el lenguaje informático BASIC y sus programadores (usuarios). Sólo quedan las direcciones de $C000 a $CFFF para su uso con los programas y datos en lenguaje ensamblador; esto son 4 Kbytes de los 64 Kbytes de la memoria.
Parte superior de la memoria
En aquellos días, cuando los clientes compraban las computadoras Commodore-64, algunas no venían con todas las ubicaciones de memoria. Estas computadoras tenían ROM con su sistema operativo de $E000 a $FFFF. Tenían RAM desde $0000 hasta un límite, que no es $DFFF, al lado de $E000. El límite estaba por debajo de $DFFF y ese límite se llama 'Top of Memory'. Por lo tanto, la parte superior de la memoria no se refiere a la ubicación $FFFF.
Búfers Commodore-64 para comunicación RS-232
Búfer de transmisión
El buffer para la transmisión RS-232 (salida) ocupa 256 bytes desde la parte superior de la memoria hacia abajo. El puntero de este búfer de transmisión está etiquetado como ROBUF. Este puntero está en la página cero con las direcciones $00F9 seguidas de $00FA. ROBUF en realidad identifica $00F9. Entonces, si la dirección para el inicio del búfer es $BE00, el byte inferior de $BE00, que es $00, está en la ubicación $00F9 y el byte superior de $BE00, que es $BE, está en la ubicación $00FA. ubicación.
Búfer de recepción
El buffer para recibir los bytes RS-232 (entrada) toma 256 bytes del fondo del buffer de transmisión. El puntero de este búfer de recepción está etiquetado como RIBUF. Este puntero está en la página cero con las direcciones $00F7 seguidas de $00F8. RIBUF en realidad identifica $00F7. Entonces, si la dirección para el inicio del búfer es $BF00, el byte inferior de $BF00, que es $00, está en la ubicación $00F7 y el byte superior de $BF00, que es $BF, está en la ubicación $00F8. ubicación. Por lo tanto, se utilizan 512 bytes de la parte superior de la memoria como búfer RAM RS-232 total.
Canal RS-232
Cuando se conecta un módem al puerto de usuario (externo), la comunicación con el módem es solo comunicación RS-232. El procedimiento para tener un canal RS-232 completo es casi el mismo que en la discusión anterior, pero con una diferencia importante: el nombre del archivo es un código y no una cadena en la memoria. El código $0610 es una buena opción. Significa una velocidad de transmisión de 300 bits/seg y algunos otros parámetros técnicos. Además, no existe una dirección secundaria. Tenga en cuenta que el número de dispositivo es 2. El procedimiento para configurar un canal RS-232 completo es:
- Configuración del canal mediante la rutina SETLFS.
- Estableciendo el nombre del archivo lógico, $0610.
- Abrir el archivo lógico usando la rutina OPEN.
- Convirtiéndolo en el archivo para salida usando CHKOUT o archivo para entrada usando CHKIN.
- Enviar los bytes individuales con CHROUT o recibir los bytes individuales con GETIN.
- Cerrar el archivo lógico mediante la rutina CLOSE.
Se accede a la rutina OS GETIN saltando (JSR) a la tabla de salto de OS ROM en $FFE4. Esta rutina, cuando se llama, toma el byte que se envía al búfer del receptor y lo coloca (devuelve) en el acumulador µP.
El siguiente programa envía el byte “E” (ASCII) al módem que está conectado al puerto compatible RS-232 del usuario:
; Canal de configuración
LDA#$40; número de archivo lógico
LDX#$02; número de dispositivo para RS-232
LDY#$FF; sin dirección secundaria
JSR SETLFS ; canal de configuración adecuado
;
; El nombre de RS-232 es un código, p. $0610
LDA#$02; La longitud del código es de 2 bytes.
LDX #$10
LDY#$06
JSR SETNAM
;
; Abrir archivo lógico
JSR ABIERTO
; Establecer canal para salida
LDX #$40; número de archivo lógico
JSR CHKOUT
;
; Carácter de salida a RS-232, p. módem
LDA#$45
JSR CROUT
; Cerrar archivo lógico
LDA#$40
JSR CERRAR
Para recibir un byte, el código es muy similar, excepto que “JSR CHKOUT” se reemplaza por “JSR CHKIN” y:
LDA#$45
JSR CROUT
se reemplaza por 'JSR GETIN' y el resultado se coloca en el registro A.
El envío o recepción continua de bytes se realiza mediante un bucle para el envío o recepción de segmento de código, respectivamente.
Tenga en cuenta que la entrada y salida con Commodore es similar en la mayoría de los casos, excepto en el teclado, donde algunas de las rutinas no son llamadas por el programador, pero sí por el sistema operativo.
5.11 Conteo y sincronización
Considere la secuencia de cuenta regresiva que es:
2, 1, 0
Esta es una cuenta regresiva de 2 a 0. Ahora, considere la secuencia repetitiva de cuenta regresiva:
2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0
Esta es la cuenta regresiva repetida de la misma secuencia. La secuencia se repite cuatro veces. Cuatro veces significa que el tiempo es 4. Dentro de una secuencia se cuenta. Repetir la misma secuencia es cronometrar.
Hay dos adaptadores de interfaz complejos en la unidad del sistema del Commodore-64. Cada CIA tiene dos circuitos contadores/temporizadores denominados Temporizador A (TA) y Temporizador B (TB). El circuito de conteo no es diferente del circuito de cronometraje. El contador o cronómetro del Commodore-64 se refiere a lo mismo. De hecho, cualquiera de ellos se refiere esencialmente a un registro de 16 bits que siempre cuenta atrás hasta 0 en los pulsos del reloj del sistema. Se pueden establecer diferentes valores en el registro de 16 bits. Cuanto mayor sea el valor, más tiempo llevará la cuenta regresiva hasta cero. Cada vez que uno de los temporizadores pasa de cero, el IRQ La señal de interrupción se envía al microprocesador. Cuando el conteo pasa de cero, se llama desbordamiento insuficiente.
Dependiendo de cómo esté programado el circuito del temporizador, un temporizador puede funcionar en modo único o en modo continuo. En la ilustración anterior, el modo de una sola vez significa 'hacer 2, 1, 0' y detenerse mientras continúan los pulsos del reloj. El modo continuo es como “2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0, etc.” que continúa con los pulsos del reloj. Eso significa que cuando pasa de cero, si no se da ninguna instrucción, la secuencia de cuenta regresiva se repite. El número mayor suele ser mucho mayor que 2.
El temporizador A (TA) de la CIA #1 genera IRQ a intervalos regulares (duraciones) para reparar el teclado. De hecho, esto es cada 1/60 de segundo de forma predeterminada. IRQ se envía al microprocesador cada 1/60 de segundo. es solo cuando IRQ Se envía que un programa puede leer un valor clave de la cola del teclado (búfer). Recuerde que el microprocesador tiene un solo pin para el IRQ señal. El microprocesador también tiene un solo pin para el NMI señal. La señal ¯NMI al microprocesador siempre proviene de CIA #2.
El registro de temporizador de 16 bits tiene dos direcciones de memoria: una para el byte inferior y otra para el byte superior. Cada CIA tiene dos circuitos temporizadores. Las dos CIA son idénticas. Para CIA #1, las direcciones de los dos temporizadores son: DC04 y DC05 para TA y DC06 y DC07 para TB. Para CIA #2, las direcciones de los dos temporizadores son: DD04 y DD05 para TA y DD06 y DD07 para TB.
Supongamos que el número 25510 se enviará al temporizador TA de la CIA #2 para realizar la cuenta regresiva. 25510 = 00000000111111112 está en dieciséis bits. 00000000111111112 = $000FFF está en hexadecimal. En este caso, $FF se envía a la caja registradora en la dirección $DD04 y $00 se envía a la caja registradora en la dirección $DD05 (little endianness). El siguiente segmento de código envía el número a la caja registradora:
#$FF
ESTADO $DD04
LDA#$00
ESTADO $DD05
Aunque los registros en una CIA tienen direcciones RAM, están físicamente en la CIA y la CIA es un IC separado de la RAM o la ROM.
¡Eso no es todo! Cuando al temporizador se le ha asignado un número para la cuenta regresiva, como en el código anterior, la cuenta regresiva no comienza. La cuenta regresiva comienza cuando se envía un byte de ocho bits al registro de control correspondiente del temporizador. El primer bit de este byte para el registro de control indica si debe comenzar o no la cuenta atrás. Un valor de 0 para este primer bit significa detener la cuenta regresiva, mientras que un valor de 1 significa comenzar la cuenta regresiva. Además, el byte debe indicar si la cuenta regresiva está en modo de un solo disparo (una sola vez) o en modo de ejecución libre (modo continuo). El modo de un disparo cuenta atrás y se detiene cuando el valor del registro del temporizador llega a cero. Con el modo de ejecución libre, la cuenta regresiva se repite después de llegar a 0. El cuarto bit (índice 3) del byte que se envía al registro de control indica el modo: 0 significa modo de ejecución libre y 1 significa modo de un solo disparo.
Un número adecuado para empezar a contar en modo de una sola vez es 000010012 = $09 en hexadecimal. Un número adecuado para empezar a contar en modo de ejecución libre es 000000012 = $01 en hexadecimal. Cada registro de temporizador tiene su propio registro de control. En CIA #1, el registro de control para el temporizador A tiene la dirección RAM de DC0E16 y el registro de control para el temporizador B tiene la dirección RAM de DC0F16. En CIA #2, el registro de control para el temporizador A tiene la dirección RAM de DD0E16 y el registro de control para el temporizador B tiene la dirección RAM de DD0F16. Para comenzar la cuenta regresiva del número de dieciséis bits en TA de CIA #2, en modo one-shot, use el siguiente código:
LDA#$09
ESTA $DD0E
Para comenzar la cuenta regresiva del número de dieciséis bits en TA de CIA #2, en modo de ejecución libre, use el siguiente código:
LDA#$01
ESTA $DD0E
5.12 El IRQ y NMI Peticiones
El microprocesador 6502 tiene la IRQ y NMI líneas (alfileres). Tanto la CIA #1 como la CIA #2 tienen cada una la IRQ pin para el microprocesador. El IRQ El pin de la CIA #2 está conectado al NMI pin del µP. El IRQ El pin de la CIA #1 está conectado al IRQ pin del µP. Esas son las dos únicas líneas de interrupción que conectan el microprocesador. Entonces el IRQ pin de la CIA #2 es el NMI fuente y también puede verse como la línea ¯NMI.
La CIA #1 tiene cinco posibles fuentes inmediatas para generar el IRQ señal para µP. La CIA #2 tiene la misma estructura que la CIA #1. Entonces, la CIA #2 tiene las mismas cinco posibles fuentes inmediatas para generar la señal de interrupción esta vez, que es la NMI señal. Recuerde que cuando el µP recibe la NMI señal, si está manejando el IRQ solicitud, la suspende y se ocupa de la NMI pedido. Cuando termine de manipular el NMI solicitud, luego reanuda el manejo de la IRQ pedido.
El CIA #1 normalmente se conecta externamente al teclado y a un dispositivo de juego, como un joystick. El teclado usa más puerto A de CIA #1 que el puerto B. El dispositivo de juego usa más puerto B de CIA #1 que su puerto A. CIA #2 normalmente está conectado externamente a la unidad de disco (conectado en cadena a la impresora) y el módem. La unidad de disco usa más puerto A de CIA #2 (aunque a través del puerto serie externo) que su puerto B. El módem (RS-232) usa más puerto B de CIA #2 que su puerto A.
Con todo eso, ¿cómo sabe la unidad del sistema qué causa el IRQ o NMI ¿interrumpir? La CIA #1 y la CIA #2 tienen cinco fuentes inmediatas de interrupción. Si la señal de interrupción al µP es NMI , la fuente es una de las cinco fuentes inmediatas de la CIA #2. Si la señal de interrupción al µP es IRQ , la fuente es una de las cinco fuentes inmediatas de la CIA #1.
La siguiente pregunta es: '¿Cómo diferencia la unidad del sistema entre las cinco fuentes inmediatas de cada CIA?' Cada CIA tiene un registro de ocho bits que se denomina Registro de Control de Interrupciones (ICR). El ICR sirve a ambos puertos de la CIA. La siguiente tabla muestra el significado de los ocho bits del registro de control de interrupciones, comenzando desde el bit 0:
| Tabla 5.13 Registro de control de interrupciones |
|
|---|---|
| Índice de bits | Significado |
| 0 | Conjunto (hecho 1) por subdesbordamiento del temporizador A |
| 1 | Configurado por el desbordamiento del temporizador B |
| 2 | Establecer cuándo el reloj de hora del día equivale a la alarma |
| 3 | Establecer cuando el puerto serie está lleno |
| 4 | Configurado por dispositivo externo |
| 5 | No usado (hecho 0) |
| 6 | No usado (hecho 0) |
| 7 | Se establece cuando se establece cualquiera de los primeros cinco bits |
Como puede verse en la tabla, cada una de las fuentes inmediatas está representada por uno de los primeros cinco bits. Entonces, cuando la señal de interrupción se recibe en µP, se debe ejecutar el código para leer el contenido del registro de control de interrupciones para conocer la fuente exacta de la interrupción. La dirección RAM para el ICR de CIA #1 es DC0D16. La dirección RAM para el ICR de CIA #2 es DD0D16. Para leer (devolver) el contenido del ICR del CIA #1 al acumulador µP, escriba la siguiente instrucción:
LDA$DC0D
Para leer (devolver) el contenido del ICR del CIA #2 al acumulador µP, escriba la siguiente instrucción:
LDA$DD0D
5.13 Programa en segundo plano impulsado por interrupciones
El teclado normalmente interrumpe el microprocesador cada 1/60 de segundo. Imagine que un programa se está ejecutando y llega a una posición en la que espera una tecla del teclado antes de poder continuar con los segmentos de código siguientes. Supongamos que si no se presiona ninguna tecla del teclado, el programa solo realiza un pequeño bucle, esperando una tecla. Imagine que el programa se está ejecutando y solo esperaba una tecla del teclado justo después de que se emitiera la interrupción del teclado. En ese punto, toda la computadora se detiene indirectamente y no hace nada más que el ciclo de espera. Imagine que se presiona una tecla del teclado justo antes de la siguiente interrupción del teclado. ¡Esto significa que la computadora no ha hecho nada durante aproximadamente una sexagésima de segundo! Es mucho tiempo para que una computadora no haga nada, incluso en los días del Commodore-64. La computadora podría haber estado haciendo otra cosa en ese tiempo (duración). Hay muchas duraciones de este tipo en un programa.
Se puede escribir un segundo programa para que funcione en esos períodos de 'inactividad'. Se dice que un programa de este tipo funciona en segundo plano del programa principal (o primero). Una manera fácil de hacer esto es simplemente forzar un manejo de interrupciones BRK modificado cuando se espera una tecla del teclado.
Puntero para la instrucción BRK
En las ubicaciones consecutivas de la RAM de las direcciones $0316 y $0317 se encuentra el puntero (vector) para la rutina de instrucción BRK real. El puntero predeterminado se coloca allí cuando el sistema operativo enciende la computadora en la ROM. Este puntero predeterminado es una dirección que todavía apunta al controlador de instrucciones BRK predeterminado en la ROM del sistema operativo. El puntero es una dirección de 16 bits. El byte inferior del puntero se coloca en la ubicación del byte de la dirección $0306 y el byte superior del puntero se coloca en la ubicación del byte $0317.
Se puede escribir un segundo programa de modo que cuando el sistema esté 'inactivo', el sistema ejecute algunos códigos del segundo programa. Esto significa que el segundo programa debe estar compuesto de subrutinas. Cuando el sistema está 'inactivo' y espera una tecla del teclado, se ejecuta la siguiente subrutina para el segundo programa. La interacción humana con la computadora es lenta en comparación con el funcionamiento de la unidad del sistema.
Este problema se soluciona fácilmente: cada vez que la computadora tenga que esperar una tecla del teclado, inserte una instrucción BRK en el código y reemplace el puntero en $0316 (y $0317) con el puntero de la siguiente subrutina del segundo ( personalizado) programa. De esa manera, ambos programas se ejecutarían en una duración no mucho mayor que la del programa principal que se ejecuta solo.
5.14 Montaje y Compilación
El ensamblador reemplaza todas las etiquetas con direcciones. Un programa en lenguaje ensamblador normalmente se escribe para comenzar en una dirección particular. El resultado del ensamblador (después del ensamblaje) se llama 'código objeto' y todo está en binario. Ese resultado es el archivo ejecutable si el archivo es un programa y no un documento. Un documento no es ejecutable.
Una aplicación consta de más de un programa (lenguaje ensamblador). Suele haber un programa principal. La situación aquí no debe confundirse con la situación de los programas en segundo plano controlados por interrupciones. Todos los programas aquí son programas de primer plano, pero hay un programa primero o principal.
Se necesita un compilador en lugar del ensamblador cuando hay más de un programa en primer plano. El compilador ensambla cada uno de los programas en un código objeto. Sin embargo, habría un problema: algunos de los segmentos de código se superpondrían porque los programas probablemente hayan sido escritos por diferentes personas. La solución del compilador es desplazar todos los programas superpuestos excepto el primero en el espacio de memoria, para que los programas no se superpongan. Ahora bien, cuando se trata de almacenar variables, algunas direcciones de variables aún se superpondrían. La solución aquí es reemplazar las direcciones superpuestas con las nuevas direcciones (excepto el primer programa) para que ya no se superpongan. De esta forma, los diferentes programas encajarán en las diferentes porciones (áreas) de la memoria.
Con todo eso, es posible que una rutina en un programa llame a una rutina en otro programa. Entonces, el compilador realiza el enlace. Vincular se refiere a tener la dirección inicial de una subrutina en un programa y luego llamarla en otro programa; ambos son parte de la aplicación. Ambos programas necesitan utilizar la misma dirección para esto. El resultado final es un gran código objeto con todo en binario (bits).
5.15 Guardar, cargar y ejecutar un programa
Un lenguaje ensamblador normalmente se escribe en algún programa editor (que puede proporcionarse con el programa ensamblador). El programa editor indica dónde comienza y termina el programa en la memoria (RAM). La rutina Kernal SAVE de la ROM del sistema operativo del Commodore-64 puede guardar un programa en la memoria en el disco. Simplemente vuelca en el disco la sección (bloque) de la memoria que puede contener su llamada de instrucción. Es recomendable tener la instrucción de llamada a SAVE, separada del programa que se está guardando, de modo que cuando el programa se cargue en la memoria desde el disco, no se vuelva a guardar cuando se ejecute. Cargar un programa en lenguaje ensamblador desde el disco es un tipo diferente de desafío porque un programa no puede cargarse solo.
Un programa no puede cargarse desde el disco hasta donde comienza y termina en la RAM. El Commodore-64 en aquellos días normalmente contaba con un intérprete BASIC para ejecutar los programas en lenguaje BASIC. Cuando la máquina (computadora) está encendida, se instala con el símbolo del sistema: LISTO. Desde allí, los comandos o instrucciones BÁSICOS se pueden escribir presionando la tecla 'Entrar' después de escribir. El comando (instrucción) BÁSICO para cargar un archivo es:
CARGAR “nombre de archivo”,8,1
El comando comienza con la palabra reservada BÁSICA que es CARGAR. A esto le sigue un espacio y luego el nombre del archivo entre comillas dobles. Va seguido del número de dispositivo 8, precedido por una coma. La dirección secundaria del disco, que es 1, va seguida de una coma. Con un archivo de este tipo, la dirección inicial del programa en lenguaje ensamblador está en el encabezado del archivo en el disco. Cuando el BASIC termina de cargar el programa, se devuelve la última dirección RAM más 1 del programa. La palabra 'devuelto' aquí significa que el byte inferior de la última dirección más 1 se coloca en el registro µP X, y el byte superior de la última dirección más 1 se coloca en el registro µP Y.
Después de cargar el programa, debe ejecutarse (ejecutarse). El usuario del programa debe conocer la dirección de inicio de ejecución en la memoria. Nuevamente aquí es necesario otro programa BÁSICO. Es el comando SYS. Después de ejecutar el comando SYS, el programa en lenguaje ensamblador se ejecutará (y se detendrá). Mientras se ejecuta, si se necesita alguna entrada desde el teclado, el programa en lenguaje ensamblador debe indicárselo al usuario. Después de que el usuario ingresa los datos en el teclado y presiona la tecla 'Enter', el programa en lenguaje ensamblador continuará ejecutándose usando la entrada del teclado sin interferencia del intérprete BASIC.
Suponiendo que el inicio de la dirección RAM de ejecución (en ejecución) para el programa en lenguaje ensamblador es C12316, C123 se convierte a base diez antes de usarlo con el comando SYS. La conversión de C12316 a base diez es la siguiente:
Entonces, el comando BASIC SYS es:
SISTEMA 49443
5.16 Arranque para Commodore-64
El arranque del Commodore-64 consta de dos fases: la fase de reinicio del hardware y la fase de inicialización del sistema operativo. El sistema operativo es el Kernal en ROM (y no en disco). Hay una línea de reinicio (en realidad RES ) que se conecta a un pin en el 6502 µP, y al mismo nombre de pin en todos los barcos especiales como el CIA 1, CIA 2 y VIC II. En la fase de reinicio, debido a esta línea, todos los registros en el µP y en los chips especiales se restablecen a 0 (se ponen a cero para cada bit). A continuación, mediante el hardware del microprocesador, el puntero de la pila y el registro de estado del procesador reciben sus valores iniciales en el microprocesador. Luego, el contador del programa recibe el valor (dirección) en las ubicaciones $FFFC y $FFFD. Recuerde que el contador del programa contiene la dirección de la siguiente instrucción. El contenido (dirección) que se guarda aquí es para la subrutina que comienza la inicialización del software. Hasta ahora todo lo hace el hardware del microprocesador. En esta fase no se toca toda la memoria. Entonces comienza la siguiente fase de inicialización.
La inicialización se realiza mediante algunas rutinas en el sistema operativo ROM. La inicialización significa dar los valores iniciales o predeterminados a algunos registros en los chips especiales. La inicialización comienza dando los valores iniciales o predeterminados a algunos registros en los chips especiales. IRQ , por ejemplo, tiene que empezar a emitirse cada 1/60 de segundo. Por lo tanto, su temporizador correspondiente en CIA #1 debe configurarse en su valor predeterminado.
A continuación, el Kernal realiza una prueba de RAM. Prueba cada ubicación enviando un byte a la ubicación y leyéndolo nuevamente. Si hay alguna diferencia, al menos esa ubicación es mala. Kernal también identifica la parte superior y la parte inferior de la memoria y establece los punteros correspondientes en la página 2. Si la parte superior de la memoria es $DFFF, $FF se coloca en la ubicación $0283 y $DF se coloca en la ubicación del byte $0284. Tanto $0283 como $0284 tienen la etiqueta HIRAM. Si la parte inferior de la memoria es $0800, $00 se coloca en la ubicación $0281 y $08 se coloca en la ubicación $0282. Tanto $0281 como $0282 tienen la etiqueta LORAM. La prueba de RAM en realidad comienza desde $0300 hasta la parte superior de la memoria (RAM).
Finalmente, los vectores de entrada/salida (punteros) se establecen en sus valores predeterminados. La prueba de RAM en realidad comienza desde $0300 hasta la parte superior de la memoria (RAM). Esto significa que las páginas 0, 1 y 2 están inicializadas. La página 0, en particular, tiene muchos punteros de ROM del sistema operativo y la página 2 tiene muchos punteros BÁSICOS. Estos indicadores se denominan variables. Recuerde que la página 1 es la pila. Los punteros se denominan variables porque tienen nombres (etiquetas). En esta etapa, se borra la memoria de la pantalla (monitor). Esto significa enviar el código de $20 por espacio (que resulta ser el mismo que ASCII $20) a las ubicaciones de la pantalla de 1000 RAM. Por último, Kernal inicia el intérprete BÁSICO para mostrar el símbolo del sistema BÁSICO que está LISTO en la parte superior del monitor (pantalla).
5.17 Problemas
Se recomienda al lector que resuelva todos los problemas de un capítulo antes de pasar al siguiente.
- Escriba un código en lenguaje ensamblador que convierta todos los bits del puerto A de la CIA #2 como salida y del puerto B de la CIA #2 como entrada.
- Escriba un código de lenguaje ensamblador 6502 que espere una tecla del teclado hasta que se presione.
- Escriba un programa en lenguaje ensamblador 6502 que envíe el carácter 'E' a la pantalla del Commodore-64.
- Escriba un programa en lenguaje ensamblador 6502 que tome un carácter del teclado y lo envíe a la pantalla del Commodore-64, ignorando el código de tecla y el tiempo.
- Escriba un programa en lenguaje ensamblador 6502 que reciba un byte del disquete Commodore-64.
- Escriba un programa en lenguaje ensamblador 6502 que guarde un archivo en el disquete Commodore-64.
- Escriba un programa en lenguaje ensamblador 6502 que cargue un archivo de programa desde el disquete Commodore-64 y lo inicie.
- Escriba un programa en lenguaje ensamblador 6502 que envíe el byte “E” (ASCII) al módem que está conectado al puerto compatible RS-232 del usuario del Commodore-64.
- Explique cómo se realizan el conteo y el cronometraje en la computadora Commodore-64.
- Explique cómo la unidad del sistema Commodore-64 puede identificar 10 fuentes diferentes de solicitudes de interrupción inmediata, incluidas las solicitudes de interrupción no enmascarables.
- Explique cómo se puede ejecutar un programa en segundo plano con un programa en primer plano en la computadora Commodore-64.
- Explique brevemente cómo se pueden compilar los programas en lenguaje ensamblador en una aplicación para la computadora Commodore-64.
- Explique brevemente el proceso de arranque de la computadora Commodore-64.