Elasticsearch es una solución robusta y popular para almacenar datos voluminosos, no estructurados y semiestructurales. Es puramente una base de datos NoSQL y utiliza un enfoque totalmente diferente para almacenar, administrar y recuperar datos. Almacena datos en un documento en formato JSON y utiliza API de descanso para realizar diferentes operaciones en los datos almacenados.
En este blog, demostraremos:
- ¿Cómo funciona Elasticsearch para almacenar y buscar datos?
- ¿Qué son los documentos de Elasticsearch?
- ¿Cómo almacenar datos en un documento de Elasticsearch?
¿Cómo funciona Elasticsearch para almacenar y buscar datos?
Los componentes principales o la jerarquía de Elasticsearch que se utilizan para almacenar datos se enumeran a continuación:
- Documento: El documento es la parte principal de Elasticsearch que almacena datos en formato JSON. Como
- Índices: Los índices se denominan índices. Es una colección de documentos. Al igual que en SQL, se denomina Base de datos.
- Índices invertidos: Admite búsquedas de texto completo muy rápidas. Almacena la palabra como índice y el nombre del documento como referencia.
¿Qué son los documentos de Elasticsearch?
El documento de Elasticsearch es una unidad de almacenamiento de datos en formato JSON. Al igual que en las bases de datos relacionales, se puede hacer referencia al documento como una tabla o una fila de una base de datos que se almacena en algún índice. El índice puede tener varios documentos y se denomina base de datos que tiene varias tablas. Por lo general, almacena una estructura de datos compleja y esteriliza los datos en formato JSON.
Además, cada documento puede contener varios campos que son ' valor clave ” pares para almacenar los datos al igual que una tabla tiene varias columnas o campos en una base de datos relacional. Luego, se supone que estos pares clave-valor se indexan de manera que determinen el mapeo del documento. Luego, el mapeo define el tipo de datos del documento de acuerdo con los datos de campo, como texto, flotante, punto geográfico, tiempo y muchos más.
Elasticsearch nunca nos obligó a predefinir la estructura de campo del índice y los documentos pueden tener una estructura de campo diferente en un índice. Sin embargo, si la asignación del campo se define para un tipo de datos específico, todos los documentos de Elasticsearch en un índice deben seguir el mismo tipo de asignación. Para verificar el funcionamiento del documento para almacenar datos en Elasticsearch, vaya a la siguiente sección.
¿Cómo almacenar datos en un documento de Elasticsearch?
Para almacenar datos en Elasticsearch, el usuario primero debe crear un índice. Luego, especifique los campos para almacenar los datos en el documento de Elasticsearch. Para la demostración, siga los pasos enumerados.
Paso 1: Inicie Elasticsearch
Para ejecutar la base de datos o el motor de Elasticsearch en el sistema, inicie el terminal del sistema, como el símbolo del sistema. Después de eso, visite el “ papelera ” carpeta de Elasticsearch a través de la “ cd ' dominio:
cd C:\Usuarios\Dell\Documentos\Elk stack\elasticsearch-8.7.0\bin
Después de eso, ejecute el archivo por lotes de Elasticsearch para ejecutar la base de datos en el sistema:
elasticsearch.bat
Paso 2: Inicie Kibana
A continuación, ejecute Kibana en el sistema. Para ello, visita su “ papelera ” carpeta desde el símbolo del sistema:
cd C:\Usuarios\Dell\Documentos\Elk stack\kibana-8.7.0\bin
Luego, ejecute el siguiente comando para comenzar a ejecutar Kibana:
kibana.bat
Nota: Si no ha instalado y configurado Elasticsearch y Kibana en el sistema, navegue a nuestras publicaciones y consulte el procedimiento paso a paso para instalarlos en el sistema.
Para Elasticsearch, visite nuestro “ Instalar y configurar Elasticsearch con .zip en Windows ' artículo. Para configurar Kibana en Windows, siga el “ Configurar Kibana para Elasticsearch ' artículo.
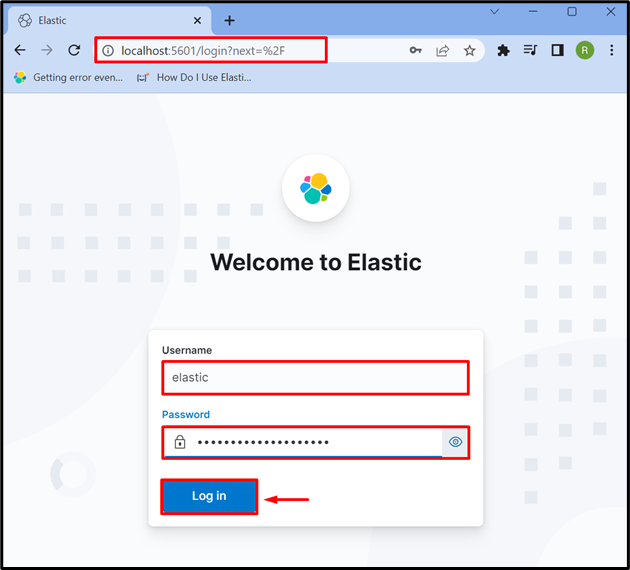
Paso 3: Iniciar sesión en Kibana
Después de iniciar Kibana en el sistema, navegue a la dirección predeterminada de Kibana “ anfitrión local: 5601 ” en el navegador y proporcione las credenciales de inicio de sesión de Elasticsearch como “ elástico ” usuario y contraseña. Después de eso, presione el botón ' Acceso ' botón:
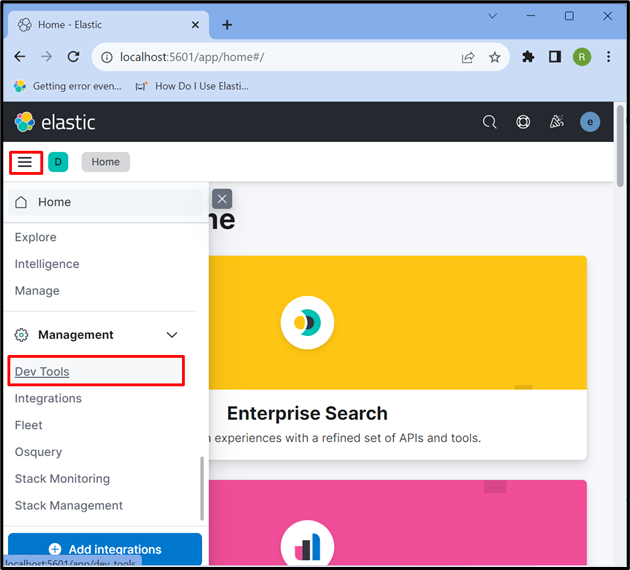
Paso 4: Abra la 'Herramienta de desarrollo' de Kibana
Después de eso, haga clic en el ' Tres barras horizontales Ícono ' y abre el Kibana ' Herramienta de desarrollo ” para usar las API para almacenar, recuperar y actualizar los datos:
Paso 5: Crear Índice
Ahora, crea un nuevo índice usando “ PUT /
La salida muestra que el “ datos de empleados El índice se ha creado correctamente:
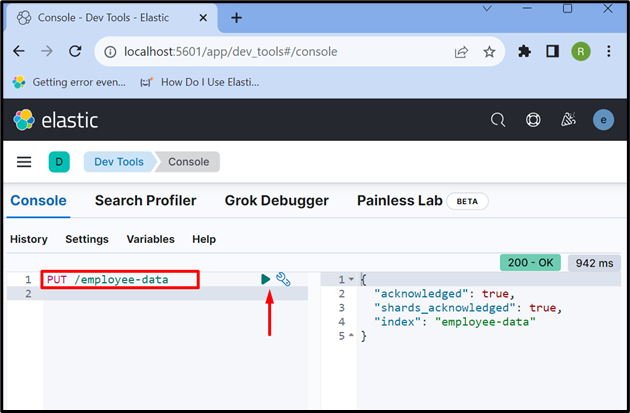
Paso 6: Insertar datos en el documento
Ahora, usa el ' CORREO ” API para almacenar los datos en el índice. En la siguiente solicitud, “ datos de empleados ” es un índice de Elasticsearch, “ _doc ” se usa para almacenar datos en el documento de Elasticsearch, y “ 1 ” es la identificación:
CORREO / datos de empleados / _doc / 1 ?bonito{
'Nombre' : 'Rafia' ,
'fecha de nacimiento' : '19-NOV-1997' ,
'almacenado' :verdadero
}
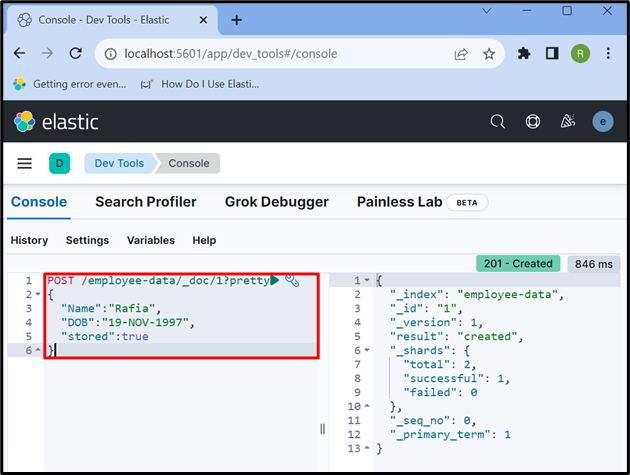
Paso 7: recuperar datos del documento de Elasticsearch
Para acceder a los datos del índice o del documento de Elasticsearch, utilice el ' CONSEGUIR ” API como se usa a continuación:
CONSEGUIR / datos de empleados / _doc / 1 ?bonito
El resultado muestra que hemos extraído con éxito los datos del documento de Elasticsearch que tiene una identificación ' 1 ”:
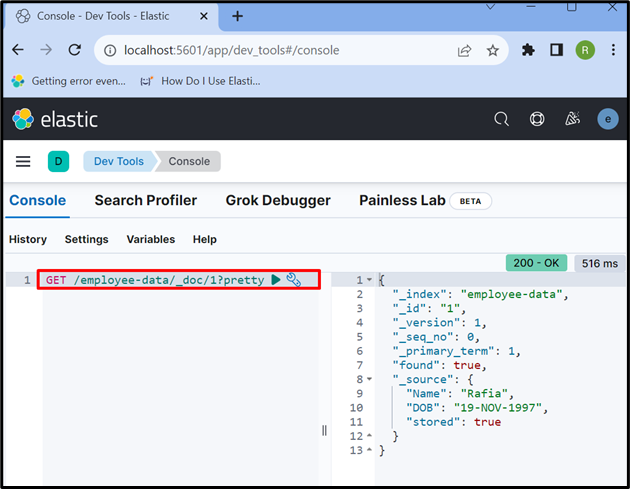
Eso es todo sobre el documento de Elasticsearch.
Conclusión
El documento de Elasticsearch generalmente se usa para almacenar datos en formato JSON. Al igual que en las bases de datos relacionales, se puede hacer referencia al documento como una fila que se almacena en algún índice. Estos índices pueden tener múltiples documentos al igual que las bases de datos tienen diferentes tablas. Estos documentos contienen múltiples campos que son “ valor clave ” pares para almacenar los datos. Este artículo ha demostrado qué son los documentos de Elasticsearch y cómo funcionan en Elasticsearch.