Como administradores de bases de datos, debemos obsesionarnos con las herramientas y los métodos para mejorar el rendimiento de la base de datos.
En PostgreSQL, tenemos acceso al comando EXPLAIN ANALYZE que nos permite analizar el plan de ejecución y el rendimiento de una consulta de base de datos determinada. El comando devuelve información detallada sobre cómo el motor de la base de datos procesa la consulta. Esto incluye la secuencia de operaciones realizadas, los costos de consulta estimados, el tiempo de ejecución y más.
Luego, podemos usar esta información para identificar las consultas de la base de datos, así como para identificar y solucionar los posibles cuellos de botella en el rendimiento.
Este tutorial explica cómo usar el comando EXPLAIN ANALYZE en PostgreSQL para ver y optimizar el rendimiento de la consulta.
PostgreSQL EXPLICAR ANALIZAR
El comando es bastante sencillo. Primero, debemos anteponer el comando EXPLAIN ANALYZE al comienzo de la consulta que deseamos analizar.
La sintaxis del comando es la siguiente:
EXPLICAR ANALIZARUna vez que ejecuta el comando, PostgreSQL devuelve un resultado detallado sobre la consulta proporcionada.
Comprender el resultado de la consulta EXPLAIN ANALYZE
Como se mencionó, una vez que ejecutamos el comando EXPLAIN ANALYZE, PostgreSQL genera un informe detallado del plan de consulta y las estadísticas de ejecución.
La salida se compone de un conjunto de columnas que contienen información útil. Las columnas resultantes son las que se muestran con su respectivo significado:
PLAN DE CONSULTA – Esta columna muestra el plan de ejecución de la consulta especificada. El plan de ejecución se refiere a una secuencia de operaciones que realiza el motor de la base de datos para completar la consulta con éxito.
PLAN – La segunda columna es la columna PLAN. Este contiene una representación textual de cada operación o paso en el plan de ejecución. Nuevamente, cada operación está sangrada para indicar la jerarquía de operaciones.
COSTE TOTAL – La columna de costo total representa el costo total estimado de la consulta. El costo se refiere a una medida relativa que utiliza el planificador de consultas de la base de datos para determinar el plan de ejecución óptimo.
FILAS REALES – Esta columna muestra el número exacto de filas que se procesan en cada paso de la ejecución de la consulta.
TIEMPO ACTUAL – Esta columna muestra el tiempo real que tarda cada operación, que incluye tanto el tiempo de ejecución de la operación como el tiempo dedicado a los recursos.
TIEMPO DE PLANIFICACIÓN – Esta columna muestra el tiempo que tarda el planificador de consultas en generar un plan de ejecución. Esto incluye el tiempo total de la optimización de consultas y la generación del plan.
TIEMPO DE EJECUCIÓN – Esta columna muestra el tiempo total para ejecutar la consulta. Esto también incluye el tiempo dedicado a la planificación y el tiempo de ejecución de consultas.
PostgreSQL EXPLICAR ANALIZAR Ejemplo
Veamos algunos ejemplos básicos del uso de la instrucción EXPLAIN ANALYZE.
Ejemplo 1: declaración de selección
Usemos la declaración EXPLAIN ANALYZE para mostrar la ejecución de una declaración de selección simple en PostgreSQL.
Una vez que ejecutamos la declaración anterior, deberíamos obtener una salida de la siguiente manera:
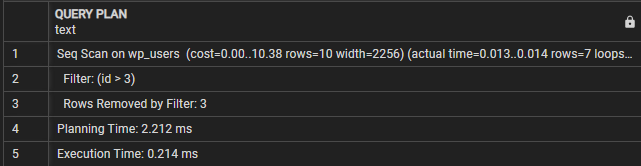
PLAN DE CONSULTA-------------------------------------------------------------------
Seq Scan en wp_users (costo=0,00...10,38 filas=10 ancho=2256) (tiempo real=0,009...0,010 filas=7 bucles=1)
Filtro: (id > 3)
Filas eliminadas por filtro: 3
Tiempo de planificación: 0,995 ms
Tiempo de ejecución: 0,021 ms
(5 filas)
En este caso, podemos ver que la sección Query plan indica que la consulta realiza un escaneo secuencial en la tabla wp_users. La línea de filtro indica la condición que se utiliza para filtrar las filas resultantes.
Luego vemos las 'Filas eliminadas por el filtro', que muestra la cantidad de filas que se eliminan por la condición del filtro.
Finalmente, el tiempo de ejecución muestra el tiempo total de ejecución de la consulta. En este caso, la consulta tarda 0,021 ms.
Ejemplo 2: Análisis de una combinación
Tomemos una consulta más compleja que involucra una unión SQL. Para ello, utilizamos la base de datos de ejemplo de Pagila. Puede descargar e instalar la base de datos de muestra en su máquina con fines de demostración.
Podemos ejecutar una combinación simple como se muestra a continuación:
explicar analizar SELECCIONAR f.título, c.nombreDE la película f
ÚNETE film_category fc ON f.film_id = fc.film_id
ÚNASE a la categoría c EN fc.category_id = c.category_id;
Una vez que ejecutamos la consulta dada, deberíamos ver el resultado de la siguiente manera:
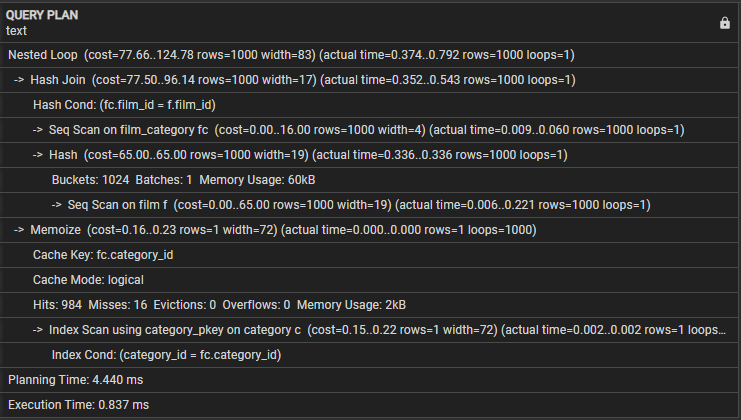
Exploremos el siguiente plan de consulta:
- Bucle anidado: esto indica que la unión utiliza una estrategia de unión de bucle anidado.
- Hash Join: esta operación une film_category y las tablas de películas mediante un algoritmo Hash join. Esta operación tiene un costo de 77.50 y se estiman 1000 filas. Sin embargo, el tiempo real que tarda esta operación es de 0,254 a 0,439 milisegundos y recupera 1000 filas.
- Hash Cond: esto indica que la condición de combinación utiliza una combinación Hash para hacer coincidir las columnas film_id y film_category en las tablas de películas.
- Escaneo secuencial en categoría_película: esta operación realiza un escaneo secuencial en la tabla categoría_película con un costo de 16,00 y 1000 filas estimadas. El tiempo real que toma esta operación es de 0,008 a 0,056 milisegundos y recupera 1000 filas.
- Escaneo secuencial en película: la consulta realiza un escaneo secuencial en la mesa de película con los costos y filas estimados y reales resultantes en esta operación.
- Memoize: esta operación almacena en caché los resultados de la unión entre film_category y tablas de películas para su uso posterior.
- Clave de caché: esto indica que la clave de caché que se utiliza para la memorización se basa en la columna category_id de film_category.
- Modo de caché: esto indica que la consulta utiliza el modo de caché lógico.
- Aciertos, errores, desalojos, desbordamientos: las tres líneas proporcionan estadísticas sobre la memoria caché, la cantidad de aciertos, errores, desalojos y desbordamientos durante la ejecución. Este bloque también incluye el uso de la memoria durante la ejecución de la consulta.
- Escaneo de índice usando category_pkey: muestra la operación que realiza un escaneo de índice en la tabla de categorías usando el índice de clave principal.
- Index Cond: esto muestra que la exploración del índice se basa en la condición que coincide con la columna category_id en la tabla de categorías.
- Tiempo de planificación: esta línea muestra el tiempo necesario para la planificación de consultas, que es de 3,005 milisegundos.
- Tiempo de ejecución: finalmente, esta línea muestra el tiempo total de ejecución de la consulta, que es de 0,745 milisegundos.
¡Ahí tienes! Una información detallada sobre la ejecución de una unión simple en PostgreSQL.
Conclusión
Descubrió el poder y el uso de la instrucción EXPLAIN ANALYZE en PostgreSQL. La instrucción EXPLAIN ANALYZE es una poderosa herramienta para el análisis y la optimización de consultas. Utilice esta herramienta para crear consultas eficientes y que consuman menos recursos.