Método Set_Option de pandas
Hoy, veremos cómo usar la función 'pd.set_option()' para mostrar todas las columnas en Pandas Dataframe cuando lo presente en su herramienta Spyder. Para usar “pd.set_option()”, seguimos la sintaxis dada:

Comencemos a aprender el concepto con la ayuda de la implementación práctica del programa Python.
Ejemplo: utilizar el método Set_Option de Pandas para mostrar todas las columnas
Esta demostración es una guía para mostrar todas las columnas en un DataFrame utilizando Pandas 'set_option()'. Aclararemos los detalles de cada paso para la implementación de este método de Python.
El primer requisito para la implementación práctica del script de Python es encontrar la mejor herramienta donde ejecutar su programa. La herramienta que usamos para nuestra ilustración es la herramienta 'Spyder'. Lanzamos la herramienta y comenzamos a trabajar en el script de Python.
Comenzando con el código, inicialmente necesitamos importar las bibliotecas de requisitos previos que necesitamos en este programa. La primera biblioteca que cargamos en nuestro archivo de Python es la biblioteca de Pandas, ya que Pandas proporciona las funciones que usamos aquí. Hemos creado un alias para esta biblioteca como 'pd'. La segunda biblioteca que cargamos es la biblioteca NumPy. NumPy (Numerical Python) es un paquete de computación numérica desarrollado sobre programación Python. La sección Importar NumPy del código indica a Python que integre el módulo NumPy en su archivo de Python actual. La parte 'as np' del script le indica a Python que asigne a NumPy la abreviatura 'np'. Le permite utilizar los métodos NumPy ingresando 'np.function_name' en lugar de NumPy.
Ahora, comenzamos con el código principal. La necesidad principal y fundamental de nuestro programa es Pandas DataFrame. Entonces, mostramos todas las columnas que contiene. Ahora, depende completamente de usted si desea crear un DataFrame con valores específicos o si necesita importar un archivo CSV. Lo que elegimos para esta instancia es crear un DataFrame con valores NaN. Invocamos el método “pd.DataFrame()” para construir un DataFrame. Aquí, proporcionamos dos parámetros: 'índice' y 'columnas'. El argumento 'índice' se refiere a las filas, lo que significa que configuramos las filas para el DataFrame.
Asignamos el parámetro 'índice' y la función NumPy 'np.arange() con un recuento de valores de '6'. Genera seis filas para el DataFrame. Rellena todas las entradas con valores NaN ya que no le hemos proporcionado ningún valor. El argumento 'columnas', como lo especifica el nombre, se usa para establecer las columnas para el DataFrame. También se le asigna la función “np.arange()” con un recuento de valores “25” para las columnas. Por lo tanto, construye 25 columnas para el DataFrame.
En consecuencia, cuando llamamos a la función 'pd.DataFrame()', tenemos un DataFrame con 25 columnas y 6 filas llenas de valores nulos. Por la necesidad de preservar este DataFrame, estamos obligados a construir un objeto DataFrame que almacene su contenido. Por lo tanto, creamos un objeto DataFrame 'aleatorio' y le asignamos el resultado que obtenemos del método 'pd.DataFrame()'. Ahora, seguramente querrá ver cómo se genera el DataFrame. Python nos proporciona un método para ver la salida en la pantalla que es la función 'imprimir ()'. Invocamos este método pasando el objeto DataFrame 'aleatorio' como su parámetro.
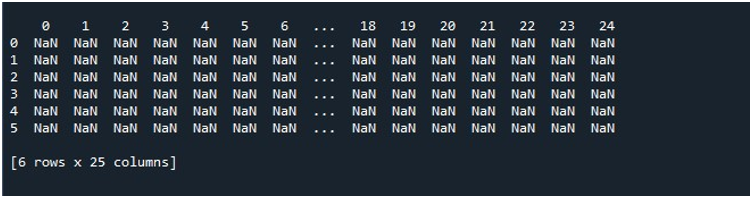
Cuando ejecutamos este fragmento de código, obtenemos nuestro DataFrame con los valores de NaN que se muestran en la terminal. Aquí, podemos observar que algunas de las primeras columnas y solo algunas del final son visibles. Todas las columnas intermedias se truncan. De forma predeterminada, oculta algunas de las filas y columnas para evitar crear una frustración para el usuario al mostrar grandes conjuntos de datos.
Incluso puede verificar la cantidad de columnas totales en un DataFrame usando la función 'len ()' de Pandas. Escriba la función 'len()' en la consola de su herramienta 'Spyder'. Escribe el nombre del DataFrame entre paréntesis con la propiedad “.columns”. Nos devuelve la longitud total de las columnas en su DataFrame.

Devuelve la longitud de nuestro DataFrame que es 25.
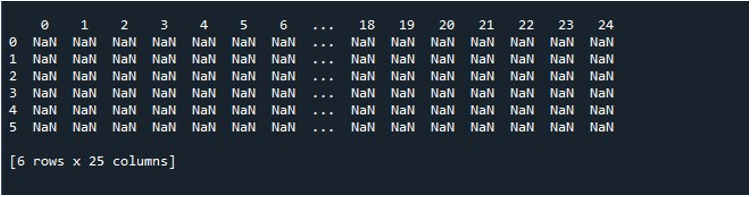
Ahora, la siguiente y principal tarea es cambiar la opción predeterminada para mostrar la salida. Puede haber circunstancias en las que desee ver todo el DataFrame en el terminal. Debido a los valores predeterminados, muchas entradas se truncan, lo que provoca la decepción del usuario. Aquí aprenderá cómo superar este problema. Pandas nos proporciona una función 'pd.set_option ()' para cambiar la configuración de visualización predeterminada. Inmediatamente después de mostrar el DataFrame en la consola, invocamos el método 'pd.set_option()'. Especificamos el parámetro entre paréntesis de esta función que necesitamos utilizar para mostrar todas las columnas del DataFrame.
Aquí, usamos 'display.max_columns' para mostrar las columnas máximas en nuestro DataFrame. También podemos definir el valor de este parámetro, es decir, las columnas máximas que desea mostrar. Nosotros, por otro lado, configuramos 'display.max_columns' en 'Ninguno', lo que muestra todas las columnas del DataFrame con la longitud máxima. Finalmente, empleamos la función 'imprimir ()' para mostrar el DataFrame resultante con todas las columnas visibles en la terminal.
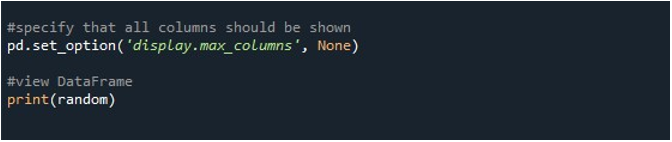
Cuando presionamos la opción 'Ejecutar archivo' en la herramienta 'Spyder', podemos ver un DataFrame que se exhibe. Este DataFrame tiene seis filas y la cantidad de columnas que contiene es 25. No hay columnas que estén truncadas ya que la función 'pd.set_option()' con la longitud máxima de columna está habilitada ahora.
Incluso podemos restablecer la opción de visualización porque una vez que configuramos la longitud de visualización al máximo, continúa mostrando los marcos de datos con todas las columnas dentro de ese archivo de Python en particular. Para esto, utilizamos Pandas “pd.reset_option()”. Invocamos esta función y proporcionamos 'display.max_columns' como parámetro de esta función.

Esto nos da la configuración de visualización inicial para el marco de datos proporcionado.
Conclusión
Ver la salida completa en el terminal con un gran conjunto de datos a veces nos mete en problemas cuando la configuración predeterminada de la herramienta contrasta con las necesidades del usuario. Para solucionar este contratiempo, Pandas nos brinda el método “pd.set_option()”. En esta guía de aprendizaje, le presentamos este método y la necesidad de emplearlo. Demostramos el tema con los códigos de muestra de Python prácticamente compilados y ejecutados. Renderizamos los resultados de la ilustración realizada sobre “Spyder”. Explicamos cómo mostrar todas las columnas del DataFrame en la consola cambiando la configuración predeterminada y restableciendo todas las configuraciones a la inicial. Prestar una atención totalmente enfocada a la implementación práctica del módulo le permite utilizarlo siempre que encuentre tales problemas.