El multiprocesamiento es comparable al multiproceso. Sin embargo, se diferencia en que solo podemos ejecutar un hilo a la vez debido al GIL que se emplea para enhebrar. El multiprocesamiento es el proceso de realizar operaciones secuencialmente en varios núcleos de CPU. Los subprocesos no se pueden operar en paralelo. Sin embargo, el multiprocesamiento nos permite establecer los procesos y ejecutarlos simultáneamente en varios núcleos de CPU. El bucle, como el bucle for, es uno de los lenguajes de secuencias de comandos más utilizados. Repita el mismo trabajo utilizando varios datos hasta que se alcance un criterio, como un número predeterminado de iteraciones. El ciclo realiza cada iteración una por una.
Ejemplo 1: uso de For-Loop en el módulo de multiprocesamiento de Python
En este ejemplo, usamos el bucle for y el proceso de clase del módulo de multiprocesamiento de Python. Comenzamos con un ejemplo muy sencillo para que pueda comprender rápidamente cómo funciona el ciclo for de multiprocesamiento de Python. Utilizando una interfaz comparable al módulo de subprocesos, el multiprocesamiento empaqueta la creación de procesos.
Al emplear los subprocesos en lugar de los subprocesos, el paquete de multiprocesamiento proporciona simultaneidad tanto local como distante, evitando así el bloqueo global del intérprete. Use un bucle for, que puede ser un objeto de cadena o una tupla, para iterar continuamente a través de una secuencia. Esto funciona menos como la palabra clave que se ve en otros lenguajes de programación y más como un método iterador que se encuentra en otros lenguajes de programación. Al iniciar un nuevo multiprocesamiento, puede ejecutar un ciclo for que ejecuta un procedimiento simultáneamente.
Comencemos implementando el código para la ejecución del código utilizando la herramienta 'spyder'. Creemos que 'spyder' también es lo mejor para ejecutar Python. Importamos un proceso de módulo de multiprocesamiento que el código está ejecutando. El concepto de multiprocesamiento en Python denominado 'clase de proceso' crea un nuevo proceso de Python, le brinda un método para ejecutar código y le brinda a la aplicación principal una forma de administrar la ejecución. La clase Process contiene los procedimientos start() y join(), ambos cruciales.
A continuación, definimos una función definida por el usuario llamada 'func'. Dado que es una función definida por el usuario, le damos un nombre de nuestra elección. Dentro del cuerpo de esta función, pasamos la variable 'sujeto' como argumento y el valor 'matemático'. A continuación, llamamos a la función 'imprimir()', pasando la declaración 'El nombre del sujeto común es' así como su argumento 'sujeto' que contiene el valor. Luego, en el siguiente paso, utilizamos 'if name== _main_', que le impide ejecutar el código cuando el archivo se importa como un módulo y solo le permite hacerlo cuando el contenido se ejecuta como un script.
La sección de condiciones con la que comienza puede considerarse en la mayoría de las circunstancias como una ubicación para proporcionar el contenido que solo debe ejecutarse cuando su archivo se ejecuta como un script. Luego, usamos el argumento sujeto y almacenamos algunos valores en él que son 'ciencia', 'inglés' y 'computadora'. El proceso recibe entonces el nombre “proceso1[]” en el siguiente paso. Luego, usamos el 'proceso (objetivo = función)' para llamar a la función en el proceso. Target se usa para llamar a la función, y guardamos este proceso en la variable 'P'.
A continuación, usamos el 'proceso1' para llamar a la función 'agregar ()' que agrega un elemento al final de la lista que tenemos en la función 'función'. Debido a que el proceso se almacena en la variable 'P', pasamos 'P' a esta función como su argumento. Finalmente, usamos la función “start()” con “P” para iniciar el proceso. Después de eso, ejecutamos el método nuevamente mientras proporcionamos el argumento 'asunto' y usamos 'para' en el asunto. Luego, usando “process1” y el método “add()” una vez más, comenzamos el proceso. A continuación, se ejecuta el proceso y se devuelve la salida. Luego se le dice al procedimiento que finalice usando la técnica 'join()'. Los procesos que no llamen al procedimiento “join()” no saldrán. Un punto crucial es que se debe usar el parámetro de palabra clave 'args' si desea proporcionar argumentos durante el proceso.
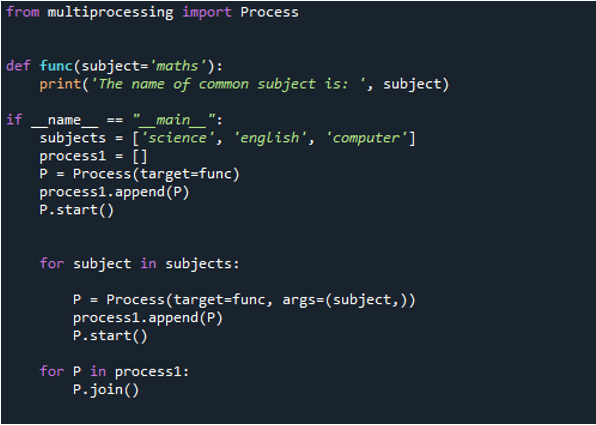
Ahora, puede ver en el resultado que la declaración se muestra primero al pasar el valor del tema 'matemáticas' que pasamos a la función 'func' porque primero lo llamamos usando la función 'proceso'. Luego, usamos el comando 'agregar ()' para tener valores que ya estaban en la lista que se agrega al final. Luego se presentaron “ciencias”, “computación” e “inglés”. Pero, como puede ver, los valores no están en la secuencia correcta. Esto se debe a que lo hacen tan pronto como finaliza el procedimiento y reportan su mensaje.
Ejemplo 2: Conversión de For-Loop secuencial en For-Loop paralelo de multiprocesamiento
En este ejemplo, la tarea de bucle de multiprocesamiento se ejecuta secuencialmente antes de convertirse en una tarea de bucle for paralelo. Puede recorrer secuencias como una colección o una cadena en el orden en que ocurren usando los bucles for.
Ahora, comencemos a implementar el código. Primero, importamos 'dormir' desde el módulo de tiempo. Usando el procedimiento 'dormir ()' en el módulo de tiempo, puede suspender la ejecución del hilo de llamada durante el tiempo que desee. Luego, usamos 'random' del módulo aleatorio, definimos una función con el nombre 'func' y pasamos la palabra clave 'argu'. Luego, creamos un valor aleatorio usando 'val' y lo configuramos como 'aleatorio'. Luego, bloqueamos por un pequeño período usando el método “sleep()” y pasamos “val” como parámetro. Luego, para transmitir un mensaje, ejecutamos el método “print()”, pasando las palabras “ready” y la palabra clave “arg” como su parámetro, así como “created” y pasando el valor usando “val”.
Finalmente, utilizamos 'flush' y lo configuramos en 'True'. El usuario puede decidir si almacenar o no en el búfer la salida utilizando la opción de vaciado en la función de impresión de Python. El valor predeterminado de este parámetro de Falso indica que la salida no se almacenará en el búfer. La salida se muestra como una serie de líneas que se suceden si se establece en verdadero. Luego, usamos 'if name== main' para asegurar los puntos de entrada. A continuación, ejecutamos el trabajo secuencialmente. Aquí, establecemos el rango en '10', lo que significa que el ciclo termina después de 10 iteraciones. A continuación, llamamos a la función 'imprimir ()', le pasamos la declaración de entrada 'listo' y usamos la opción 'flush = True'.
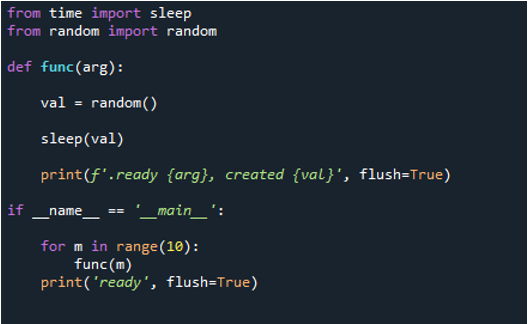
Ahora puede ver que cuando ejecutamos el código, el ciclo hace que la función se ejecute '10' veces. Itera 10 veces, comenzando en el índice cero y terminando en el índice nueve. Cada mensaje contiene un número de tarea que es un número de función que pasamos como un 'argumento' y un número de creación.
Este bucle secuencial ahora se está transformando en un bucle for paralelo de multiprocesamiento. Usamos el mismo código, pero vamos a algunas bibliotecas y funciones adicionales para el multiprocesamiento. Por lo tanto, debemos importar el proceso desde multiprocesamiento, tal como explicamos anteriormente. A continuación, creamos una función llamada 'func' y pasamos la palabra clave 'arg' antes de usar 'val=random' para obtener un número aleatorio.
Luego, después de invocar el método 'print()' para mostrar un mensaje y dar el parámetro 'val' para retrasar un pequeño período, utilizamos la función 'if name= main' para asegurar los puntos de entrada. Después de lo cual, creamos un proceso y llamamos a la función en el proceso usando 'proceso' y pasamos el 'objetivo = función'. Luego, pasamos 'func', 'arg', pasamos el valor 'm' y pasamos el rango '10', lo que significa que el ciclo termina la función después de '10' iteraciones. Luego, comenzamos el proceso usando el método “start()” con “process”. Luego, llamamos al método “join()” para esperar la ejecución del proceso y completar todo el proceso después.
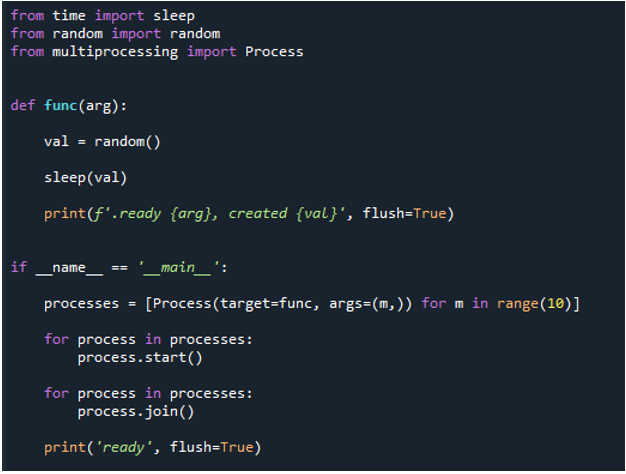
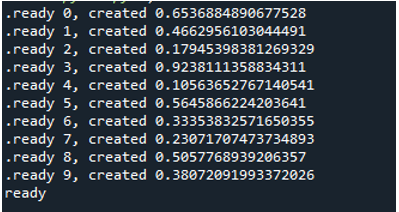
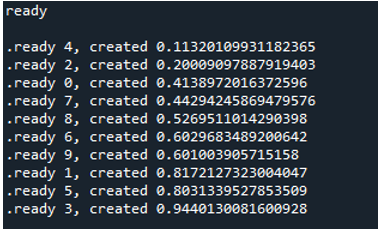
Por tanto, cuando ejecutamos el código, las funciones llaman al proceso principal y comienzan su ejecución. Sin embargo, se realizan hasta que se completan todas las tareas. Podemos ver eso porque cada tarea se lleva a cabo simultáneamente. Informa de su mensaje tan pronto como finaliza. Esto significa que aunque los mensajes están desordenados, el ciclo finaliza después de que se completan las '10' iteraciones.
Conclusión
Cubrimos el ciclo for de multiprocesamiento de Python en este artículo. También presentamos dos ilustraciones. La primera ilustración muestra cómo utilizar un bucle for en la biblioteca de multiprocesamiento de bucles de Python. Y la segunda ilustración muestra cómo cambiar un bucle for secuencial en un bucle for de multiprocesamiento paralelo. Antes de construir el script para el multiprocesamiento de Python, debemos importar el módulo de multiprocesamiento.