Este artículo discutirá cómo usar la API de obtención múltiple de Elasticsearch para obtener múltiples documentos JSON en función de sus ID. Además, Elasticsearch le permite usar una sola consulta de obtención para recuperar los documentos de los índices usando solo las ID de los documentos.
Vamos a explorar.
Solicitud de sintaxis
La siguiente es la sintaxis para la API multi-get de Elasticsearch:
OBTENER /_mget
OBTENER /<índice>/_mget
La API de obtención múltiple admite múltiples índices, lo que le permite obtener los documentos incluso si no están en el mismo índice.
La solicitud admite los siguientes parámetros de ruta:
- <índice> – El nombre del índice desde el que recuperar los documentos según lo especificado por sus ID.
También puede especificar los otros parámetros de consulta como se muestra:
- Preferencia – Define el nodo o fragmento preferido.
- Tiempo real – Si se establece en verdadero, la operación se realiza en tiempo real.
- Actualizar – Obliga a la operación a actualizar los fragmentos de destino antes de recuperar los documentos especificados.
- Enrutamiento – Un valor que se utiliza para enrutar las operaciones a un fragmento específico.
- Store_fields – Recupera los campos del documento almacenados en un índice en lugar del documento.
- _fuente – Un valor booleano que define si la solicitud debe devolver el campo _source o no.
La consulta requiere el cuerpo, que incluye los siguientes valores:
- Documentos – Especifica los documentos que desea recuperar. Además, esta sección admite los siguientes atributos:
- _identificación – ID único del documento de destino.
- _índice – El índice que contiene el documento de destino.
- Enrutamiento – La clave para el fragmento principal del documento.
- _fuente – Si es verdadero, incluye todos los campos de origen; de lo contrario, los excluye.
- _campos_almacenados – Los campos_almacenados que desea incluir.
- identificaciones – Los identificadores de los documentos que desea obtener.
Ejemplo 1: obtener varios documentos del mismo índice
El siguiente ejemplo muestra cómo usar la API multi-get de Elasticsearch para recuperar los documentos con ID específicos del índice de Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: informes' -H 'Tipo de contenido: aplicación/json' -d'{
'docs': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
La solicitud dada debe obtener los documentos con las ID especificadas del índice de Netflix. La salida resultante es como se muestra:
{'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_versión 1,
'_seq_no': 0,
'_término_primario': 1,
'encontrado': cierto,
'_fuente': {
'duración': '90 minutos',
'listed_in': 'Documentales',
'País: Estados Unidos',
'date_added': '25 de septiembre de 2021',
'show_id': 's1',
'directora': 'Kirsten Johnson',
'año_de_lanzamiento': 2020,
'clasificación': 'PG-13',
'description': 'A medida que su padre se acerca al final de su vida, la cineasta Kirsten Johnson escenifica su muerte de manera inventiva y cómica para ayudarlos a ambos a enfrentar lo inevitable'.,
'tipo': 'Película',
'título': 'Dick Johnson ha muerto'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_versión 1,
'_seq_no': 12,
'_término_primario': 1,
'encontrado': cierto,
'_fuente': {
'país': 'Alemania, República Checa',
'show_id': 's13',
'director': 'Christian Schwochow',
'año_de_lanzamiento': 2021,
'clasificación': 'TV-MA',
'description': 'Después de que la mayor parte de su familia es asesinada en un atentado terrorista, una mujer joven es atraída sin saberlo a unirse al mismo grupo que los mató'.,
'tipo': 'Película',
'título': 'Soy Carlos',
'duración': '127 minutos',
'listed_in': 'Dramas, Películas internacionales',
'elenco': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23 de septiembre de 2021'
}
}
]
}
También podemos simplificar la solicitud colocando los ID de los documentos en una matriz simple, como se muestra a continuación:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: informes' -H 'Tipo de contenido: aplicación/json' -d'{
'identificadores': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
La solicitud anterior debe realizar una acción similar.
Ejemplo 2: Obtener los documentos de varios índices
En el siguiente ejemplo, la solicitud obtiene varios documentos de diferentes índices, como se muestra:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: informes' -H 'Tipo de contenido: aplicación/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
La salida resultante es como se muestra:

Ejemplo 3: Excluir campos específicos
Podemos excluir campos específicos de una solicitud dada usando los parámetros source_include y source_exclude.
Un ejemplo es como se muestra:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: informes' -H 'Tipo de contenido: aplicación/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_fuente': falso
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_fuente': {
'incluir': [ 'listed_in', 'release_year', 'title' ],
'excluir': [ 'descripción', 'tipo', 'fecha_añadida' ]
}
}
]
}'
La solicitud dada utiliza la fuente de inclusión y exclusión para especificar qué campos desea recuperar en un documento determinado.
La salida resultante es como se muestra:
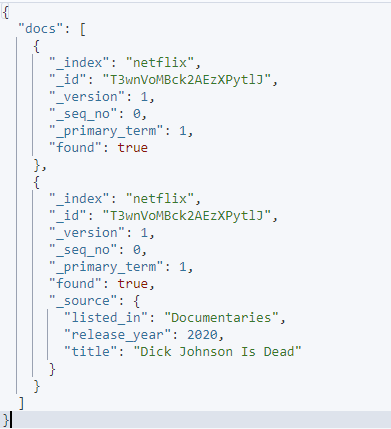
Conclusión
En esta publicación, discutimos los fundamentos de trabajar con la API de obtención múltiple de Elasticsearch, que le permite obtener múltiples documentos de varias fuentes en función de sus ID. Siéntase libre de explorar los otros documentos para obtener más información.
¡Feliz codificación!