Los pandas llenan los valores de NaN
Si una columna en su marco de datos tiene valores NaN o Ninguno, puede usar las funciones 'fillna()' o 'replace()' para llenarlos con cero (0).
llenar()
Los valores NA/NaN se rellenan con el enfoque proporcionado utilizando la función 'fillna()'. Se puede utilizar considerando la siguiente sintaxis:
Si desea completar los valores de NaN para una sola columna, la sintaxis es la siguiente:

Cuando se le solicita que complete los valores de NaN para el DataFrame completo, la sintaxis es la proporcionada:

Reemplazar()
Para reemplazar una sola columna de valores NaN, la sintaxis proporcionada es la siguiente:

Mientras que, para reemplazar los valores NaN de todo el DataFrame, tenemos que usar la siguiente sintaxis mencionada:

En este escrito, ahora exploraremos y aprenderemos la implementación práctica de ambos métodos para completar los valores de NaN en nuestro Pandas DataFrame.
Ejemplo 1: Rellenar valores de NaN usando el método Pandas “Fillna()”
Esta ilustración demuestra la aplicación de la función 'DataFrame.fillna()' de Pandas para completar los valores de NaN en el DataFrame dado con 0. Puede completar los valores que faltan en una sola columna o puede completarlos para todo el DataFrame. Aquí, veremos ambas técnicas.
Para poner en práctica estas estrategias, necesitamos contar con una plataforma adecuada para la ejecución del programa. Entonces, decidimos usar la herramienta 'Spyder'. Comenzamos nuestro código de Python importando el kit de herramientas 'pandas' en el programa porque necesitamos usar la función Pandas para construir el DataFrame, así como para completar los valores faltantes en ese DataFrame. El 'pd' se usa como el alias de 'pandas' en todo el programa.
Ahora, tenemos acceso a las funciones de Pandas. Primero usamos su función 'pd.DataFrame()' para generar nuestro DataFrame. Invocamos este método y lo inicializamos con tres columnas. Los títulos de estas columnas son 'M1', 'M2' y 'M3'. Los valores en la columna 'M1' son '1', 'Ninguno', '5', '9' y '3'. Las entradas en 'M2' son 'Ninguno', '3', '8', '4' y '6'. Mientras que el 'M3' almacena los datos como '1', '2', '3', '5' y 'Ninguno'. Necesitamos un objeto DataFrame en el que podamos almacenar este DataFrame cuando se llama al método 'pd.DataFrame()'. Creamos un objeto DataFrame 'perdido' y lo asignamos por el resultado que obtuvimos de la función 'pd.DataFrame()'. Luego, empleamos el método 'print()' de Python para mostrar el DataFrame en la consola de Python.
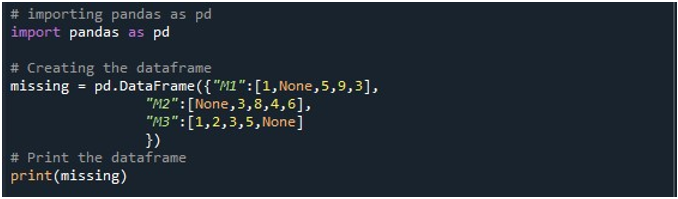
Cuando ejecutamos este fragmento de código, se puede ver un DataFrame con tres columnas en la terminal. Aquí, podemos observar que las tres columnas contienen los valores nulos en ellas.
Creamos un DataFrame con algunos valores nulos para aplicar la función 'fillna()' de Pandas para completar los valores faltantes con 0. Aprendamos cómo podemos hacer eso.
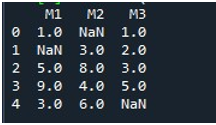
Después de mostrar el DataFrame, invocamos la función 'fillna()' de Pandas. Aquí, aprenderemos a completar los valores que faltan en una sola columna. La sintaxis para esto ya se menciona al comienzo del tutorial. Proporcionamos el nombre del DataFrame y especificamos el título de la columna en particular con la función '.fillna ()'. Entre los paréntesis de este método, proporcionamos el valor que se pondrá en los lugares nulos. El nombre de DataFrame 'falta' y la columna que elegimos aquí es 'M2'. El valor proporcionado entre las llaves de “fillna()” es “0”. Por último, llamamos a la función 'imprimir ()' para ver el DataFrame actualizado.

Aquí, puede ver que la columna 'M2' del DataFrame no contiene ningún valor faltante ahora porque el valor de NaN se completa con 0.
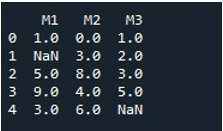
Para llenar los valores de NaN para un DataFrame completo con el mismo método, llamamos 'fillna()'. Esto es bastante simple. Proporcionamos el nombre de DataFrame con la función 'fillna()' y asignamos el valor de función '0' entre paréntesis. Finalmente, la función 'imprimir ()' nos mostró el DataFrame lleno.

Esto nos da un DataFrame sin valores NaN ya que todos los valores se rellenan con 0 ahora.
Ejemplo 2: Llene los valores de NaN usando el método Pandas 'Reemplazar ()'
Esta parte del artículo demuestra otro método para llenar los valores de NaN en un DataFrame. Usaremos la función “reemplazar()” de Pandas para llenar los valores en una sola columna y en un DataFrame completo.
Empezamos a escribir el código en la herramienta “Spyder”. Primero, importamos las bibliotecas requeridas. Aquí, cargamos la biblioteca de Pandas para permitir que el programa Python use los métodos de Pandas. La segunda biblioteca que cargamos es NumPy y le asignamos un alias 'np'. NumPy maneja los datos que faltan con el método 'reemplazar ()'.
Luego, generamos un DataFrame con tres columnas: 'tornillo', 'clavo' y 'taladro'. Los valores en cada columna se dan respectivamente. La columna 'tornillo' tiene valores '112', '234', 'Ninguno' y '650'. La columna 'clavo' tiene '123', '145', 'Ninguno' y '711'. Por último, la columna 'explorar' tiene valores '312', 'Ninguno', '500' y 'Ninguno'. El DataFrame se almacena en el objeto DataFrame 'herramienta' y se muestra mediante el método 'print()'.
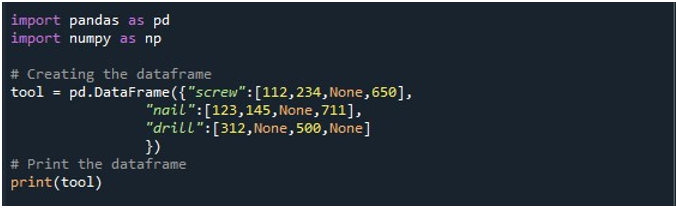
Un DataFrame con cuatro valores NaN en el registro se puede ver en la siguiente imagen de salida:
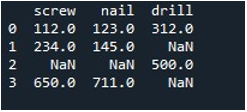
Ahora, usamos el método 'reemplazar ()' de Pandas para completar los valores nulos en una sola columna del DataFrame. Para la tarea, invocamos la función 'reemplazar ()'. Suministramos el nombre de DataFrame 'herramienta' y la columna 'tornillo' con el método '.replace()'. Entre sus llaves, establecemos el valor '0' para las entradas 'np.nan' en el DataFrame. El método 'imprimir ()' se emplea para mostrar la salida.

El DataFrame resultante nos muestra la primera columna con las entradas NaN reemplazadas por 0 en la columna 'tornillo'.
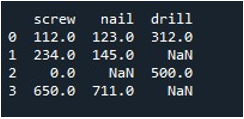
Ahora, aprenderemos a llenar los valores en todo el DataFrame. Llamamos al método 'reemplazar ()' con el nombre del DataFrame y proporcionamos el valor que queremos reemplazar con entradas np.nan. Finalmente, imprimimos el DataFrame actualizado con la función “print()”.

Esto nos da el DataFrame resultante sin registros faltantes.
Conclusión
Tratar con las entradas que faltan en un DataFrame es fundamental y es un requisito necesario para reducir la complejidad y manejar los datos de manera desafiante en el proceso de análisis de datos. Pandas nos ofrece algunas opciones para hacer frente a este problema. Trajimos dos estrategias útiles en esta guía. Ponemos en práctica ambas técnicas con la ayuda de la herramienta 'Spyder' para ejecutar los códigos de muestra para que las cosas sean un poco más comprensibles y fáciles para usted. Obtener un conocimiento de estas funciones agudizará sus habilidades de Pandas.