El nodo final de una lista vinculada que tiene un bucle se referirá a otro nodo en la misma lista en lugar de NULL. Si hay un nodo en una lista vinculada a la que se puede acceder repetidamente siguiendo el siguiente puntero, se dice que la lista tener un ciclo.
Por lo general, el último nodo de la lista enlazada se refiere a una referencia NULL para indicar la conclusión de la lista. Sin embargo, en una lista enlazada con un bucle, el nodo final de la lista se refiere a un nodo inicial, a un nodo interno oa sí mismo. Por lo tanto, en tales circunstancias, debemos identificar y terminar el bucle estableciendo la referencia del siguiente nodo en NULL. La parte de detección del bucle en una lista enlazada se explica en este artículo.
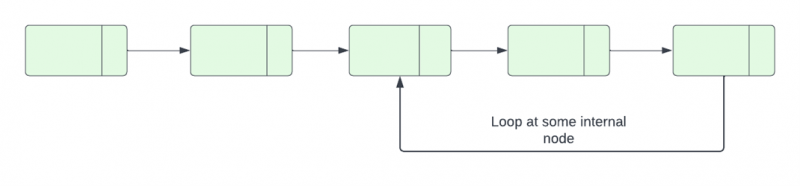
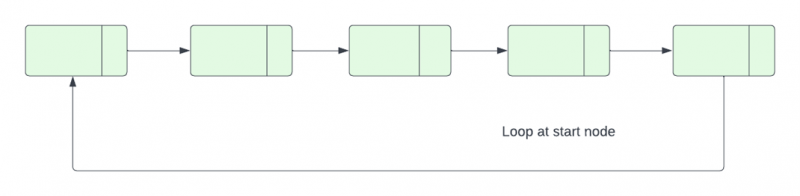
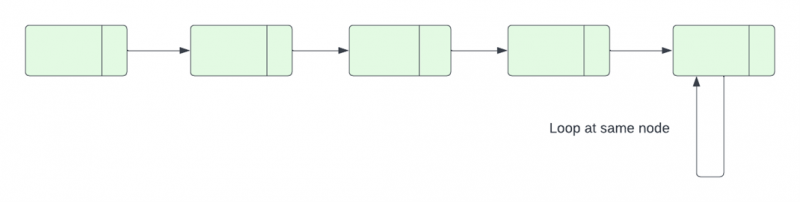
En C++, existen numerosas formas de encontrar bucles en una lista enlazada:
Enfoque basado en tablas hash : este enfoque almacena las direcciones de los nodos visitados en una tabla hash. Existe un bucle en la lista enlazada si un nodo ya está presente en la tabla hash cuando se vuelve a visitar.
El enfoque del ciclo de Floyd : El algoritmo de 'tortuga y liebre', comúnmente conocido como algoritmo de búsqueda de ciclos de Floyd: esta técnica utiliza dos punteros, uno que se mueve más lentamente que el otro y el otro se mueve más rápido. El puntero más rápido finalmente superará al puntero más lento si hay un bucle en la lista enlazada, revelando la existencia del bucle.
método recursivo : Este método recorre la lista enlazada llamándose a sí mismo una y otra vez. La lista enlazada contiene un bucle si el nodo actual ha sido visitado previamente.
Enfoque basado en pilas : este enfoque almacena las direcciones de los nodos visitados en una pila. Un bucle en la lista enlazada está presente si un nodo ya está allí en la pila cuando se vuelve a visitar.
Vamos a explicar cada enfoque en detalle para entender el concepto.
Enfoque 1: Enfoque HashSet
Utilizar hashing es el método más directo. Aquí, revisamos la lista una por una mientras mantenemos una tabla hash con las direcciones de los nodos. Por lo tanto, existe un bucle si alguna vez nos encontramos con la siguiente dirección del nodo actual que ya está contenido en la tabla hash. De lo contrario, no hay bucle en la Lista enlazada si nos encontramos con NULL (es decir, llegamos al final de la Lista enlazada).
Será bastante fácil implementar esta estrategia.
Mientras recorremos la lista enlazada, utilizaremos un mapa de hash unordered y seguiremos agregando nodos.
Ahora, una vez que nos encontremos con un nodo que ya se muestra en el mapa, sabremos que hemos llegado al comienzo del bucle.
-
- Además, mantuvimos dos punteros en cada paso, nodo principal apuntando al nodo actual y último nodo apuntando al nodo anterior del nodo actual, mientras se itera.
- Como el nuestro nodo principal ahora apunta al nodo de inicio del ciclo y como último nodo apuntaba al nodo al que apuntaba la cabeza (es decir, se refiere al último nodo del bucle), nuestro nodo principal está apuntando actualmente al nodo de inicio del bucle.
- El ciclo se romperá configurando l astNode->siguiente == NULL .
Al hacer esto, el nodo final del ciclo, en lugar de referirse al nodo inicial del ciclo, comienza a apuntar a NULL.
La complejidad promedio de tiempo y espacio del método hash es O(n). El lector siempre debe tener en cuenta que la implementación de la Hashing DataStructure incorporada en el lenguaje de programación determinará la complejidad del tiempo total en caso de una colisión en el hash.
Implementación del programa C++ para el método anterior (HashSet):
#incluye
utilizando el espacio de nombres estándar;
nodo de estructura {
valor int;
nodo de estructura * próximo;
} ;
Nodo * nuevoNodo ( valor entero )
{
Nodo * nodotemp = nuevo nodo;
tempNode- > valor = valor;
tempNode- > siguiente = NULO;
devolver nodotemp;
}
// Identifique y elimine cualquier bucle potencial
// en una lista enlazada con esta función.
función vacíaHashMap ( Nodo * nodo principal )
{
// Creó un mapa unordered_map para implementar el mapa Hash
mapa_desordenado < Nodo * , En t > hash_mapa;
// puntero a último nodo
Nodo * últimoNodo = NULL;
mientras ( nodo principal ! = NULO ) {
// Si falta un nodo en el mapa, agréguelo.
si ( hash_map.encontrar ( nodo principal ) == mapa_hash.end ( ) ) {
hash_map [ nodo principal ] ++;
últimoNodo = HeadNode;
headNode = headNode- > próximo;
}
// Si hay un ciclo presente, colocar el nodo final El siguiente puntero de NULL.
demás {
últimoNodo->siguiente = NULL;
romper;
}
}
}
// Mostrar lista enlazada
visualización vacía (nodo * headNode)
{
while (headNode != NULL) {
cout << headNode->valor << ' ';
headNode = headNode->siguiente;
}
cout << endl;
}
/* Función principal*/
int principal()
{
Nodo* headNode = newNode(48);
headNode->siguiente = headNode;
headNode->siguiente = newNode(18);
headNode->siguiente->siguiente = newNode(13);
headNode->siguiente->siguiente->siguiente = newNode(2);
headNode->siguiente->siguiente->siguiente->siguiente = nuevoNodo(8);
/* Crear un bucle en la lista enlazada */
headNode->siguiente->siguiente->siguiente->siguiente->siguiente = headNode->siguiente->siguiente;
functionHashMap(headNode);
printf('Lista enlazada sin bucle \n');
mostrar (nodo principal);
devolver 0;
}
Producción:
Lista enlazada sin bucle
48 18 13 2 8
La explicación paso a paso del código se proporciona a continuación:
-
- El archivo de encabezado bits/stdc++.h>, que contiene todas las bibliotecas comunes de C++, se incluye en el código.
- Se construye una estructura llamada 'Nodo' y tiene dos miembros: una referencia al siguiente nodo en la lista y un número entero llamado 'valor'.
- Con un valor entero como entrada y el puntero 'siguiente' establecido en NULL, la función 'nuevoNodo' crea un nuevo nodo con ese valor.
- La función ' functionHashMap' se define, que toma un puntero al nodo principal de la lista vinculada como entrada.
- Dentro de ' functionHashMap ‘, se crea un mapa desordenado llamado ‘hash_map’, que se utiliza para implementar una estructura de datos de mapa hash.
- Un puntero al último nodo de la lista se inicializa en NULL.
- Se utiliza un ciclo while para atravesar la lista enlazada, que comienza desde el nodo principal y continúa hasta que el nodo principal es NULL.
- El puntero lastNode se actualiza al nodo actual dentro del ciclo while si el nodo actual (headNode) no está ya presente en el mapa hash.
- Si el nodo actual se encuentra en el mapa, significa que hay un bucle presente en la lista vinculada. Para eliminar el bucle, el siguiente puntero del último nodo se establece en NULO y el bucle while está roto.
- El nodo principal de la lista vinculada se usa como entrada para una función llamada 'mostrar', que genera el valor de cada nodo en la lista de principio a fin.
- En el principal función, creando un bucle.
- La función ‘functionHashMap’ se llama con el puntero headNode como entrada, lo que elimina el bucle de la lista.
- La lista modificada se muestra mediante la función de visualización.
Enfoque 2: Ciclo de Floyd
El algoritmo de detección de ciclos de Floyd, a menudo conocido como el algoritmo de la liebre y la tortuga, proporciona la base para este método de localización de ciclos en una lista enlazada. El puntero 'lento' y el puntero 'rápido', que recorren la lista a varias velocidades, son los dos punteros que se utilizan en esta técnica. El puntero rápido avanza dos pasos mientras que el puntero lento avanza un paso en cada iteración. Existe un ciclo en la lista enlazada si los dos puntos alguna vez se encuentran cara a cara.
1. Con el nodo principal de la lista enlazada, inicializamos dos punteros llamados rápido y lento.
2. Ahora ejecutamos un bucle para movernos por la lista enlazada. El puntero rápido debe moverse dos ubicaciones delante del puntero lento en cada paso de iteración.
3. No habrá un bucle en la lista enlazada si el puntero rápido llega al final de la lista (fastPointer == NULL o fastPointer->next == NULL). De lo contrario, los punteros rápido y lento eventualmente se encontrarán, lo que significa que la lista enlazada tiene un bucle.
Implementación del programa C++ para el método anterior (Ciclo de Floyd):
#incluye
utilizando el espacio de nombres estándar;
/* Nodo de lista de enlaces */
nodo de estructura {
datos int;
nodo de estructura * próximo;
} ;
/* Función para eliminar bucle. */
anular eliminar bucle ( nodo de estructura * , estructura Nodo * ) ;
/* Este función localiza y elimina bucles de lista. Cede 1
si había un bucle en la lista; demás , vuelve 0 . */
int detectAndDeleteLoop ( nodo de estructura * lista )
{
nodo de estructura * lentoPTR = lista, * fastPTR = lista;
// Iterar para verificar si el bucle está ahí.
mientras ( lentoPTR && rápidoPTR && rápidoPTR- > próximo ) {
lentoPTR = lentoPTR- > próximo;
fastPTR = fastPTR- > próximo- > próximo;
/* Si slowPTR y fastPTR se encuentran en algún momento entonces allá
es un bucle */
si ( PTR lento == PTR rápido ) {
eliminarbucle ( lentoPTR, lista ) ;
/* Devolver 1 para indicar que se ha descubierto un bucle. */
devolver 1 ;
}
}
/* Devolver 0 para indicar que no se ha descubierto ningún bucle. */
devolver 0 ;
}
/* Función para eliminar el bucle de la lista enlazada.
loopNode apunta a uno de los nodos de bucle y headNode apunta
al nodo de inicio de la lista enlazada */
anular eliminar bucle ( nodo de estructura * nodobucle, nodo de estructura * nodo principal )
{
nodo de estructura * ptr1 = nodobucle;
nodo de estructura * ptr2 = nodobucle;
// Cuente cuántos nodos son en el lazo.
int sin signo k = 1 , i;
mientras ( ptr1- > próximo ! = ptr2 ) {
ptr1 = ptr1- > próximo;
k++;
}
// Fijar un puntero a headNode
ptr1 = headNode;
// Y el otro puntero a k nodos después de headNode
ptr2 = headNode;
para ( yo = 0 ; i < k; yo ++ )
ptr2 = ptr2- > próximo;
/* Cuando ambos puntos se mueven simultáneamente,
chocarán en el bucle nodo inicial de . */
mientras (ptr2 != ptr1) {
ptr1 = ptr1->siguiente;
ptr2 = ptr2->siguiente;
}
// Obtener el nodo' s último puntero.
mientras ( ptr2- > próximo ! = ptr1 )
ptr2 = ptr2- > próximo;
/* Para cerrar el ciclo, colocar el posterior
nodo al bucle nodo de terminación. */
ptr2->siguiente = NULL;
}
/* Función para mostrar la lista enlazada */
void mostrarListaEnlazada(estructura Nodo* nodo)
{
// mostrar la lista enlazada después de eliminar el ciclo
while (nodo != NULL) {
cout << nodo->datos << ' ';
nodo = nodo->siguiente;
}
}
struct Node* newNode(int clave)
{
struct Nodo* temp = nuevo Nodo();
temp->datos = clave;
temp->siguiente = NULL;
temperatura de retorno;
}
// Código principal
int principal()
{
struct Node* headNode = newNode(48);
headNode->siguiente = newNode(18);
headNode->siguiente->siguiente = newNode(13);
headNode->siguiente->siguiente->siguiente = newNode(2);
headNode->siguiente->siguiente->siguiente->siguiente = nuevoNodo(8);
/* Crea un bucle */
headNode->siguiente->siguiente->siguiente->siguiente->siguiente = headNode->siguiente->siguiente;
// mostrar el bucle en la lista enlazada
//mostrarListaEnlazada(headNode);
detectAndDeleteLoop(headNode);
cout << 'Lista enlazada sin bucle \n';
mostrarListaEnlazada(headNode);
devolver 0;
}
Producción:
Lista enlazada después de ningún bucle
48 18 13 2 8
Explicación:
-
- Primero se incluyen los encabezados relevantes, como 'bits/stdc++.h' y 'std::cout'.
- A continuación, se declara la estructura 'Nodo', que representa un nodo en la lista enlazada. Se incluye un puntero siguiente que lleva al siguiente nodo de la lista junto con un campo de datos enteros en cada nodo.
- Luego, define 'deleteLoop' y 'detectAndDeleteLoop', dos funciones. Se elimina un bucle de una lista vinculada con el primer método y se detecta un bucle en la lista con la segunda función, que luego llama al primer procedimiento para eliminar el bucle.
- Se crea una nueva lista enlazada con cinco nodos en la función principal y se establece un bucle al establecer el siguiente puntero del último nodo en el tercer nodo.
- Luego hace una llamada al método 'detectAndDeleteLoop' mientras pasa el nodo principal de la lista enlazada como argumento. Para identificar los bucles, esta función utiliza el enfoque de 'punteros lentos y rápidos'. Emplea dos punteros que comienzan en la parte superior de la lista, slowPTR y fastPTR. Mientras que el puntero rápido mueve dos nodos a la vez, el puntero lento solo mueve un nodo a la vez. El puntero rápido finalmente superará al puntero lento si la lista contiene un bucle, y los dos puntos colisionarán en el mismo nodo.
- La función invoca la función 'deleteLoop' si encuentra un bucle, proporcionando el nodo principal de la lista y la intersección de los punteros lento y rápido como entradas. Este procedimiento establece dos punteros, ptr1 y ptr2, al nodo principal de la lista y cuenta el número de nodos en el bucle. A continuación, avanza un puntero k nodos, donde k es el número total de nodos en el bucle. Luego, hasta que se encuentran al comienzo del ciclo, avanza ambos puntos un nodo a la vez. A continuación, el bucle se interrumpe estableciendo el siguiente puntero del nodo al final del bucle en NULL.
- Después de eliminar el bucle, muestra la lista vinculada como paso final.
Enfoque 3: recursividad
La recursividad es una técnica para resolver problemas dividiéndolos en subproblemas más pequeños y fáciles. La recursividad se puede utilizar para recorrer una lista enlazada individualmente en caso de que se encuentre un bucle ejecutando continuamente una función para el siguiente nodo de la lista hasta que se alcance el final de la lista.
En una lista enlazada individualmente, el principio básico detrás del uso de la recursividad para encontrar un ciclo es comenzar en la cabeza de la lista, marcar el nodo actual como visitado en cada paso y luego pasar al siguiente nodo invocando recursivamente la función para ese nodo. El método iterará sobre la lista enlazada completa porque se llama recursivamente.
La lista contiene un bucle si la función encuentra un nodo que se ha marcado previamente como visitado; en este caso, la función puede devolver verdadero. El método puede devolver falso si llega al final de la lista sin encontrarse con un nodo visitado, lo que indica que no hay bucle.
Aunque esta técnica para utilizar la recursividad para encontrar un bucle en una sola lista enlazada es fácil de usar y comprender, puede que no sea la más eficaz en términos de complejidad de tiempo y espacio.
Implementación del programa C++ para el método anterior (Recursión):
#incluir
utilizando el espacio de nombres estándar;
nodo de estructura {
datos int;
Nodo * próximo;
bool visitado;
} ;
// Detección de bucle de lista enlazada función
bool detectLoopLinkedList ( Nodo * nodo principal ) {
si ( headNode == NULL ) {
devolver FALSO ; // Si la lista enlazada está vacía, la base caso
}
// hay un bucle si el nodo actual tiene
// ya ha sido visitado.
si ( headNode- > visitado ) {
devolver verdadero ;
}
// Agregue una marca de visita al nodo actual.
headNode- > visitado = verdadero ;
// llamando al codigo para el nodo subsiguiente repetidamente
devolver detectLoopLinkedList ( headNode- > próximo ) ;
}
int principal ( ) {
Nodo * headNode = nuevo nodo ( ) ;
Nodo * segundoNodo = nuevo Nodo ( ) ;
Nodo * tercerNodo = nuevo Nodo ( ) ;
headNode- > datos = 1 ;
headNode- > siguiente = segundoNodo;
headNode- > visitado = FALSO ;
segundo nodo- > datos = 2 ;
segundo nodo- > siguiente = tercerNodo;
segundo nodo- > visitado = FALSO ;
tercer nodo- > datos = 3 ;
tercer nodo- > siguiente = NULO; // sin bucle
tercer nodo- > visitado = FALSO ;
si ( detectLoopLinkedList ( nodo principal ) ) {
cout << 'Bucle detectado en lista enlazada' << fin;
} demás {
cout << 'No se detectó bucle en la lista vinculada' << fin;
}
// Crear un bucle
tercer nodo- > siguiente = segundoNodo;
si ( detectLoopLinkedList ( nodo principal ) ) {
cout << 'Bucle detectado en lista enlazada' << fin;
} demás {
cout << 'No se detectó bucle en la lista vinculada' << fin;
}
devolver 0 ;
}
Producción:
No se detectó bucle en lista enlazada
Bucle detectado en lista enlazada
Explicación:
-
- La función detectLoopLinkedList() en este programa acepta el encabezado de la lista enlazada como entrada.
- La recursividad es utilizada por la función para iterar a través de la lista enlazada. Como caso básico para la recursividad, comienza determinando si el nodo actual es NULL. Si es así, el método devuelve falso, lo que indica que no existe ningún bucle.
- A continuación, se comprueba el valor de la propiedad 'visitada' del nodo actual para ver si se ha visitado anteriormente. Devuelve verdadero si ha sido visitado, lo que sugiere que se ha encontrado un bucle.
- La función marca el nodo actual como visitado si ya ha sido visitado cambiando su propiedad 'visitado' a verdadero.
- Luego se verifica el valor de la variable visitada para ver si el nodo actual ha sido visitado anteriormente. Si se ha utilizado antes, debe existir un bucle y la función devuelve verdadero.
- Por último, la función se llama a sí misma con el siguiente nodo de la lista pasando headNode->siguiente como argumento. Recursivamente , esto se lleva a cabo hasta que se encuentra un bucle o se visitan todos los nodos. Significa que la función establece la variable visitada en verdadero si el nodo actual nunca ha sido visitado antes de llamarse recursivamente para el siguiente nodo en la lista vinculada.
- El código construye tres nodos y los une para producir una lista enlazada en el función principal . El método detectLoopLinkedList() luego se invoca en el nodo principal de la lista. El programa produce “ Bucle deducido en lista enlazada ' si detectLoopLinkedList() devuelve verdadero; de lo contrario, genera “ No se detectó ningún bucle en la lista enlazada “.
- Luego, el código inserta un bucle en la lista vinculada al establecer el siguiente puntero del último nodo en el segundo nodo. Luego, dependiendo del resultado de la función, se ejecuta detectLoopLinkedList() de nuevo y produce “ Bucle deducido en lista enlazada ' o ' No se detectó ningún bucle en la lista enlazada .”
Enfoque 4: Uso de Stack
Los bucles en una lista enlazada se pueden encontrar utilizando una pila y el método de 'búsqueda primero en profundidad' (DFS). El concepto fundamental es iterar a través de la lista enlazada, empujando cada nodo a la pila si aún no se ha visitado. Se reconoce un bucle si se vuelve a encontrar un nodo que ya está en la pila.
Aquí hay una breve descripción del procedimiento:
-
- Cree una pila vacía y una variable para registrar los nodos que se han visitado.
- Empuje la lista vinculada a la pila, comenzando en la parte superior. Tome nota de que la cabeza ha sido visitada.
- Empuje el siguiente nodo de la lista a la pila. Agregue una marca de visita a este nodo.
- A medida que recorre la lista, inserte cada nuevo nodo en la pila para indicar que ha sido visitado.
- Verifique si un nodo que se ha visitado previamente está en la parte superior de la pila si se encuentra. Si es así, se ha encontrado un bucle y los nodos de la pila identifican el bucle.
- Extraiga los nodos de la pila y siga recorriendo la lista si no encuentra ningún bucle.
Implementación del programa C++ para el método anterior (Stack)
#incluir
#incluir
utilizando el espacio de nombres estándar;
nodo de estructura {
datos int;
Nodo * próximo;
} ;
// Función para detectar bucle en una lista enlazada
bool detectLoopLinkedList ( Nodo * nodo principal ) {
pila < Nodo *> pila;
Nodo * nodotemp = nodocabeza;
mientras ( nodo temporal ! = NULO ) {
// si el elemento superior de la pila coincide
// el nodo actual y la pila no está vacía
si ( ! pila.vacío ( ) && stack.top ( ) == nodo temporal ) {
devolver verdadero ;
}
apilar.empujar ( nodo temporal ) ;
nodotemp = nodotemp- > próximo;
}
devolver FALSO ;
}
int principal ( ) {
Nodo * headNode = nuevo nodo ( ) ;
Nodo * segundoNodo = nuevo Nodo ( ) ;
Nodo * tercerNodo = nuevo Nodo ( ) ;
headNode- > datos = 1 ;
headNode- > siguiente = segundoNodo;
segundo nodo- > datos = 2 ;
segundo nodo- > siguiente = tercerNodo;
tercer nodo- > datos = 3 ;
tercer nodo- > siguiente = NULO; // sin bucle
si ( detectLoopLinkedList ( nodo principal ) ) {
cout << 'Bucle detectado en lista enlazada' << fin;
} demás {
cout << 'No se detectó bucle en la lista vinculada' << fin;
}
// Crear un bucle
tercer nodo- > siguiente = segundoNodo;
si ( detectLoopLinkedList ( nodo principal ) ) {
cout << 'Bucle detectado en lista enlazada' << fin;
} demás {
cout << 'No se detectó bucle en la lista vinculada' << fin;
}
Producción:
No se detectó bucle en lista enlazada
Bucle detectado en lista enlazada
Explicación:
Este programa utiliza una pila para averiguar si una lista enlazada individualmente tiene un bucle.
- 1. La biblioteca de flujo de entrada/salida y la biblioteca de pila están presentes en la primera línea.
2. El espacio de nombres estándar se incluye en la segunda línea, lo que nos permite acceder a las funciones de la biblioteca de secuencias de entrada/salida sin tener que prefijarlas con 'std::'.
3. La siguiente línea define la estructura Nodo, que consta de dos miembros: un número entero llamado 'datos' y un puntero a otro Nodo llamado 'siguiente'.
4. El encabezado de la lista enlazada es una entrada para el método detectLoopLinkedList(), que se define en la siguiente línea. La función produce un valor booleano que indica si se encontró o no un bucle.
5. Dentro de la función se crean una pila de punteros de nodo llamados 'pila' y un puntero a un nodo llamado 'tempNode' que se inicializa con el valor de headNode.
6. Luego, siempre que tempNode no sea un puntero nulo, ingresamos a un bucle while.
(a) El elemento superior de la pila debe coincidir con el nodo actual para que podamos determinar que no está vacío. Devolvemos verdadero si este es el caso porque se ha encontrado un bucle.
(b) Si la condición antes mencionada es falsa, el puntero del nodo actual se coloca en la pila y tempNode se establece en el siguiente nodo en la lista vinculada.
7. Devolvemos falso después del ciclo while porque no se observó ningún ciclo.
8. Construimos tres objetos Node y los inicializamos en la función main(). Dado que no hay bucle en el primer ejemplo, configuramos los punteros 'siguientes' de cada Nodo correctamente.
Conclusión:
En conclusión, el mejor método para detectar bucles en una lista enlazada depende del caso de uso específico y las restricciones del problema. Hash Table y el algoritmo de búsqueda de ciclos de Floyd son métodos eficientes y se utilizan ampliamente en la práctica. La pila y la recursión son métodos menos eficientes pero más intuitivos.