Esta guía ilustrará cómo utilizar VectorStoreRetrieverMemory utilizando el marco LangChain.
¿Cómo utilizar VectorStoreRetrieverMemory en LangChain?
VectorStoreRetrieverMemory es la biblioteca de LangChain que se puede utilizar para extraer información/datos de la memoria utilizando las tiendas de vectores. Los almacenes de vectores se pueden utilizar para almacenar y administrar datos para extraer de manera eficiente la información de acuerdo con el mensaje o consulta.
Para conocer el proceso de uso de VectorStoreRetrieverMemory en LangChain, simplemente consulte la siguiente guía:
Paso 1: instalar módulos
Inicie el proceso de uso del recuperador de memoria instalando LangChain usando el comando pip:
pip instalar cadena larga
Instale los módulos FAISS para obtener los datos mediante la búsqueda de similitud semántica:
pip instala faiss-gpu 
Instale el módulo chromadb para usar la base de datos Chroma. Funciona como almacén de vectores para construir la memoria del recuperador:
pip instalar cromadb 
Se necesita instalar otro módulo tiktoken que se puede utilizar para crear tokens convirtiendo datos en fragmentos más pequeños:
instalar pip tiktoken 
Instale el módulo OpenAI para usar sus bibliotecas para crear LLM o chatbots usando su entorno:
instalación de pip en openai 
Configurar el entorno en el IDE de Python o en el cuaderno usando la clave API de la cuenta OpenAI:
importar túimportar conseguir pase
tú . alrededor de [ 'OPENAI_API_KEY' ] = conseguir pase . conseguir pase ( 'Clave API de OpenAI:' )
Paso 2: importar bibliotecas
El siguiente paso es obtener las bibliotecas de estos módulos para usar el recuperador de memoria en LangChain:
de cadena larga. indicaciones importar Plantilla de avisode fecha y hora importar fecha y hora
de cadena larga. llms importar AbiertoAI
de cadena larga. incrustaciones . abierto importar Incrustaciones de OpenAI
de cadena larga. cadenas importar Cadena de conversación
de cadena larga. memoria importar VectorTiendaRetrieverMemoria
Paso 3: Inicializando Vector Store
Esta guía utiliza la base de datos Chroma después de importar la biblioteca FAISS para extraer los datos usando el comando de entrada:
importar faissde cadena larga. tienda de documentos importar InMemoryDocstore
#importación de bibliotecas para configurar las bases de datos o almacenes de vectores
de cadena larga. vectorestiendas importar FAISS
#crea incrustaciones y textos para almacenarlos en las tiendas de vectores
tamaño_incrustación = 1536
índice = faiss. ÍndicePlanoL2 ( tamaño_incrustación )
incrustar_fn = Incrustaciones de OpenAI ( ) . embed_query
tienda de vectores = FAISS ( incrustar_fn , índice , InMemoryDocstore ( { } ) , { } )
Paso 4: Construir un Retriever respaldado por una tienda de vectores
Construye la memoria para almacenar los mensajes más recientes de la conversación y obtener el contexto del chat:
perdiguero = tienda de vectores. como_retriever ( buscar_kwargs = dictar ( k = 1 ) )memoria = VectorTiendaRetrieverMemoria ( perdiguero = perdiguero )
memoria. guardar_contexto ( { 'aporte' : 'Me gusta comer pizza' } , { 'producción' : 'fantástico' } )
memoria. guardar_contexto ( { 'aporte' : 'Soy bueno en el fútbol' } , { 'producción' : 'OK' } )
memoria. guardar_contexto ( { 'aporte' : 'No me gusta la política' } , { 'producción' : 'seguro' } )
Pruebe la memoria del modelo utilizando la entrada proporcionada por el usuario con su historial:
imprimir ( memoria. variables_memoria_carga ( { 'inmediato' : '¿Qué deporte debo ver?' } ) [ 'historia' ] ) 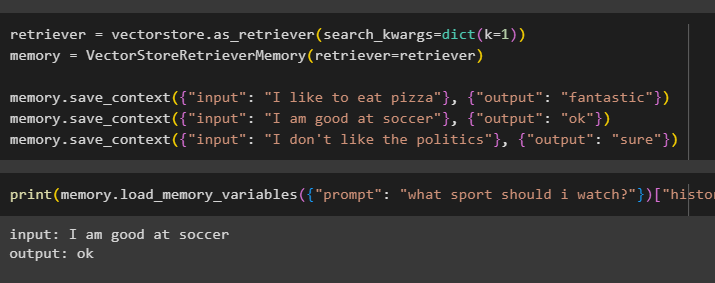
Paso 5: usar Retriever en cadena
El siguiente paso es el uso de un recuperador de memoria con las cadenas construyendo el LLM usando el método OpenAI() y configurando la plantilla de solicitud:
llm = AbiertoAI ( temperatura = 0 )_PLANTILLA PREDETERMINADA = '''Es una interacción entre un humano y una máquina.
El sistema produce información útil con detalles usando el contexto.
Si el sistema no tiene la respuesta para usted, simplemente dice no tengo la respuesta
Información importante de la conversación:
{historia}
(si el texto no es relevante no lo uses)
Charla actual:
Humano: {entrada}
AI:'''
INMEDIATO = Plantilla de aviso (
variables_entrada = [ 'historia' , 'aporte' ] , plantilla = _PLANTILLA PREDETERMINADA
)
#configurar ConversationChain() usando los valores de sus parámetros
conversación_con_resumen = Cadena de conversación (
llm = llm ,
inmediato = INMEDIATO ,
memoria = memoria ,
verboso = Verdadero
)
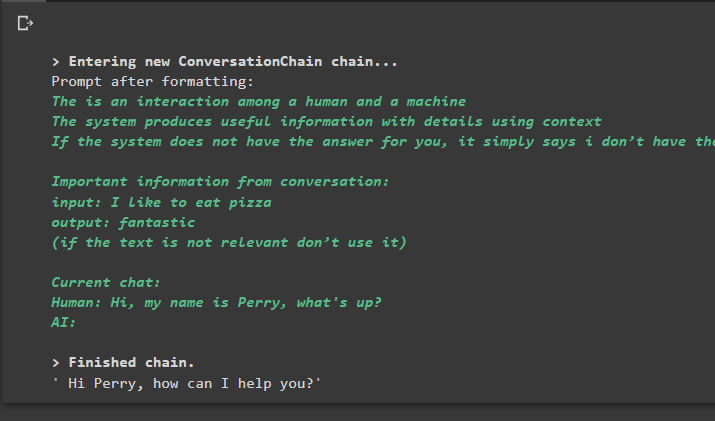
conversación_con_summary. predecir ( aporte = 'Hola, mi nombre es Perry, ¿qué pasa?' )
Producción
Al ejecutar el comando se ejecuta la cadena y se muestra la respuesta proporcionada por el modelo o LLM:
Continúe con la conversación utilizando el mensaje basado en los datos almacenados en el almacén de vectores:
conversación_con_summary. predecir ( aporte = '¿Cuál es mi deporte favorito?' ) 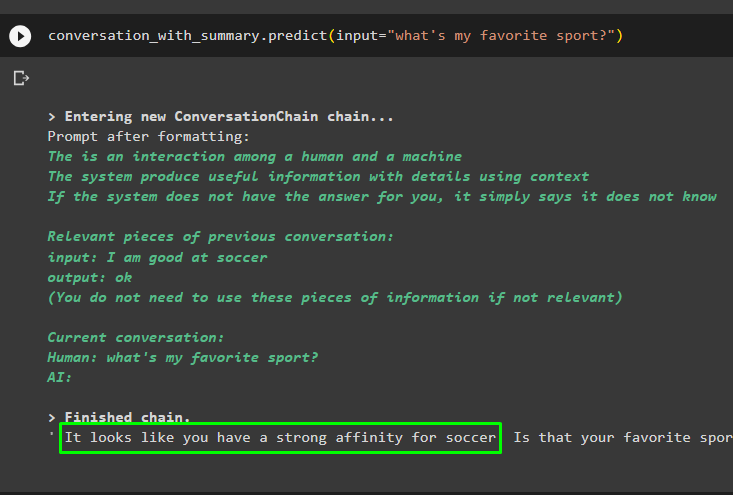
Los mensajes anteriores se almacenan en la memoria del modelo, que el modelo puede utilizar para comprender el contexto del mensaje:
conversación_con_summary. predecir ( aporte = '¿Cuál es mi comida favorita?' ) 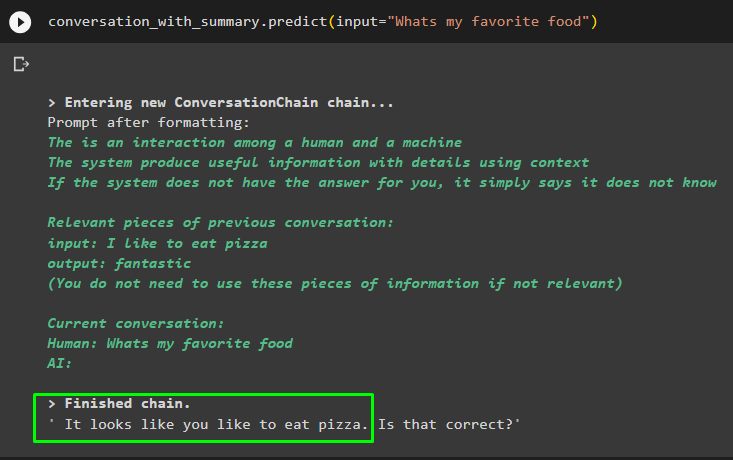
Obtenga la respuesta proporcionada al modelo en uno de los mensajes anteriores para comprobar cómo está funcionando el recuperador de memoria con el modelo de chat:
conversación_con_summary. predecir ( aporte = '¿Cuál es mi nombre?' )El modelo ha mostrado correctamente la salida utilizando la búsqueda de similitud a partir de los datos almacenados en la memoria:
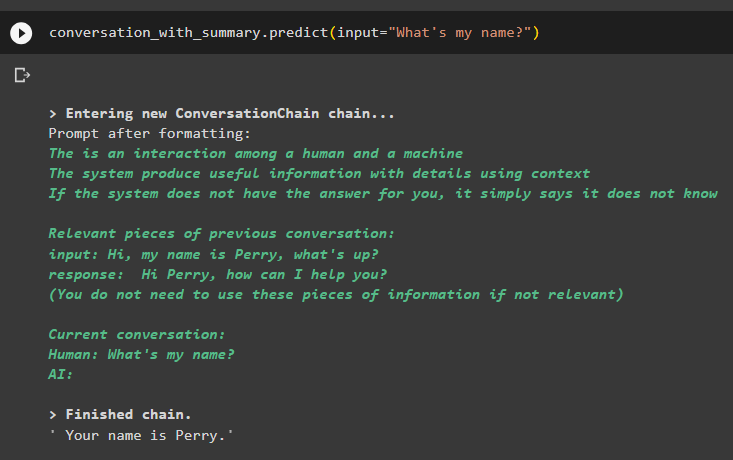
Se trata de utilizar el recuperador de tienda de vectores en LangChain.
Conclusión
Para utilizar el recuperador de memoria basado en un almacén de vectores en LangChain, simplemente instale los módulos y marcos y configure el entorno. Después de eso, importe las bibliotecas de los módulos para crear la base de datos usando Chroma y luego configure la plantilla de solicitud. Pruebe el recuperador después de almacenar datos en la memoria iniciando la conversación y haciendo preguntas relacionadas con los mensajes anteriores. Esta guía ha detallado el proceso de uso de la biblioteca VectorStoreRetrieverMemory en LangChain.