Cuando se trabaja en el entorno de la línea de comandos, es esencial tener una sólida comprensión de los diversos comandos disponibles para administrar archivos, directorios y otros datos de manera efectiva. Uno de esos comandos es el comando 'awk'. awk es una poderosa utilidad utilizada para procesar y manipular archivos de texto en el entorno Unix/Linux. Este artículo explicará qué es el comando 'awk' y las formas de usarlo de manera efectiva.
¿Qué es el comando 'awk'?
El comando 'awk' es una poderosa herramienta para manipular y procesar archivos de texto en entornos Unix/Linux. Se puede utilizar para realizar tareas como la comparación de patrones, el filtrado, la clasificación y la manipulación de datos. awk se utiliza principalmente para procesar y manipular datos de forma estructurada.
Cómo usar el comando awk
awk es una herramienta de línea de comandos que se puede utilizar de varias formas. Se puede invocar directamente desde la línea de comandos o se puede usar junto con un script de shell. Aquí hay algunos ejemplos de cómo usar awk:
Ejemplo 1: contar el número de líneas en un archivo
Para contar el número de líneas en un archivo, puede usar la siguiente sintaxis awk:
awk 'FIN{imprimir NR}' < nombre-archivo.txt >
Aquí, 'NR' es una variable integrada que contiene el número de registros (líneas) procesados por awk. La palabra clave 'FIN' le dice a awk que ejecute este comando después de que se hayan procesado todas las líneas del archivo. Aquí he creado un archivo de texto con fines ilustrativos y luego utilicé la sintaxis anterior en un script de shell que es:
#!/bin/bash
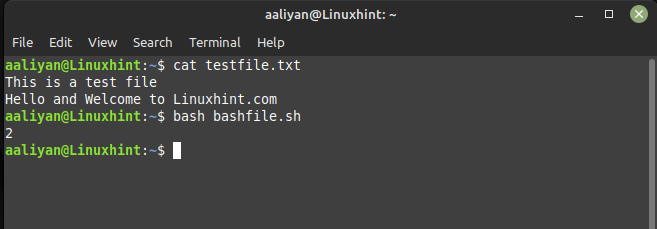
awk 'FIN{imprimir NR}' archivo de prueba.txt
El archivo de texto que creé tiene dos líneas y cuando se usa el comando awk, la salida muestra 2, puede ver el archivo de texto que creé en la imagen a continuación:
Ejemplo 2: filtrado de datos
El awk se puede usar para filtrar datos según criterios específicos y aquí está la sintaxis que se debe usar para tal propósito:
awk '!/
Por ejemplo, puede utilizar el siguiente comando para filtrar todas las líneas de un archivo que contenga la palabra 'Hola'.
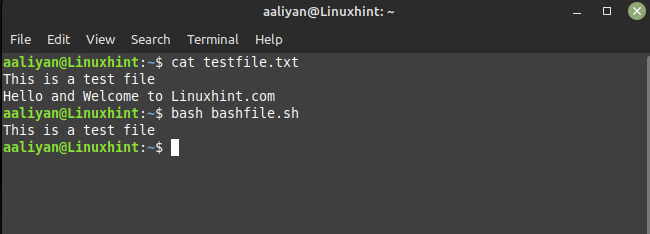
awk '!/Hola/' archivo de prueba.txt
En este ejemplo, el '!' El símbolo niega la búsqueda de expresiones regulares, por lo que se imprimirán todas las líneas que no contengan la palabra 'Hola'. He usado el mismo archivo de texto que en el ejemplo anterior, así que aquí está el resultado del script anterior:
Ejemplo 3: Extracción de campos específicos
awk también se puede usar para extraer campos específicos de un archivo. Por ejemplo, si tiene un archivo que contiene una lista de nombres y direcciones y desea extraer solo los nombres, puede usar el siguiente comando:
awk '{imprimir $
Aquí como ilustración, imprimí el primer campo del mismo archivo de texto y “$1” representa el primer campo en cada línea del archivo. El comando 'imprimir' le dice a awk que imprima solo ese campo.
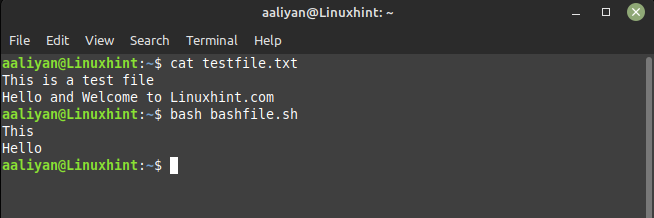
awk '{imprimir $1}' archivo de prueba.txt
En el archivo de texto, la primera entrada de la primera línea es 'Esto' y la primera entrada de la segunda línea es 'Hola', así que aquí está el resultado del código dado:
Conclusión
El comando awk es una poderosa herramienta que se utiliza para manipular y procesar archivos de texto. Le permite realizar varias operaciones en archivos de texto, como imprimir columnas específicas, buscar patrones y calcular sumas. Al dominar los conceptos básicos de awk, puede optimizar su flujo de trabajo y convertirse en un usuario de Linux o Unix más eficiente y efectivo.