En este artículo, discutiremos cómo asignar DIFERENTE memoria a través del botón “ pytorch_cuda_alloc_conf ' método.
¿Qué es el método 'pytorch_cuda_alloc_conf' en PyTorch?
Fundamentalmente, el “ pytorch_cuda_alloc_conf ”es una variable de entorno dentro del marco de PyTorch. Esta variable permite la gestión eficiente de los recursos de procesamiento disponibles, lo que significa que los modelos se ejecutan y producen resultados en el menor tiempo posible. Si no se hace correctamente, el “ DIFERENTE ”La plataforma de cálculo mostrará el “ sin memoria ”error y afecta el tiempo de ejecución. Modelos que se van a entrenar con grandes volúmenes de datos o que tienen grandes ' tamaños de lote ” puede producir errores de tiempo de ejecución porque es posible que la configuración predeterminada no sea suficiente para ellos.
El ' pytorch_cuda_alloc_conf 'La variable utiliza lo siguiente' opciones ”para manejar la asignación de recursos:
- nativo : Esta opción utiliza la configuración ya disponible en PyTorch para asignar memoria al modelo en progreso.
- max_split_size_mb : Garantiza que cualquier bloque de código mayor que el tamaño especificado no se divida. Esta es una poderosa herramienta para prevenir “ fragmentación ”. Usaremos esta opción para la demostración de este artículo.
- roundup_power2_divisions : Esta opción redondea el tamaño de la asignación al “ más cercano poder de 2 ”División en megabytes (MB).
- roundup_bypass_threshold_mb: Puede redondear el tamaño de la asignación para cualquier solicitud que supere el umbral especificado.
- umbral_recolección_basura : Evita la latencia al utilizar la memoria disponible de la GPU en tiempo real para garantizar que no se inicie el protocolo de recuperación total.
¿Cómo asignar memoria utilizando el método “pytorch_cuda_alloc_conf”?
Cualquier modelo con un conjunto de datos considerable requiere una asignación de memoria adicional mayor que la establecida de forma predeterminada. La asignación personalizada debe especificarse teniendo en cuenta los requisitos del modelo y los recursos de hardware disponibles.
Siga los pasos que se indican a continuación para utilizar el ' pytorch_cuda_alloc_conf ”método en el IDE de Google Colab para asignar más memoria a un modelo complejo de aprendizaje automático:
Paso 1: abre Google Colab
Buscar en Google Colaboratory en el navegador y crear un “ Nuevo cuaderno ”para empezar a trabajar:
Paso 2: configurar un modelo de PyTorch personalizado
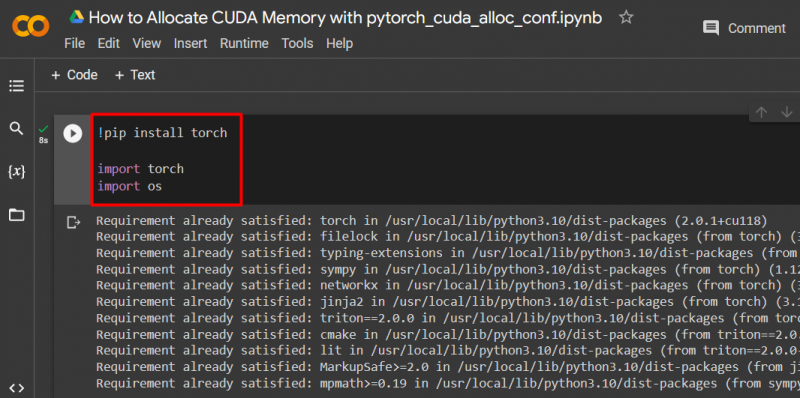
Configure un modelo de PyTorch utilizando el botón ' !pepita 'paquete de instalación para instalar el' antorcha ” biblioteca y el “ importar 'comando para importar' antorcha ' y ' tú ”bibliotecas en el proyecto:
importar antorcha
importarnos
Se necesitan las siguientes bibliotecas para este proyecto:
- Antorcha – Esta es la biblioteca fundamental en la que se basa PyTorch.
- TÚ - El ' Sistema operativo La biblioteca se utiliza para manejar tareas relacionadas con variables de entorno como ' pytorch_cuda_alloc_conf ” así como el directorio del sistema y los permisos de archivos:
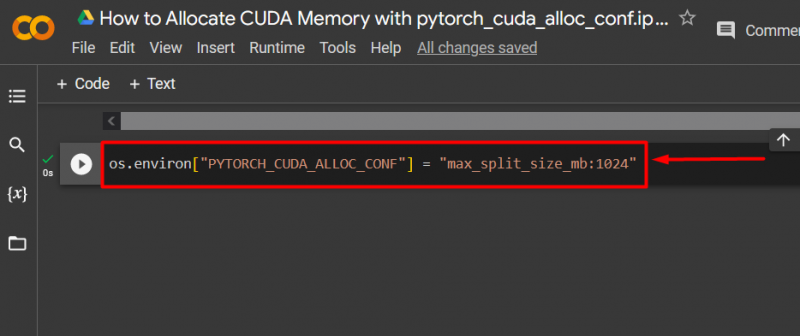
Paso 3: asignar memoria CUDA
Utilizar el ' pytorch_cuda_alloc_conf 'Método para especificar el tamaño máximo de división usando' max_split_size_mb ”:
Paso 4: continúe con su proyecto PyTorch
Después de haber especificado “ DIFERENTE ” asignación de espacio con el “ max_split_size_mb ”, continúe trabajando en el proyecto PyTorch normalmente sin temor al “ sin memoria ' error.
Nota : Puede acceder a nuestro cuaderno de Google Colab en este enlace .
Consejo profesional
Como se mencionó anteriormente, el “ pytorch_cuda_alloc_conf El método 'puede tomar cualquiera de las opciones proporcionadas anteriormente. Utilícelos según los requisitos específicos de sus proyectos de aprendizaje profundo.
¡Éxito! Acabamos de demostrar cómo utilizar el “ pytorch_cuda_alloc_conf 'Método para especificar un' max_split_size_mb ”para un proyecto PyTorch.
Conclusión
Utilizar el ' pytorch_cuda_alloc_conf 'Método para asignar memoria CUDA utilizando cualquiera de sus opciones disponibles según los requisitos del modelo. Cada una de estas opciones está destinada a aliviar un problema de procesamiento particular dentro de los proyectos de PyTorch para lograr mejores tiempos de ejecución y operaciones más fluidas. En este artículo, hemos mostrado la sintaxis para utilizar ' max_split_size_mb Opción para definir el tamaño máximo de la división.