El elemento más crucial de la estructura de datos es la cola. La cola de estructura de datos 'primero en entrar, primero en salir', que es la base para el multiprocesamiento de Python, es comparable. Se proporcionan colas a la función de proceso para permitir que el proceso recopile los datos. El primer elemento de datos que se elimina de la cola es el primer elemento que se ingresa. Utilizamos el método 'put ()' de la cola para agregar los datos a la cola y su método 'get ()' para recuperar los datos de la cola.
Ejemplo 1: uso del método Queue() para crear una cola de multiprocesamiento en Python
En este ejemplo, creamos una cola de multiprocesamiento en Python utilizando el método 'queue()'. El multiprocesamiento se refiere al uso de una o más CPU en un sistema para realizar dos o más procesos simultáneamente. El multiprocesamiento, un módulo construido en Python, facilita el cambio entre procesos. Debemos estar familiarizados con la propiedad del proceso antes de trabajar con multiprocesamiento. Somos conscientes de que la cola es un componente crucial del modelo de datos. La cola de datos estándar, que se basa en la idea de 'primero en entrar, primero en salir', y el multiprocesamiento de Python son contrapartes exactas. En general, la cola almacena el objeto de Python y es crucial para la transferencia de datos entre tareas.
La herramienta 'spyder' se usa para implementar la secuencia de comandos de Python presente, así que simplemente comencemos. Primero debemos importar el módulo de multiprocesamiento porque estamos ejecutando el script de multiprocesamiento de Python. Hicimos esto importando el módulo de multiprocesamiento como 'm'. Usando la técnica “m.queue()”, invocamos el método de multiprocesamiento “queue()”. Aquí, creamos una variable llamada 'cola' y colocamos el método 'cola()' de multiprocesamiento en ella. Como sabemos que la cola almacena elementos en un orden de 'primero en entrar, primero en salir', el elemento que agregamos primero se elimina primero. Después de iniciar la cola de multiprocesamiento, llamamos al método 'imprimir()', pasando la declaración 'Hay una cola de multiprocesamiento' como argumento para mostrarlo en la pantalla. Luego, debido a que almacenamos la cola construida en esta variable, imprimimos la cola pasando la variable 'cola' entre paréntesis del método 'imprimir()'.
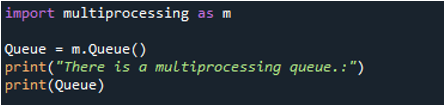
La siguiente imagen muestra que la cola de multiprocesamiento de Python ahora está construida. La declaración de impresión se muestra primero. Una vez que esta cola de multiprocesamiento se construye en la dirección de memoria designada, se puede usar para transferir los distintos datos entre dos o más procesos en ejecución.

Ejemplo 2: utilizar el método 'Qsize()' para determinar el tamaño de la cola de multiprocesamiento en Python
Determinamos el tamaño de la cola de multiprocesamiento en este caso. Para calcular el tamaño de la cola de multiprocesamiento, usamos el método “qsize()”. La función “qsize()” devuelve el tamaño real de la cola de multiprocesamiento de Python. En otras palabras, este método proporciona el número total de elementos en una cola.
Comencemos por importar el módulo de multiprocesamiento de Python como 'm' antes de ejecutar el código. Luego, usando el comando “m.queue()”, invocamos la función de multiprocesamiento “queue()” y ponemos el resultado en la variable “Queue”. Luego, utilizando el método “put()”, agregamos los elementos a la cola en la siguiente línea. Este método se utiliza para agregar los datos a una cola. Por lo tanto, llamamos a 'Cola' con el método 'put ()' y proporcionamos los números enteros como su elemento entre paréntesis. Los números que sumamos son “1”, “2”, “3”, “4”, “5”, “6” y “7” usando las funciones “put()”.
Además, usando 'Cola' para obtener el tamaño de la cola de multiprocesamiento, llamamos a 'qsize()' con la cola de multiprocesamiento. Luego, en la variable 'resultado' recién formada, guardamos el resultado del método 'qsize()'. Después de eso, llamamos al método 'print()' y pasamos la declaración 'El tamaño de la cola de multiprocesamiento es' como su parámetro. A continuación, llamamos a la variable 'resultado' en la función 'imprimir ()' ya que el tamaño se guarda en esta variable.
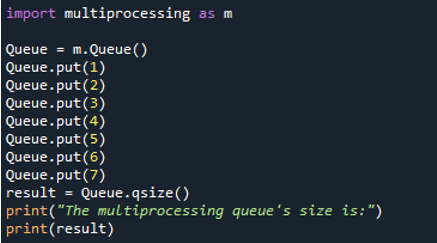
La imagen de salida tiene el tamaño que se muestra. Como usamos la función 'put()' para agregar siete elementos a la cola de multiprocesamiento y la función 'qsize()' para determinar el tamaño, se muestra el tamaño '7' de la cola de multiprocesamiento. La declaración de entrada 'el tamaño de la cola de multiprocesamiento' se muestra antes del tamaño.

Ejemplo 3: Usar el método “Put()” y “Get()” en la cola de multiprocesamiento de Python
En este ejemplo se utilizan los métodos de cola 'put()' y 'get()' de la cola de multiprocesamiento de Python. Desarrollamos dos funciones definidas por el usuario en este ejemplo. En este ejemplo, definimos una función para crear un proceso que produzca '5' enteros aleatorios. También usamos el método 'put ()' para agregarlos a una cola. El método 'put ()' se utiliza para colocar los elementos en la cola. Luego, para recuperar los números de la cola y devolver sus valores, escribimos otra función y la llamamos durante el procedimiento. Usamos la función “get()” para recuperar los números de la cola ya que este método se usa para recuperar los datos de la cola que insertamos usando el método “put()”.
Empecemos a implementar el código ahora. Primero, importamos las cuatro bibliotecas que componen este script. Primero importamos 'dormir' del módulo de tiempo para retrasar la ejecución durante un tiempo medido en segundos, seguido de 'aleatorio' del módulo aleatorio que se usa para generar números aleatorios, luego 'proceso' de multiprocesamiento porque este código crea un proceso y, por último, la “cola” de multiprocesamiento. Al construir inicialmente una instancia de clase, se puede usar la cola. Por defecto, esto establece una cola infinita o una cola sin tamaño máximo. Al establecer la opción de tamaño máximo en un número mayor que cero, es posible realizar una creación con una restricción de tamaño.
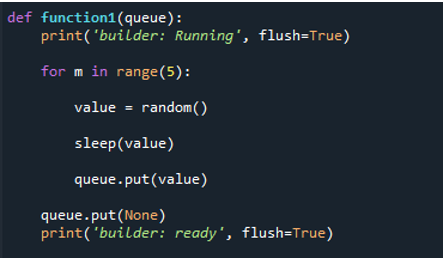
Definimos una función. Luego, dado que esta función está definida por el usuario, le damos el nombre 'función1' y le pasamos el término 'cola' como argumento. A continuación, invocamos la función 'imprimir ()', pasándole las declaraciones 'constructor: En ejecución', 'vaciar' y 'Verdadero' del objeto. La función de impresión de Python tiene una opción única llamada vaciado que le permite al usuario elegir si almacenar o no en búfer esta salida. El siguiente paso es generar la tarea. Para hacer esto, usamos 'for' y creamos la variable 'm' y establecemos el rango en '5'. Luego, en la siguiente línea, use 'random()' y almacene el resultado en la variable que creamos, que es 'valor'. Esto indica que la función ahora termina sus cinco iteraciones, y cada iteración crea un número entero aleatorio de 0 a 5.
Luego, en el siguiente paso, llamamos a la función 'dormir ()' y pasamos el argumento 'valor' para retrasar la porción durante una cierta cantidad de segundos. Luego, llamamos a la 'cola' con el método 'put ()' para agregar esencialmente el valor a la cola. Luego se informa al usuario que no hay más trabajo por hacer invocando el método 'queue.put ()' una vez más y pasando el valor 'Ninguno'. Luego, ejecutamos el método 'print()', pasamos la declaración 'builder: ready' junto con 'flush' y lo configuramos en 'True'.
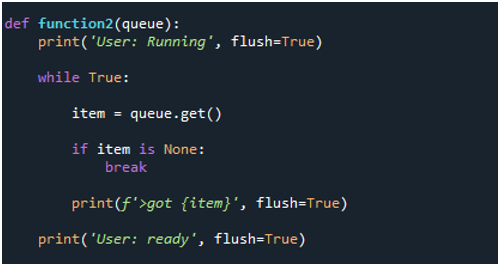
Ahora definimos una segunda función, 'función2', y le asignamos la palabra clave 'cola' como su argumento. Luego, llamamos a la función 'imprimir ()' mientras pasamos los estados del informe 'Usuario: en ejecución' y 'vaciar', que se establece en 'Verdadero'. Comenzamos la operación de 'función2' usando la condición while true para sacar los datos de la cola y ponerlos en la variable 'elemento' recién creada. Luego, usamos la condición 'if', 'item is None', para interrumpir el ciclo si la condición es verdadera. Si no hay ningún artículo disponible, se detiene y le pide uno al usuario. La tarea detiene el bucle y finaliza en este caso si el elemento que se obtiene del valor es nulo. Luego, en el siguiente paso, llamamos a la función 'print()' y le proporcionamos el informe 'Usuario: listo' y los parámetros 'flush=True'.
Luego, ingresamos al proceso principal usando el “If-name = main_”. Creamos una cola llamando al método 'queue()' y almacenándolo en la variable 'queue'. A continuación, creamos un proceso llamando a la función de usuario 'función2'. Para esto, llamamos a la clase 'proceso'. Dentro de él, pasamos el 'objetivo = función2' para llamar a la función en el proceso, pasamos el argumento 'cola' y lo almacenamos en la variable 'Usuario_proceso'. Luego, el proceso comienza llamando al método 'start ()' con la variable 'User_ proceso'. Luego repetimos el mismo procedimiento para llamar a la 'función 1' en el proceso y ponerlo en la variable 'proceso de construcción'. Luego, llamamos a los procesos con el método 'join()' para esperar la ejecución.
Ahora que se presenta, puede ver las declaraciones de ambas funciones en la salida. Muestra los elementos que agregamos usando los métodos 'put()' y 'get()' usando los métodos 'get()', respectivamente.
Conclusión
Aprendimos sobre la cola de multiprocesamiento de Python en este artículo. Utilizamos las ilustraciones dadas. Al principio, describimos cómo crear una cola en el multiprocesamiento de Python usando la función queue(). Luego, usamos el método 'qsize()' para determinar el archivo . También usamos los métodos put() y get() de la cola. La clase de sueño del módulo de tiempo y la clase aleatoria del módulo aleatorio se analizaron en el último ejemplo.